Tự triển khai model với Azure Machine Learning
Trong bài viết về giải pháp social listening Lison, mình đã nhắc đến AzureML như một dịch vụ nòng cốt của hệ thống. Bài viết lần này sẽ hướng dẫn chi tiết cách sử dụng AzureML để triển khai model phân tích cảm xúc trong hệ thống.

Mình đã từng giới thiệu về AzureML trong hệ thống social listening mang tên Lison. AzureML là một dịch vụ cung cấp môi trường cho việc nghiên cứu và phát triển dự án AI của Azure. AzureML có khả năng thực hiện những tác vụ như train, deploy, automate, manage và track model.
Dù chuyên môn của mình không hẳn là AI, nhưng mình cho rằng kỹ sư phần mềm chúng ta ít nhiều cũng cần có chút hiểu biết về AI để có thể nắm bắt được xu hướng cũng như tiếp cận nhiều cơ hội hơn.
Thực tế, AI không chỉ toàn là nghiên cứu và “chế tạo” model. Việc triển khai model và tích hợp với những component khác của hệ thống (serving model) cũng là công việc rất “khoai” và quan trọng. Dù để đạt trình bậc thầy trong việc serving model cần nhiều thời gian để nghiên cứu học hỏi, nhưng việc bắt đầu “làm thử” thì lại không khó chút nào. Đặc biệt khi giờ đây các cloud provider đã hỗ trợ rất nhiều để đơn giản hóa, thúc đẩy nhanh chóng quá trình này.
Trong bài viết hôm nay, mình sẽ hướng dẫn từng bước về cách thức triển khai custom model bằng AzureML và tích hợp với Azure Stream Analytics để làm một processing pipeline có khả năng ứng dụng vào nhiều hệ thống. Mình sẽ sử dụng một model phân tích cảm xúc của người đăng trạng thái (status), đưa ra kết quả là positive (tích cực) hoặc negative (tiêu cực). Nhiệm vụ của mình sẽ là triển khai AI model này bằng AzureMLđể publish API cho các component khác sử dụng.
Thực hiện
Mình chuẩn bị các file sau đây:
- svm.pkl
- tfidf_vect.pkl
- score.py: python file sử dụng các model trên để xử lý và xuất ra kết quả cuối cùng (cảm xúc tiêu cực/tích cực)
Cuối cùng là tạo service AzureML.
Chi phí phát sinh của AzureML gồm compute và storage mà bạn đã dùng. Bạn có thể xem chi tiết qua bài viết về chi phí này.
Bạn có thể thực hiện việc serve model trên AzureML bằng Azure CLI hoặc python code. Mình sẽ chọn dùng Python code vì trực quan hơn, nên mình sẽ tạo một notebook và đặt tên là deployment.ipynb:
Cell 1:
# Check core SDK version number
import azureml.core
print("SDK version:", azureml.core.VERSION)
Cell này để test AzureML SDK. Để thực thi cell này, bạn cần tạo một compute instance (tạo một VM).

Chú ý là với AzureML, bạn sẽ bị thu phí sử dụng compute và storage. Vì vậy, trong quá trình dev, bạn hãy nhớ việc stop/start các compute instance tùy theo nhu cầu sử dụng để tiết kiệm chi phí. Bạn có thể kiểm tra compute trong menu Compute.
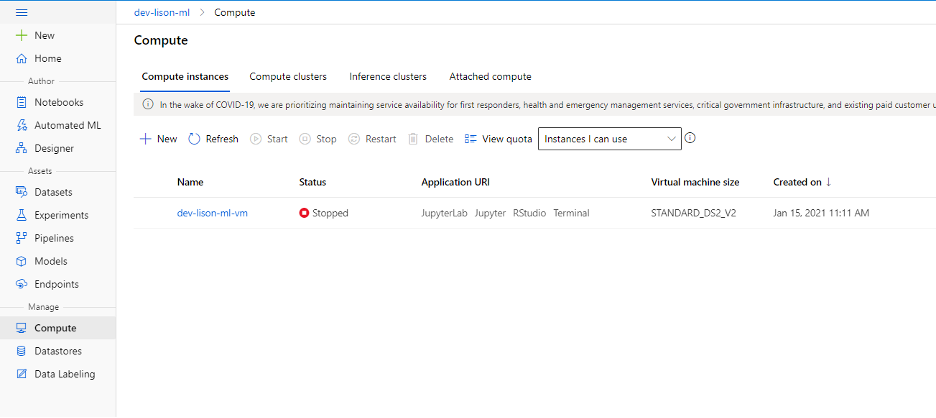
Trong bài viết này, chúng ta sẽ tạo một Compute Instance để thực thi các đoạn deployment script, và một Inference Cluster để serve model như web service.
Cell 2:
from azureml.core import Workspace
ws = Workspace.from_config()
print(ws.name, ws.resource_group, ws.location, ws.subscription_id, sep='\n')
Cell 2 để import Workspace, cần phải login trong bước này.
Cell 3:
from azureml.core.model import Model
# Tip: When model_path is set to a directory, you can use the child_paths parameter to include
# only some of the files from the directory
model = Model.register(model_path = "svm.pkl",
model_name = "svm",
workspace = ws)
model = Model.register(model_path = "tfidf_vect.pkl",
model_name = "tfidf_vect",
workspace = ws)
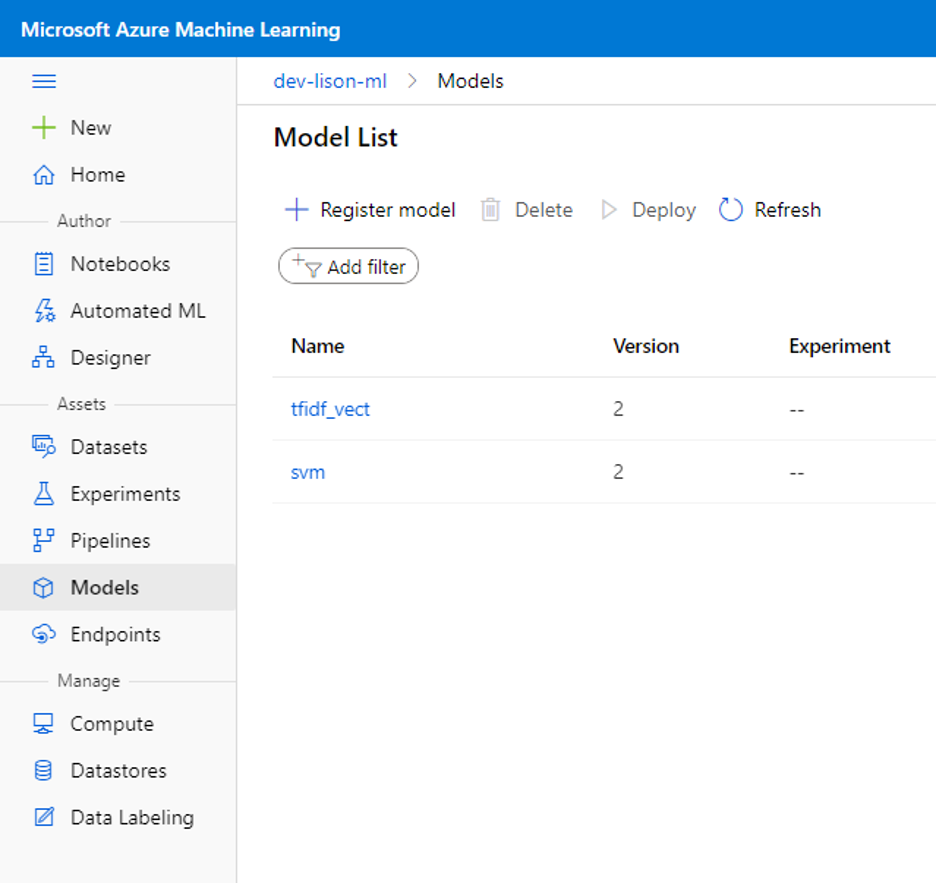
Cell 3 để register model vào AzureML để sử dụng trong score.py. Sau khi thực thi cell này, bạn có thể kiểm tra menu Models để thấy model đã đăng kí và version tương ứng.
Chú ý rằng mỗi khi thực thi cell này, một version mới của model sẽ được đăng kí với AzureML.
Cell 4:
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
# Create the environment
myenv = Environment(name="myenv")
conda_dep = CondaDependencies()
# Define the packages needed by the model and scripts
conda_dep.add_conda_package("numpy")
conda_dep.add_conda_package("pandas")
conda_dep.add_conda_package("scikit-learn==0.22.2.post1")
conda_dep.add_conda_package("nltk")
# You must list azureml-defaults as a pip dependency
conda_dep.add_pip_package("azureml-defaults")
conda_dep.add_pip_package("inference-schema")
# Adds dependencies to PythonSection of myenv
myenv.python.conda_dependencies=conda_dep
inference_config = InferenceConfig(entry_script="score.py",
environment=myenv)
Như đã giải thích trong đoạn code, cell này để tạo lập môi trường, bao gồm định nghĩa conda package, để thực thi score.py script.
Cell 5:
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute.aks import AksCompute
aks_target = AksCompute(ws,"dev-lison-aks")
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
svm = Model(ws, name='svm')
tfidf_vect = Model(ws, name='tfidf_vect')
service = Model.deploy(ws, 'sentiment-service-v1', [svm, tfidf_vect], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Cell 5 là đoạn code để deploy model trên AKS - Azure Kubernetes Service (target được chọn).
Bạn có thể deploy model lên nhiều môi trường khác nhau, bạn có thể tham khảo tài liệu của Azure để biết thêm chi tiết. Với mỗi deployment target, bạn cần phải điều chỉnh lại nội dung của cell 5 cho tương thích.
Trong ví dụ của mình, mình chọn AKS làm deployment target vì AKS được khuyên dùng cho real-time inference, phù hợp với requirement của mình. Ngoài ra, mình cần publish model thành web service để tích hợp với Stream Analytics mà mình sẽ trình bày trong phần kế tiếp.
Sau cell 5, model đã được published thành endpoint. À mà đây là giả sử bạn đã thực thi được cell 5 thành công nha, vì lúc mình làm, mình đã phải chỉnh đi chỉnh lại “score.py” nhiều lần trước khi publish được.
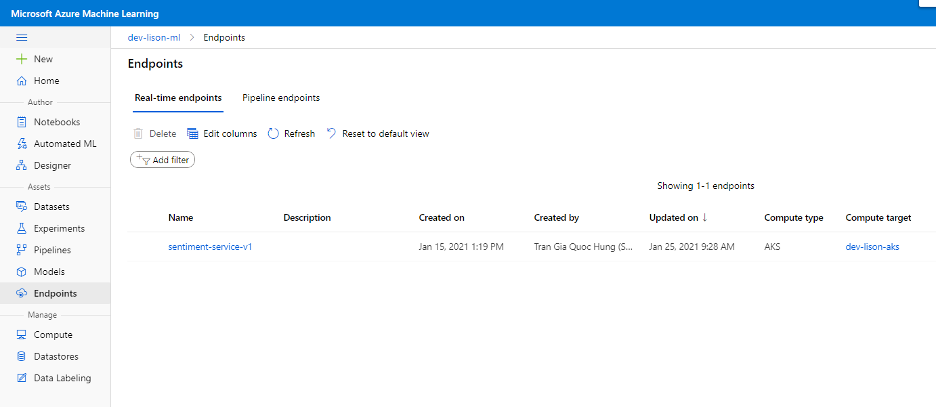
Để kiểm tra việc publish, bạn có thể check trong menu Endpoints để thấy endpoint mới được tạo ra tương ứng với published model.
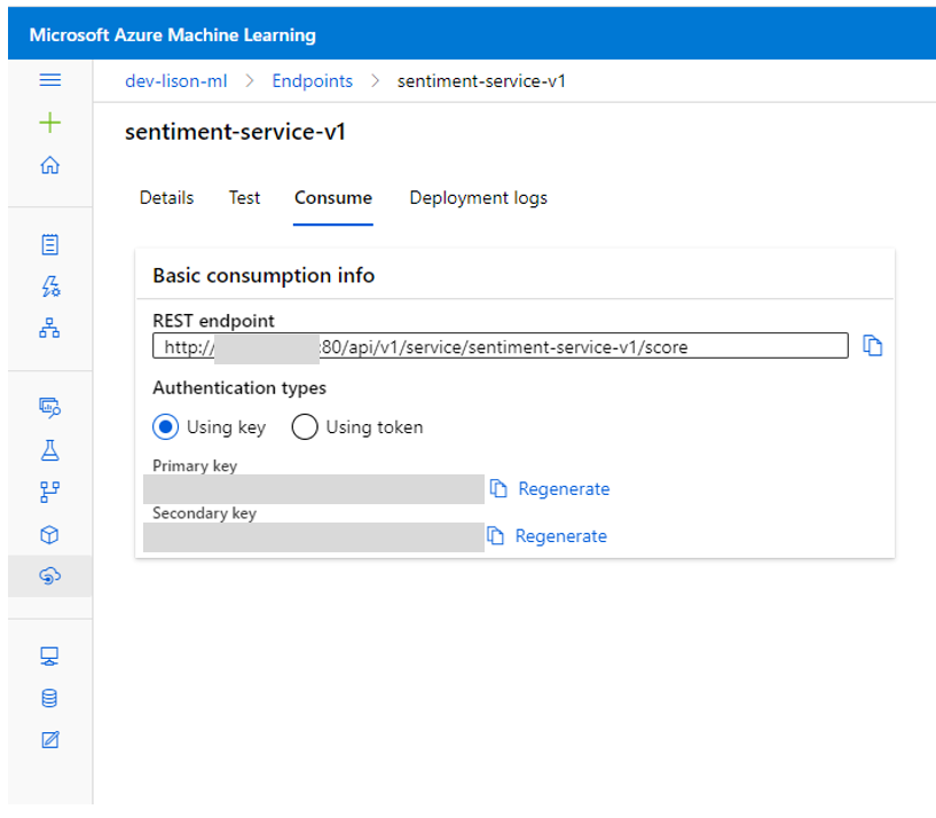
Ta có thể lấy service url, authentication token… trong chi tiết của mục Endpoints.
Ta có thể test url với đoạn script bên dưới:
import requests
import json
scoring_uri = 'http://<ip>:80/api/v1/service/sentiment-service-v1/score'
headers = {'Content-Type':'application/json', "Authorization": "Bearer <token>"}
test_data = json.dumps({"Inputs": ['1 điểm nữa nhân viên rất rất nhiệt tình , vui vẻ',
'bạn nhận oder cực kỳ thiếu tế_nhị']})
#test_data = 'today is fun'
response = requests.post(scoring_uri, data=test_data, headers=headers)
print(response.status_code)
print(response.elapsed)
print(response.text)
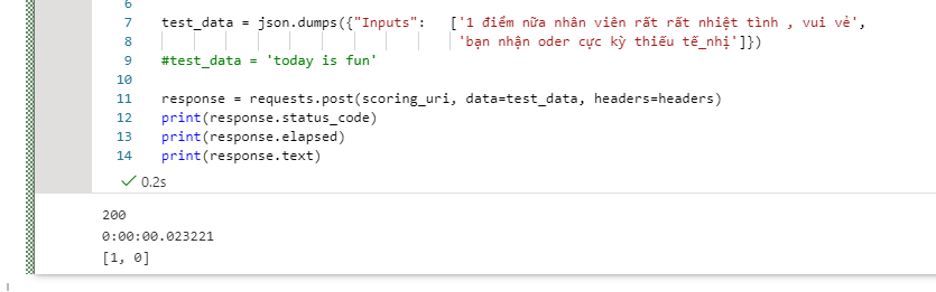
Như vậy, mình đã serve model thành web service thành công.
Tích hợp với Azure Stream Analytics
Để tích hợp với Azure Stream Analytics, cần điều chỉnh file score.py như bên dưới:
…
from inference_schema.schema_decorators import input_schema, output_schema
from inference_schema.parameter_types.numpy_parameter_type import NumpyParameterType
….
input_sample = np.array(['Sample test'])
output_sample = np.array([1])
@input_schema('Inputs', NumpyParameterType(input_sample))
@output_schema(NumpyParameterType(output_sample))
def run(Inputs):
….
Tại bước này thì chúng ta cần chú ý là:
- Cả input và output parameter cần là np.array
- Parameter đầu tiên của input_schema cần tên là “Inputs”
Thêm một lưu ý nữa: Những điểm trên là kết quả sau việc tìm đọc sample và thử-sai của mình, có thể trong tương lai sẽ không còn đúng nữa. Nếu có tài liệu chính thức nào về việc cấu hình parameter để tích hợp với Azure Stream Analytics, bạn hãy trao đổi với mình nhé.
Với điều chỉnh trên và update lại service, AzureML đã có thể tích hợp với Azure Stream Analytics như một function.
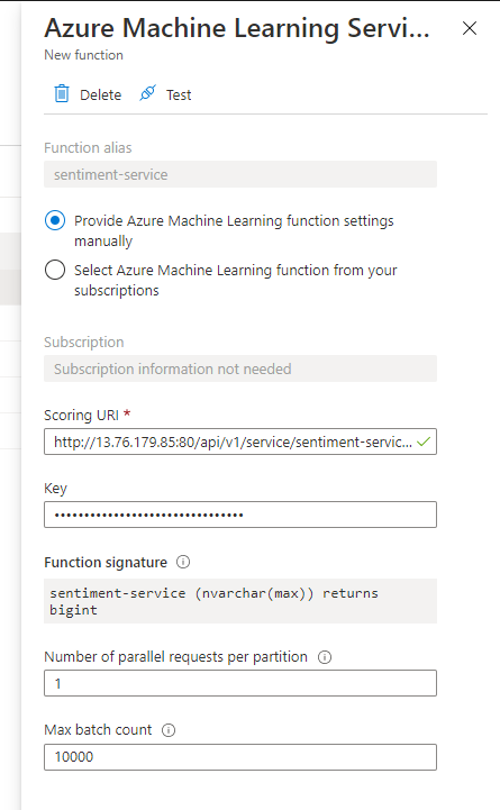
Đánh giá
Mình tự đánh giá có 2 điều khó khăn khi thực hiện công việc này.
Đầu tiên là cần tìm hiểu, nghiên cứu nhiều. Để hiểu được ý nghĩa mỗi đoạn script trong quá trình triển khai và cô đọng thành bài viết này, mình đã đọc khá nhiều tài liệu, bài viết, và tham khảo sample. Tuy nhiên, sau cùng mình nghĩ tài liệu chính thức về AzureML vẫn là phù hợp nhất để học rõ về service này.
Điểm khó tiếp theo là tích hợp với Azure Stream Analytics. Để Stream Analytics có thể “thấy” được scoring API, mình đã phải điều chỉnh nội dung của “score.py” và format của input và output khá nhiều lần. Các tài liệu không nói rõ chi tiết về phần này lắm.
Về ưu điểm, mình thấy là:
All-in-one service: bạn có thể làm hầu hết các công việc liên quan đến AI với AzureML. Nhưng dù đây là service rất tiện dụng trong dự án AI, bạn cũng cần học cách quản lí chi phí để sử dụng hiệu quả.
Dễ dàng sử dụng: tuy mình gặp khó khăn trong việc host model bằng AzureML lần đầu tiên, nhưng khi đã hiểu được service này thì việc cập nhật model, host model mới hoặc thiết đặt CI/CD pipeline cho dự án AI đã trở nên dễ dàng hơn.
Khả năng tích hợp với những Azure service khác: “anh em” một nhà thì tất nhiên là dễ “nói chuyện” với nhau rồi, bạn có thể tham khảo thêm tài liệu này để biết thêm chi tiết.
Qua bài viết này, mình đã demo việc serving custom model bằng AzureML từ việc tự nghiên cứu, đọc hiểu tài liệu. Ban đầu bạn sẽ thấy rắc rối vì nhiều thông tin, nhưng khi bắt tay vào làm thì sẽ thấy cũng khá thú vị đó. Hy vọng bài viết này giúp bạn có cảm hứng để bắt đầu bước vào thế giới AI.

