Tự động hóa Machine Learning bằng thư viện EvalML
EvalML là AutoML mã nguồn mở được viết bằng Python có thể tự động đánh giá các pipeline ML nào phù hợp với tập data xác định. EvalML gần đây đã thêm một số tính năng mới và sửa đổi một số thuật toán để vận hành pipeline.

Trước đây, đối với một newbie khi mới bước vào lĩnh vực ML thì rất khó để tạo ra một mô hình ML chính xác, nhưng giờ đây nhờ có thư viện AutoML mà những người mới bắt đầu có thể tạo model chính xác và đỡ mất công sức hơn. Các thư viện AutoML lấy dữ liệu làm đầu vào và cung cấp một model với độ chính xác tốt hơn với dữ liệu đã cho.
Với AutoML, chúng ta hoàn toàn có thể đánh giá được model tốt nhất để sử dụng hoặc thay thế nó với một model khác. Bạn thậm chí có thể tự phát triển và vận hành model của chính bạn mà không cần bất kỳ kĩ năng về khoa học dữ liệu (data science). Để thực hành với AutoML bạn nên có kiến thức căn bản về ML. Trong bài viết hôm nay chúng ta sẽ nói về thư viện AutoML là EvalML cùng một số cập nhật mới của thư viện này.
Thư viện EvalML

EvalML là AutoML mã nguồn mở được viết bằng Python có thể tự động đánh giá xem các pipeline ML nào phù hợp với tập data xác định. Nó có thể tối ưu hóa các pipeline ML bằng cách sử dụng các hàm mục tiêu (objective functions) cụ thể. EvalML có thể tự động thực hiện lựa chọn các tính năng tiêu biểu, model, điều chỉnh các siêu tham số (hyper-parameter), kiểm chứng chéo (cross-validation), … Để làm được điều này, nó kết hợp với hai công cụ là Featuretools và Compose. Featuretools là một công cụ giúp tạo các tính năng một cách tự động. Compose là một công cụ tự động cấu trúc các vấn đề về dự đoán và tạo nhãn cho quá trình học có giám sát (supervised learning).

Bằng việc tự động hóa tất cả giai đoạn của quá trình ML, người dùng có thể dễ dàng xác định các vấn đề cần được giải quyết của model trong thời gian nhanh nhất.
Bạn có thể đọc thêm bài viết giới thiệu tính năng của EvalML tại đây.
Tính năng mới
Trong version 0.37.0 được công bố vào ngày 9/11/2021, EvalML đã thêm một số tính năng mới mẻ cũng như sửa đổi một số thuật toán để vận hành pipeline. Mình đã tóm lược một số điểm như bên dưới.
Tìm kiếm Confusion Matrix và thresholds cho Binary Classification Pipelines dựa vào thông số positive và negative trên từng threshold để lựa chọn threshold tốt nhất cho model.
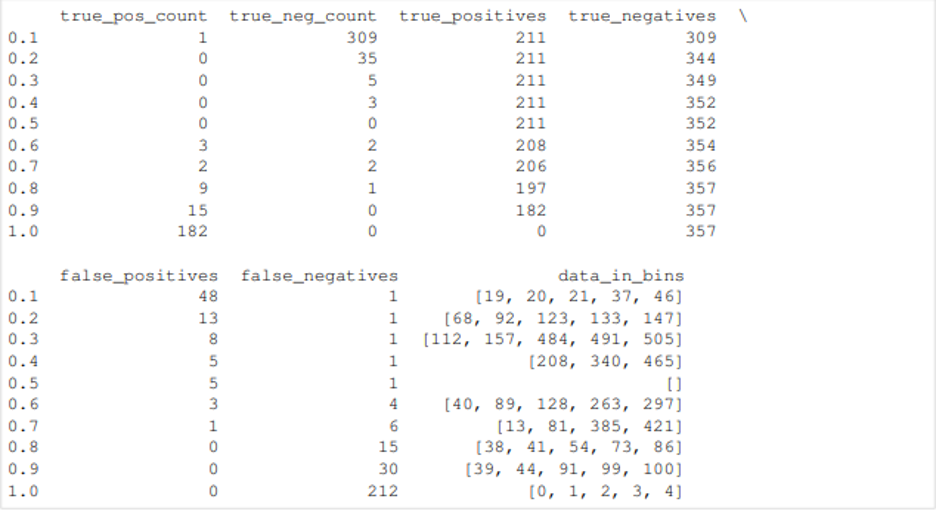
Hỗ trợ chạy trong thời gian dài với tập data lớn cho bài toán multiclassification thông qua thông số allow_long_running_models=True trong class AutoMLSearch (mặc định là False).
- Elastic Net và XGBoost model được hỗ trợ trên 75 multiclass
- CatBoost được hỗ trợ trên 150 multiclass
Sửa đổi DefaultAlgorithm trong pipeline từ Select Columns Transformer sang Drop Columns Transformer.

Hỗ trợ Stacking sau khi đã đánh giá xong tất cả các model để cho ra kết quả cuối cùng. Để kích hoạt Stacking cần phải gắn cờ cho ensembling= True (Mặc định là False).
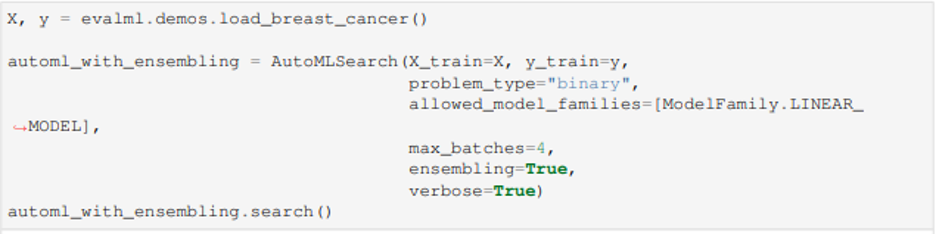

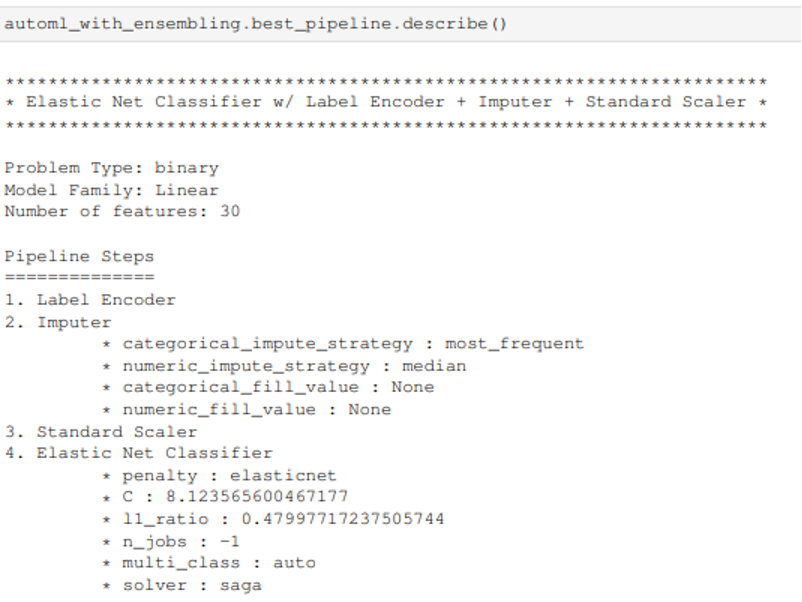
Bên cạnh đó có ta có thể gọi hàm describe() để lấy thông tin chi tiết sau khi train của stacking ensemble pipeline.
Hỗ trợ hàm DelayedFeatureTransformer() để giải quyết vấn đề của times series data trong việc chọn được thời gian trễ trong khoảng xác định.
Cập nhật các thông tin mới nhất về EvalML theo các link sau:

