- Cuộc dịch chuyển từ đám mây xuống thiết bị biên
- Google Gemma 3n: Trợ lý đa dụng cho thiết bị biên
- Kiến trúc & tối ưu hóa NPU
- Qwen3-VL 4B: Mô hình nhỏ cũng biết tư duy
- Kiến trúc DeepStack & Interleaved-MRoPE
- Tư duy hệ thống (System Thinking)
- Moondream 3: Đôi mắt cho thiết bị IoT
- Kiến trúc siêu tối ưu (Compact Vision-Language Architecture)
- Hiệu năng trên thiết bị IoT
- DeepSeek OCR & HunyuanOCR: Cuộc cách mạng số hóa tài liệu
- DeepSeek OCR: Nén quang học ngữ cảnh
- Hunyuan OCR: Sự chính xác tuyệt đối
- Trải nghiệm và hiệu năng thực tế
- Khuyến nghị kỹ thuật
Review các mô hình AI nhỏ sử dụng trên thiết bị cá nhân
Không cần siêu máy tính để tận hưởng AI mạnh mẽ. Các mô hình ngôn ngữ nhỏ (SLM) sẽ tái định nghĩa tốc độ, hiệu suất, và tính khả dụng cho mọi kỹ sư trong kỷ nguyên AI bỏ túi.

Đọc thêm: AI coding 2025: Tự triển khai AI trong tầm tay
Cuộc dịch chuyển từ đám mây xuống thiết bị biên
Trong những năm gần đây, cùng với sự bùng nổ của AI, chúng ta vẫn tin vào triết lý 'càng to càng tốt'. Muốn AI thông minh, đó phải là những mô hình khổng lồ với hàng trăm hoặc thậm chí lên đến hàng nghìn tỷ tham số (Llama 4 Behemoth), chạy trên những 'trang trại' máy chủ đắt đỏ. Nhưng bước sang cuối năm 2024 và đặc biệt là 2025, chúng ta đang chứng kiến một sự đảo chiều chiến lược ngoạn mục: Đưa AI về lại thiết bị cá nhân.
Không cần internet, không lo lộ dữ liệu, và quan trọng nhất là chi phí vận hành cực thấp, trọng tâm sân khấu giờ đây thuộc về các mô hình ngôn ngữ nhỏ (Small Language Model - SLM) cùng với các mô hình AI thị giác (VLM) nhỏ mà có võ.
Bài viết này sẽ phân tích sâu về các đại diện tiêu biểu của làn sóng này, cụ thể bao gồm Google Gemma 3n, Qwen3-VL, Moondream3 cùng với bộ đôi xử lý văn bản DeepSeek OCR/Hunyuan OCR.
Google Gemma 3n: Trợ lý đa dụng cho thiết bị biên
Giữa năm 2025, Google đã tung ra Gemma 3 và biến thể nhỏ gọn Gemma 3n tối ưu cho thiết bị biên. Khác với các thế hệ trước thường tách biệt giữa xử lý văn bản và hình ảnh, Gemma 3 được xây dựng dựa trên kiến trúc Native Multimodal (đa phương tiện nguyên bản) ngay từ khâu pre-training, kế thừa trực tiếp từ Gemini 2.0.

Kiến trúc & tối ưu hóa NPU
Điểm nhấn kỹ thuật của Gemma 3n là sự tương thích tuyệt đối với các bộ xử lý thần kinh (NPU) trên thiết bị di động.
- Kiến trúc thưa (Sparse Architecture): Áp dụng cơ chế định tuyến token thông minh, cho phép bỏ qua các lớp tính toán không cần thiết cho các token hình ảnh đơn giản.
- Chưng cất đa phương tiện (Multimodal Distillation): Nén tri thức từ Gemini 2.0 vào kích thước dưới 4B tham số.
Qwen3-VL 4B: Mô hình nhỏ cũng biết tư duy
Nếu Gemma 3n là sự cân bằng, thì Qwen3-VL của Alibaba Cloud lại có hướng tiếp cận hoàn toàn khác. Không chỉ đơn thuần nhận diện hình ảnh, Qwen3-VL còn mang đến khả năng suy luận logic phức tạp vốn chỉ thấy ở các mô hình 70B+ trước đây.
Kiến trúc DeepStack & Interleaved-MRoPE
Qwen3-VL giải quyết điểm yếu cố hữu của các mô hình nhỏ là mất mát chi tiết hình ảnh thông qua cơ chế DeepStack. Thay vì chỉ lấy đặc trưng hình ảnh (visual features) từ lớp cuối cùng của Vision Transformer (ViT), nó tổng hợp thông tin từ nhiều tầng khác nhau. Điều này giúp mô hình vừa nắm bắt được ngữ nghĩa tổng quát, vừa giữ lại các chi tiết mức pixel cần thiết cho tác vụ OCR.
Đồng thời, kỹ thuật Interleaved-MRoPE (Multimodal Rotary Positional Embedding) cho phép mô hình xử lý không gian theo 4 chiều: Thời gian (video), chiều dọc, chiều ngang và văn bản, hỗ trợ ngữ cảnh lên tới 256k token.
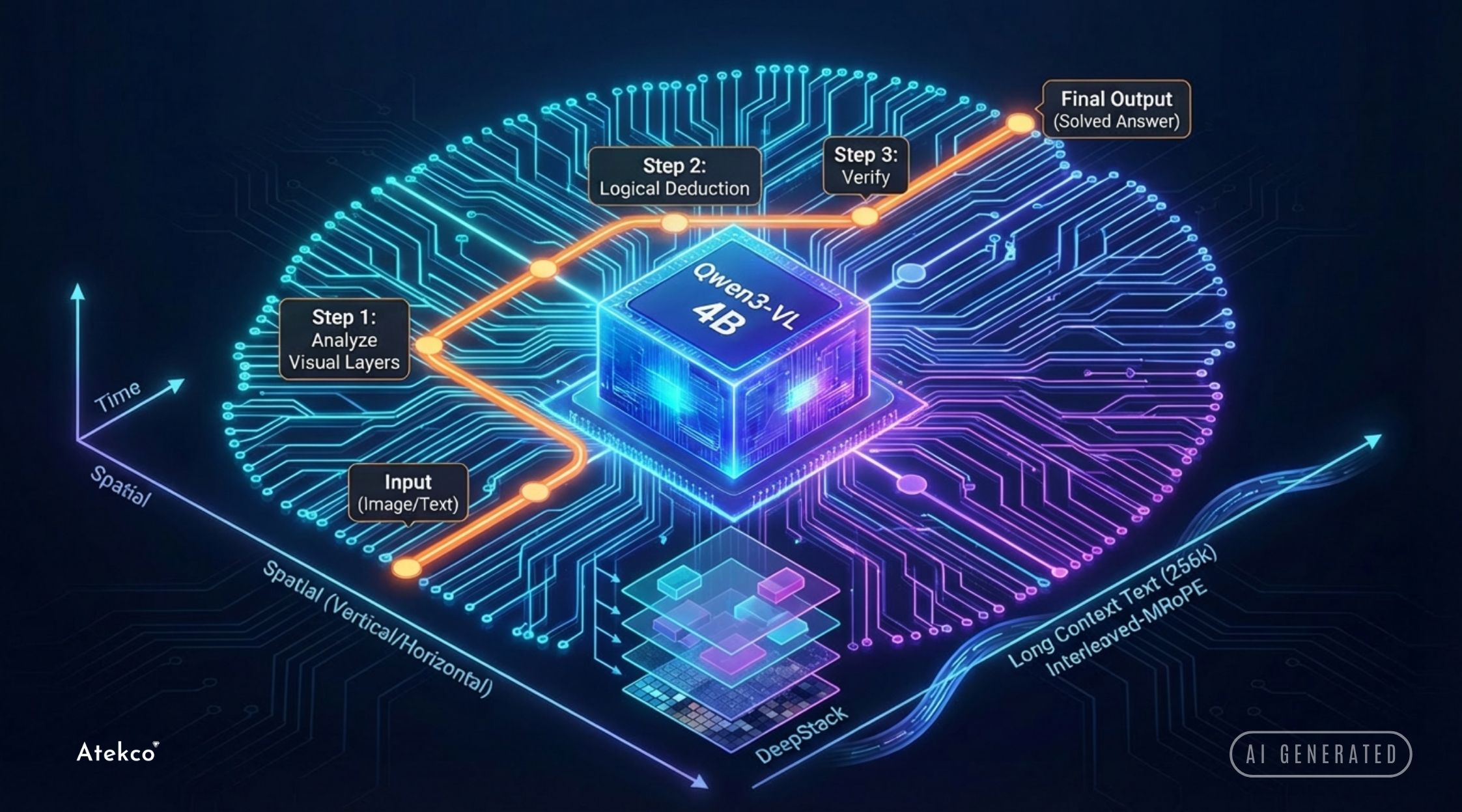
Tư duy hệ thống (System Thinking)
Điểm đột phá nhất là biến thể Qwen3-VL-Thinking, được huấn luyện để tạo ra các chuỗi suy nghĩ (reasoning traces) trước khi đưa ra câu trả lời cuối cùng. Ví dụ, khi giải một bài toán hình học từ ảnh, nó sẽ tự biện luận từng bước một. Kết quả benchmark trên MathVista (79.5%) cho thấy mô hình 4B này vượt trội hơn cả phiên bản Qwen2-VL-72B cũ trong các tác vụ đòi hỏi logic.
Moondream 3: Đôi mắt cho thiết bị IoT
Trong khi Qwen3 tập trung vào năng lực tư duy, thì mô hình Moondream 3 (Preview) lại tập trung vào tốc độ và sự trung thực. Đây là bản nâng cấp đáng giá từ dòng Moondream 2 vốn đã rất phổ biến trong cộng đồng Edge AI.
Kiến trúc siêu tối ưu (Compact Vision-Language Architecture)
Moondream 3 (Preview) tiếp tục duy trì kích thước siêu nhỏ (khoảng 1.6B tham số hoặc nhỏ hơn tùy biến thể), nhưng thay đổi hoàn toàn cách bộ mã hóa thị giác (Vision Encoder) hoạt động.
- SigLIP cải tiến: Sử dụng phiên bản SigLIP được tinh chỉnh riêng để nhận diện vật thể và trích xuất thông tin cực nhanh mà không cần độ phân giải ảnh quá lớn.
- Loại bỏ ảo giác: Moondream3 được huấn luyện đặc biệt để trung thực. Nếu không nhìn thấy chi tiết trong ảnh, nó sẽ trả lời là không biết thay vì bịa đặt - một đặc tính sống còn cho các ứng dụng IoT và Robotics.
.jpg)
Hiệu năng trên thiết bị IoT
Moondream 3 (Preview) được thiết kế để chạy mượt mà trên các thiết bị IoT như Raspberry Pi 5, Orange Pi hay thậm chí là điện thoại tầm trung mà không cần NPU quá mạnh. Tốc độ phản hồi gần như tức thời (sub-second latency), giúp nó trở thành lựa chọn hàng đầu cho các ứng dụng như:
- Mô tả hình ảnh cho người khiếm thị (smart glasses)
- Phân loại sản phẩm trên dây chuyền sản xuất
- Robot tự hành (Drone/Rover) cần xử lý hình ảnh thời gian thực
DeepSeek OCR & HunyuanOCR: Cuộc cách mạng số hóa tài liệu
Cuối năm 2025, cả DeepSeek và Tencent tung ra mô hình DeepSeek OCR và Hunyuan OCR chuyên dùng cho OCR, làm thay đổi hoàn toàn cách nhận diện chữ trong hình ảnh. Thay vì sử dụng quy trình nhiều bước phức tạp (phát hiện ký tự --> cắt ghép --> nhận diện), các mô hình này sử dụng kiến trúc đầu cuối (End-to-End) giúp đơn giản quá trình nhận diện.

DeepSeek OCR: Nén quang học ngữ cảnh
DeepSeek giới thiệu khái niệm Context Optical Compression. Nghĩa là thay vì cố gắng nhận diện từng ký tự bbox, mô hình nén hình ảnh tài liệu thành một chuỗi 'token thị giác' đại diện cho ngữ nghĩa. Với kiến trúc Mixture-of-Experts (MoE), DeepSeek OCR đạt năng suất 200.000 trang/ngày trên một GPU A100 đơn lẻ.
Hunyuan OCR: Sự chính xác tuyệt đối
Trong khi đó, Tencent đi theo hướng tối ưu hóa độ chính xác với Hunyuan OCR. Mô hình này sử dụng dữ liệu tổng hợp (synthetic data) chất lượng cao để huấn luyện khả năng chống chịu nhiễu. Hunyuan OCR đạt điểm số 860 trên OCRBench. Đây có thể xem là lựa chọn tối ưu cho trích xuất văn bản đa ngôn ngữ với độ chính xác cực cao. Tuy nhiên mô hình này bị giới hạn giấy phép sử dụng tại một số khu vực địa lý. Tham khảo thêm tại đây.
Trải nghiệm và hiệu năng thực tế
Trong điều kiện sử dụng thực tế, các mô hình trên đã mang lại sự bất ngờ lớn về hiệu suất suy luận cũng như khả năng tương thích với phần cứng cũ.
Thử nghiệm trên một chiếc Laptop Thinkpad đời cũ (hơn 5 năm tuổi) sử dụng GPU NVIDIA T1200 (4GB VRAM) cho kết quả thật sự ấn tượng:
- Với các model 4B như Gemma 3n, Qwen3-VL: Tốc độ đạt ~40 token/s. Con này đủ nhanh để bạn có thể chat và nhận phản hồi tương đối mượt mà.
- Với các model 1B như Hunyuan OCR hoặc Deepseek OCR: Tốc độ lên tới ~60 token/s. Việc trích xuất văn bản từ hình ảnh diễn ra gần như tức thời.
Nếu bạn sở hữu Macbook Pro (chip M3/M4) hoặc các laptop đời mới (RTX 4080), tốc độ suy luận có thể lên đến 100 token/s đem đến cảm giác mượt mà tương đương với các dịch vụ AI hàng đầu hiện nay.
Với hiệu suất này, các mô hình trên hoàn toàn phù hợp cho nhu cầu sử dụng cá nhân hàng ngày (trợ lý ảo local, tóm tắt tài liệu, chat với hình ảnh) mà không cần đầu tư phần cứng đắt tiền như RTX 5090 hay H200. Đây là minh chứng rõ ràng nhất cho việc AI đang trở nên 'bình dân hóa' hơn.
Để biết cách thiết lập chi tiết trên thiết bị cá nhân, bạn có thể tham khảo bài hướng dẫn tại đây.
Khuyến nghị kỹ thuật
Sự phát triển của các mô hình nguồn mở cuối năm 2025 cho thấy chúng ta không cần siêu máy tính để giải quyết mọi vấn đề. Tùy thuộc vào bài toán cụ thể, các kỹ sư có thể lựa chọn mô hình AI phù hợp:
| Nhu cầu | Mô hình khuyến nghị | Lý do kỹ thuật |
|---|---|---|
| Suy luận logic, giải toán | Qwen3-VL 4B (Thinking) | Khả năng suy luận chuỗi (Chain-of-Thought) vượt trội |
| IoT/Robotics/Thiết bị nhúng | Moondream3 (Preview) | Siêu nhẹ, độ trễ thấp, tối ưu cho CPU/NPU yếu, lý tưởng cho thiết bị IoT |
| Số hóa tài liệu quy mô lớn | DeepSeek OCR/HunyuanOCR | Chuyên dụng cho các tác vụ OCR |
| Trợ lý đa năng hàng ngày | Gemma 3/3n | Cân bằng giữa hiệu năng và tài nguyên |
Kỷ nguyên của 'AI bỏ túi' đã thực sự bắt đầu, nơi các mô hình AI được tối ưu hóa đến từng tham số để phục vụ nhu cầu hàng ngày.
Tham khảo

