- Ôn lại RAG Workflow – Tổng quan luồng xử lý
- "Đọc file" không đơn thuần là trích xuất text
- Đừng để sót nội dung của PDF
- Cẩn thận Excel ngốn hết RAM khi xử lý
- Điều gì thực sự nằm sau những slide PowerPoint?
- Embedding và bài toán hiệu suất
- Tối ưu throughput trong xử lý embedding
- Chọn payload size và concurrency level
- Các yếu tố cần cân nhắc
- Hệ thống multi-worker và multi-user
- Bulkhead pattern trong hệ thống embedding
- Tính ổn định của hệ thống
- RAM và tài nguyên hệ thống
- Các kỹ thuật hỗ trợ RAG
- 1. Domain glossary: Giải quyết sự nhập nhằng thuật ngữ
- 2. Query transformation: Một câu hỏi không đủ để tìm đúng thông tin
- 3. RAG prompt template: Kiểm soát cách mô hình suy luận
- 4. External knowledge base: Để câu trả lời đáng tin hơn
- Kết luận
Bài học kinh nghiệm khi xây dựng hệ thống RAG
Chia sẻ kinh nghiệm trong quá trình xây dựng và vận hành hệ thống RAG thực tế trong doanh nghiệp.

Việc xây dựng một hệ thống RAG (Retrieval-Augmented Generation) hiệu quả không chỉ phụ thuộc vào mô hình mạnh hay hạ tầng tính toán lớn, mà nằm ở khả năng thiết kế một pipeline ổn định, tối ưu và phù hợp với đặc thù dữ liệu thực tế. Ngày nay, hầu hết các hệ thống AI hiện đại đều cần tích hợp RAG để mở rộng kiến thức, tăng độ chính xác và đảm bảo khả năng giải quyết bài toán. Khi hệ thống vận hành với hàng nghìn tài liệu, hàng trăm người dùng song song, các vấn đề về hiệu năng, ổn định và tối ưu tài nguyên trở nên cực kỳ rõ rệt.
Trong bài viết này, mời bạn cùng khám phá những kinh nghiệm thực tế trong việc xây dựng một hệ thống RAG hiệu quả.
Ôn lại RAG Workflow – Tổng quan luồng xử lý
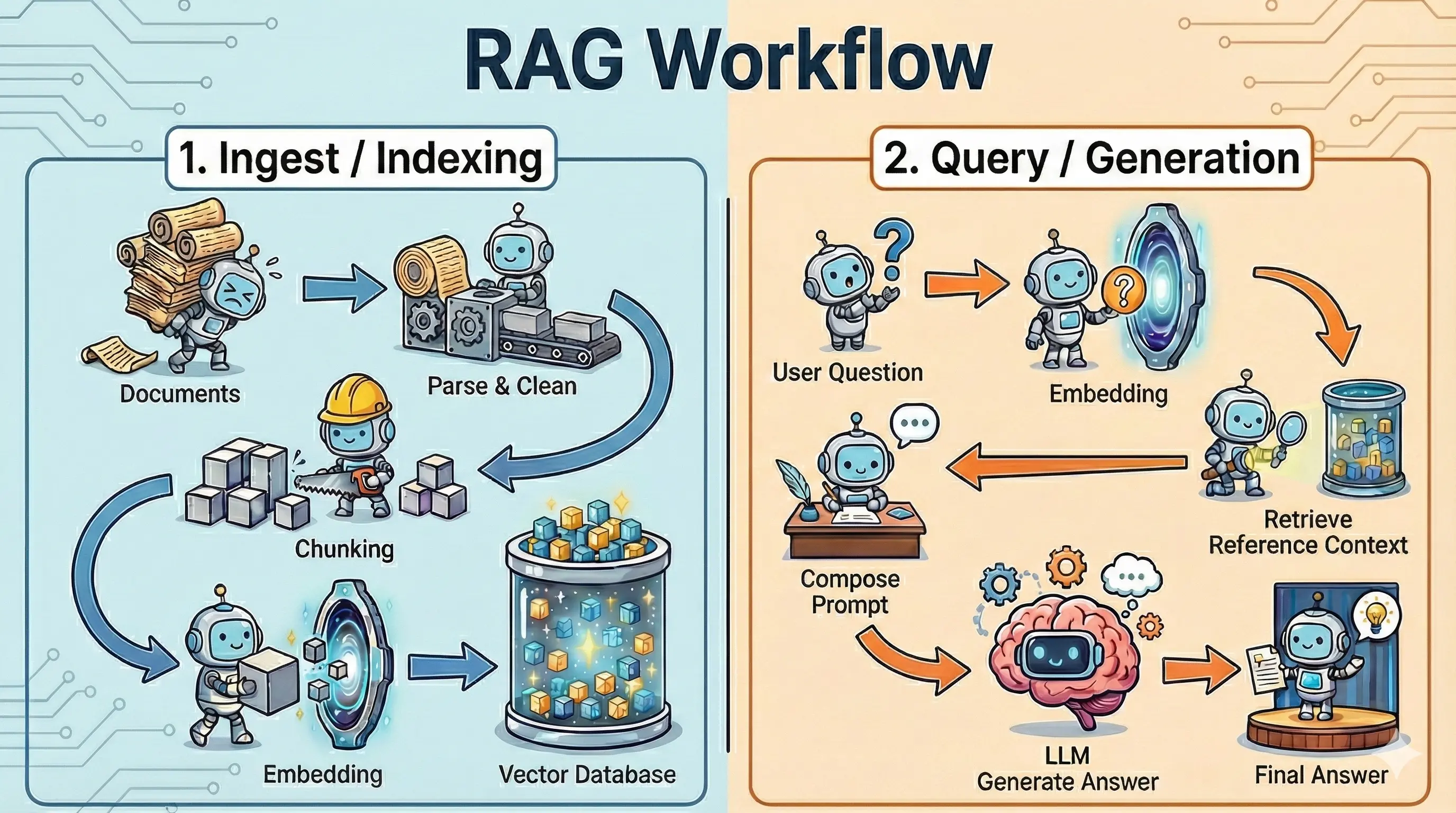
Tổng quan RAG Workflow
RAG Workflow là toàn bộ vòng đời xử lý, từ thời điểm dữ liệu thô được đưa vào cho đến khi mô hình sinh ra câu trả lời cuối cùng cho người dùng. Luồng này thường được chia thành hai giai đoạn: Ingest/Indexing và Query/Generation, mỗi giai đoạn đảm nhiệm một vai trò riêng biệt nhưng có mối liên kết chặt chẽ với nhau.
Ở giai đoạn Ingest / Indexing, hệ thống tiếp nhận các tài liệu đầu vào, thực hiện "đọc file" và chuẩn hoá, sau đó chia nhỏ nội dung thành các đơn vị phù hợp. Những đoạn nội dung này sau đó được thực hiện embedding và lưu trữ trong vector database, tạo nên knowledge base để phục vụ truy vấn sau này.
Khi người dùng đặt câu hỏi, hệ thống chuyển sang giai đoạn Query/Generation. Truy vấn có thể được tiền xử lý, rồi thực hiện embedding và dùng để tìm kiếm các đoạn ngữ cảnh liên quan nhất trong knowledge base. Các ngữ cảnh này được kết hợp vào prompt, giúp mô hình ngôn ngữ có đủ thông tin cần thiết để suy luận và tạo ra câu trả lời chính xác hơn.
Xem thêm về các kỹ thuật RAG ở bài viết Toàn cảnh các kỹ thuật Advanced RAG.
"Đọc file" không đơn thuần là trích xuất text
Hiệu quả của một hệ thống RAG phụ thuộc rất lớn vào chất lượng của dữ liệu đầu vào. Nếu dữ liệu bị trích xuất sai, mất cấu trúc hoặc thiếu ngữ cảnh thì toàn bộ quá trình xử lý phía sau đều bị ảnh hưởng. Vì vậy, bước xử lý và chuẩn hoá tài liệu trở thành nền tảng quan trọng nhất trong bất kỳ hệ thống RAG nào.
Mỗi định dạng có cách xử lý khác nhau
Đừng để sót nội dung của PDF
PDF là định dạng rất phổ biến trong hệ thống RAG, nhưng bản chất của PDF được thiết kế để hiển thị cố định, không phải để trích xuất dữ liệu. Điều này khiến việc parse PDF phụ thuộc nhiều vào cách tài liệu được tạo. Trong thực tế, xử lý PDF không chỉ dừng ở việc lấy text, mà còn phải đối phó với ảnh scan, nhận diện bảng biểu, sơ đồ, và các thành phần phi văn bản khác để tái tạo đúng ngữ cảnh của tài liệu.
Một công cụ phù hợp để xử lý PDF là Mistral OCR.
Mistral OCR có khả năng nhận diện text, bảng biểu, hình ảnh và bố cục phức tạp với độ chính xác cao, hỗ trợ trích xuất dữ liệu có cấu trúc. Một điểm đặc biệt của Mistral OCR là khả năng annotation mạnh mẽ thông qua hai tham số: bbox_annotation và document_annotation.
- Với bbox_annotation, người dùng có thể yêu cầu phân loại, mô tả hoặc phân tích các hình ảnh, biểu đồ, ký hiệu,… xuất hiện trong tài liệu. Nhờ vậy, mô hình có thể "đọc hiểu" nội dung trực quan bằng cách đặt từng hình ảnh vào đúng ngữ cảnh, thay vì chỉ nhận diện text như OCR thông thường.
- Với document_annotation, mô hình có thể đọc toàn bộ tài liệu và trích xuất thông tin vào một cấu trúc JSON do người dùng tự định nghĩa, chẳng hạn như điền các trường của hóa đơn, hợp đồng hoặc form. Điều này cho phép tự động hoá quá trình bóc tách dữ liệu ở cấp độ tài liệu, thay thế cho thao tác nhập liệu thủ công.
Một số lưu ý khi xử lý PDF bằng OCR API:
- Khi sử dụng OCR API, cần thiết lập cơ chế retry, fallback hoặc degrade mode để đảm bảo hệ thống không bị gián đoạn khi API gặp lỗi tạm thời. Fallback có thể là sử dụng OCR offline (Tesseract/PaddleOCR), parser text đơn giản như Markitdown/Docling hoặc thực hiện phân trang nhỏ hơn.
- Cần chú ý giới hạn dung lượng, số trang, tốc độ của từng OCR API để thiết kế chiến lược gọi phù hợp. Ví dụ: với tài liệu có nhiều biểu đồ, hình ảnh hoặc trang có độ phức tạp cao, nên chia nhỏ request để giảm độ trễ và tăng độ chính xác đầu ra.
Cẩn thận Excel ngốn hết RAM khi xử lý
Excel là định dạng phổ biến khi làm việc với dữ liệu dạng bảng như checklist, báo cáo hay danh sách. Khi parse Excel phục vụ RAG thì chỉ trích xuất text là chưa đủ, ta cần giữ được cấu trúc bảng (hàng, cột) để đảm bảo ngữ cảnh. Các tập tin Excel có thể có dung lượng nhỏ nhưng cấu trúc phức tạp, và một số khác có thể lên tới hàng trăm nghìn dòng.
- python-calamine: python-calamine là công cụ parse Excel có hiệu năng tốt. Nhờ được xây dựng trên nền tảng Rust, calamine xử lý file Excel lớn với tốc độ nhanh và mức sử dụng RAM thấp. Package size của python-calamine cũng rất nhỏ, thuận tiện triển khai trong môi trường serverless hoặc microservice. Tuy nhiên, khi sử dụng python-calamine, cần lưu ý xử lý và fallback trong một số trường hợp xảy ra PanicException.
- Markitdown: Markitdown có khả năng chuyển đổi Excel thành dạng markdown và xử lý tương đối ổn với file nhỏ. Tuy nhiên trong phiên bản gần nhất (0.1.4), Markitdown vẫn tiêu tốn rất nhiều RAM và thời gian để xử lý file Excel lớn (tốn gần 4GB RAM khi xử lý file excel ~270k dòng x 8 cột). Dù vậy, Markitdown vẫn có ưu điểm là luồng chuyển đổi đơn giản, dễ dự đoán và tạo ra markdown sạch, phù hợp cho các tác vụ cần tốc độ triển khai nhanh hoặc xử lý tài liệu kích thước vừa và nhỏ.
- pandas: pandas là công cụ quen thuộc khi làm việc với Excel, hỗ trợ tốt cho các tác vụ phân tích hoặc transform dữ liệu dạng bảng. Tuy nhiên, do hỗ trợ nhiều parser engine khác nhau nên pandas có package size lớn, có thể ảnh hưởng đến kích thước container. Nhìn chung, pandas phù hợp khi hệ thống cần thêm thao tác lọc, tính toán, biến đổi dữ liệu sau khi parse. Pandas là một công cụ đa năng, an toàn nhưng chưa tối ưu nếu mục tiêu chỉ là parse Excel phục vụ RAG.
- Docling: Không chỉ đơn thuần là parse Excel, Docling có bước tiền/hậu xử lý để tự nhận diện vùng dữ liệu, tách nhiều bảng, giữ merged cells,... giúp kết quả giàu thông tin hơn. Tuy nhiên đối với file Excel lớn tương tự bài test với Markitdown, thời gian và mức tiêu thụ RAM của Docling có thể cao hơn kỳ vọng (1GB RAM). Với những sheet có cấu trúc phức tạp, output đôi khi cần được rà soát để đảm bảo đúng ngữ cảnh và cấu trúc bảng.
Điều gì thực sự nằm sau những slide PowerPoint?
PowerPoint là định dạng slide thuyết trình trong đó nội dung được bố trí thông qua các textbox, shape, bảng biểu, biểu đồ, hình ảnh và các layout đa dạng trên từng slide. Đặc thù của PowerPoint là nội dung mang tính không tuyến tính - vị trí các thành phần trên slide (trái/phải, trên/dưới, nhóm theo khối) thường quan trọng hơn thứ tự text. Khi xử lý PPTX cho RAG, mục tiêu không chỉ là trích xuất text mà còn phải tái tạo lại ngữ cảnh slide, phân biệt đúng các block nội dung và nắm được quan hệ giữa chúng.
- Các công cụ như Markitdown và Docling có thể đọc text từ slide, tách bảng, bullet, tiêu đề và một phần bố cục. Markitdown phù hợp cho file nhỏ, cần xuất Markdown nhanh; Docling có khả năng nhận diện cấu trúc tốt hơn, giữ được metadata và bố cục cơ bản. Tuy nhiên, cả hai công cụ đều gặp giới hạn khi slide chứa nhiều biểu đồ phức tạp, thành phần đồ hoạ, infographic hoặc nội dung được nhúng dưới dạng hình ảnh.
- Một cách tiếp cận hiệu quả cho các file chứa nhiều hình ảnh hoặc text nằm trong shape đặc biệt là chuyển PPTX sang PDF rồi dùng OCR như Mistral OCR để trích xuất nội dung. Cách này giúp mô hình "nhìn" slide như một trang tài liệu trực quan, đặc biệt hữu ích với biểu đồ, ảnh chụp màn hình, sơ đồ hoặc nội dung không phải text thuần. Mistral OCR cũng hỗ trợ annotation để mô tả hình ảnh, biểu đồ, caption, giúp tái tạo ngữ cảnh slide tốt hơn.
- Trong các slide có nhiều thành phần phức tạp mà OCR khó nhận diện như infographic, flowchart, template layout,... ta có thể convert slide thành hình ảnh và sử dụng LLM API multimodal để đọc hiểu. LLM có khả năng mô tả nội dung, phân tích thành phần, trích xuất insight và hiểu ngữ nghĩa tổng thể tốt hơn OCR. Cách này đặc biệt hữu ích khi slide được thiết kế thiên về truyền đạt ý tưởng bằng hình ảnh thay vì text.
Embedding và bài toán hiệu suất
Quá trình Embedding cơ bản ban đầu chỉ đơn thuần là: Nhận tài liệu -> Chia nhỏ thành chunk -> Gọi API embedding chuyển thành vector -> Lưu vector vào DB để retrieval.
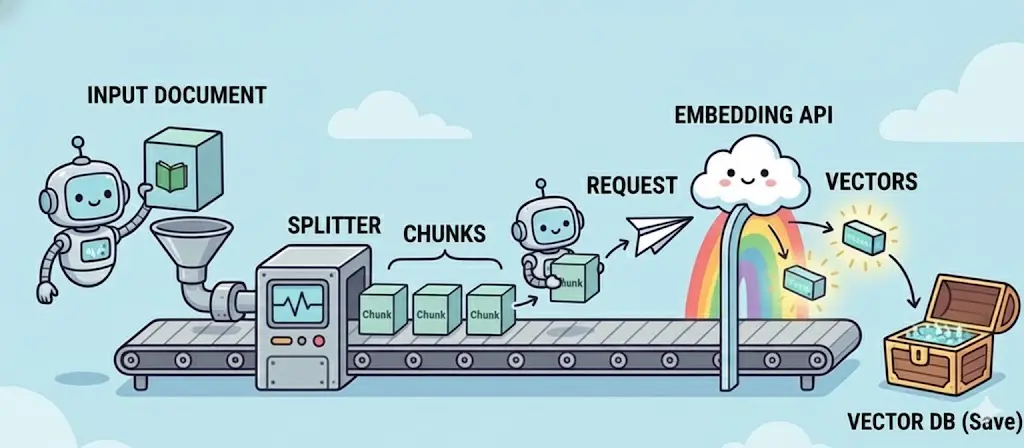
Một ngày bình yên của quá trình RAG
Nhưng khi khối lượng tài liệu thực tế tăng mạnh - từ vài MB đến hàng chục, thậm chí hàng trăm MB - thì quy trình "cơ bản" này nhanh chóng bộc lộ hàng loạt vấn đề về performance, chi phí và độ ổn định.
Một file PDF vài trăm trang có thể sinh ra hàng chục nghìn chunk. Nếu bạn gửi từng chunk trong một request riêng lẻ, tổng số request sẽ rất lớn, thời gian xử lý kéo dài và hệ thống dễ vướng vào throttling hoặc timeout khi có nhiều người dùng cùng upload tài liệu.
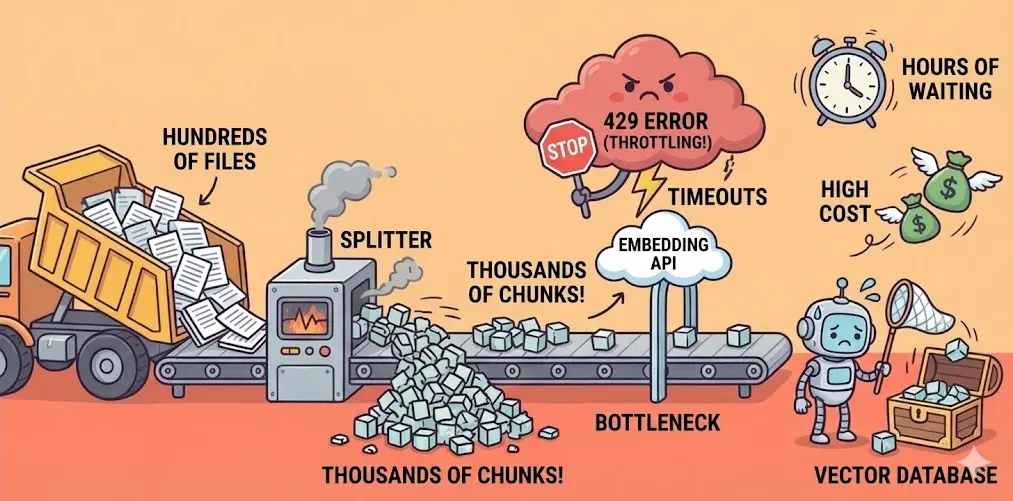
Một ngày "bình thường" của quá trình RAG
Tối ưu throughput trong xử lý embedding
Hầu hết API embedding đều áp dụng giới hạn theo tokens-per-minute (rate-limit). Vì vậy, yếu tố quyết định tốc độ xử lý không phải mỗi request nhanh hay chậm, mà là tổng số tokens bạn có thể gửi qua API trong một phút - tức throughput.
Để tăng throughput, có hai thông số quan trọng:
1. Payload size - lượng tokens được gửi trong một request
Payload size thể hiện tổng số tokens trong một lần gọi embedding. Payload size lớn giúp giảm số lượng request, nhưng cũng khiến latency của mỗi request tăng lên và tiêu tốn nhiều RAM hơn.
2. Concurrency level - số request chạy song song
Concurrency level càng cao thì tổng lượng tokens được xử lý mỗi phút càng lớn, miễn là không vượt quá giới hạn tối đa. Tuy nhiên, gửi quá nhiều request cũng tạo ra nhiều overhead HTTP, làm giảm hiệu quả tổng thể.
Tối ưu embedding là tìm được điểm cân bằng giữa payload size và concurrency level sao cho hệ thống:
- Tận dụng tối đa giới hạn tokens-per-minute của API
- Không gây nghẽn ở tầng request (xảy ra lỗi 429), ít lỗi mạng và ít retry.
- Hoạt động ổn định, không vượt quá giới hạn RAM.
Chọn payload size và concurrency level
Một cách đơn giản để hình dung throughput:
Trong đó:
- latency: thời gian xử lý trung bình mỗi request. (60 / latency) là số cycle gửi request trong 1 phút.
- payload_size: tổng số tokens gửi trong một request.
- concurrency_level: số request chạy song song.
Để tận dụng tối đa rate-limit, ta muốn throughput tiến gần đến giới hạn tokens-per-minute mà API cho phép.
Vì chunking strategy quyết định số lượng tokens trong mỗi chunk, và thực tế các chunk thường có kích thước rất khác nhau, nên việc gửi từng chunk một sẽ khó tối ưu. Trong trường hợp API cho phép batching, ta nên gom nhóm các chunk lại thành các batch có tổng tokens phù hợp, thay vì xử lý từng chunk riêng lẻ. Cách này giúp kiểm soát payload size tốt hơn, tận dụng tối đa quota tokens/minute và giảm đáng kể số lượng request phải gửi đi.
Ta lập bảng tính như sau:
| payload_size | latency | concurrency_level | throughput | efficiency |
|---|---|---|---|---|
| Payload ước tính | Thời gian xử lý payload ước tính đo đạc được | Concurrency level tối đa tính được theo công thức và làm tròn xuống tới số nguyên gần nhất | Throughput thực tế với concurrency level và payload size đã chọn | Hiệu suất thực tế |
Bảng minh họa
| payload_size | latency | concurrency_level | throughput | efficiency |
|---|---|---|---|---|
| 300,000 | 5s | 2.78 → 2 | (60/5) × 300,000 × 2 = 7,200,000 | 72% |
| 200,000 | 4s | 3.33 → 3 | (60/4) × 200,000 × 3 = 9,000,000 | 90% |
| 150,000 | 3.5s | 3.89 → 3 | (60/3.5) × 150,000 × 3 = 7,714,286 | 77.1% |
→ Với dữ liệu này, lựa chọn tối ưu là payload_size = 200,000 và concurrency = 3.
Các yếu tố cần cân nhắc
Khi tối ưu embedding trong môi trường thực tế, đặc biệt là hệ thống có nhiều worker hoặc nhiều người dùng upload tài liệu song song, việc lựa chọn payload size và concurrency level không còn là một bài toán đơn lẻ mà trở thành một phần trong chiến lược điều phối tài nguyên toàn hệ thống.
Hệ thống multi-worker và multi-user
Trong mô hình multi-worker (nhiều tiến trình cùng xử lý embedding), tổng throughput của hệ thống là tổng throughput của từng worker cộng lại. Vì vậy, bạn cần phân bổ ngân sách tokens-per-minute của API cho từng worker để tránh tình trạng các worker cạnh tranh quota dẫn đến lỗi 429 hàng loạt. Giải pháp phổ biến là xây dựng một rate-limit coordinator hoặc token-budget manager, cho phép mỗi worker lấy một phần cố định của quota và điều chỉnh concurrency nội bộ sao cho tổng throughput toàn hệ thống vẫn ổn định.
Trong môi trường multi-user (nhiều người upload file lớn cùng lúc), vấn đề không chỉ là tối ưu tốc độ mà còn phải đảm bảo tài nguyên được chia đều. Hệ thống có thể dùng queue để điều tiết tải. Khi có quá nhiều job embedding xuất hiện cùng lúc, hệ thống có thể mở rộng số worker hoặc tạm thời giảm concurrency của từng worker để giữ hệ thống ổn định, tránh vượt rate-limit và tránh chiếm RAM quá mức.
Bulkhead pattern trong hệ thống embedding
Việc phân bổ tokens-per-minute và điều chỉnh concurrency chỉ giải quyết bài toán chia sẻ tài nguyên ở mức tổng thể. Khi xuất hiện các job embedding lớn, vẫn tồn tại rủi ro một job chiếm dụng quá nhiều tài nguyên và làm ảnh hưởng đến toàn bộ hệ thống.
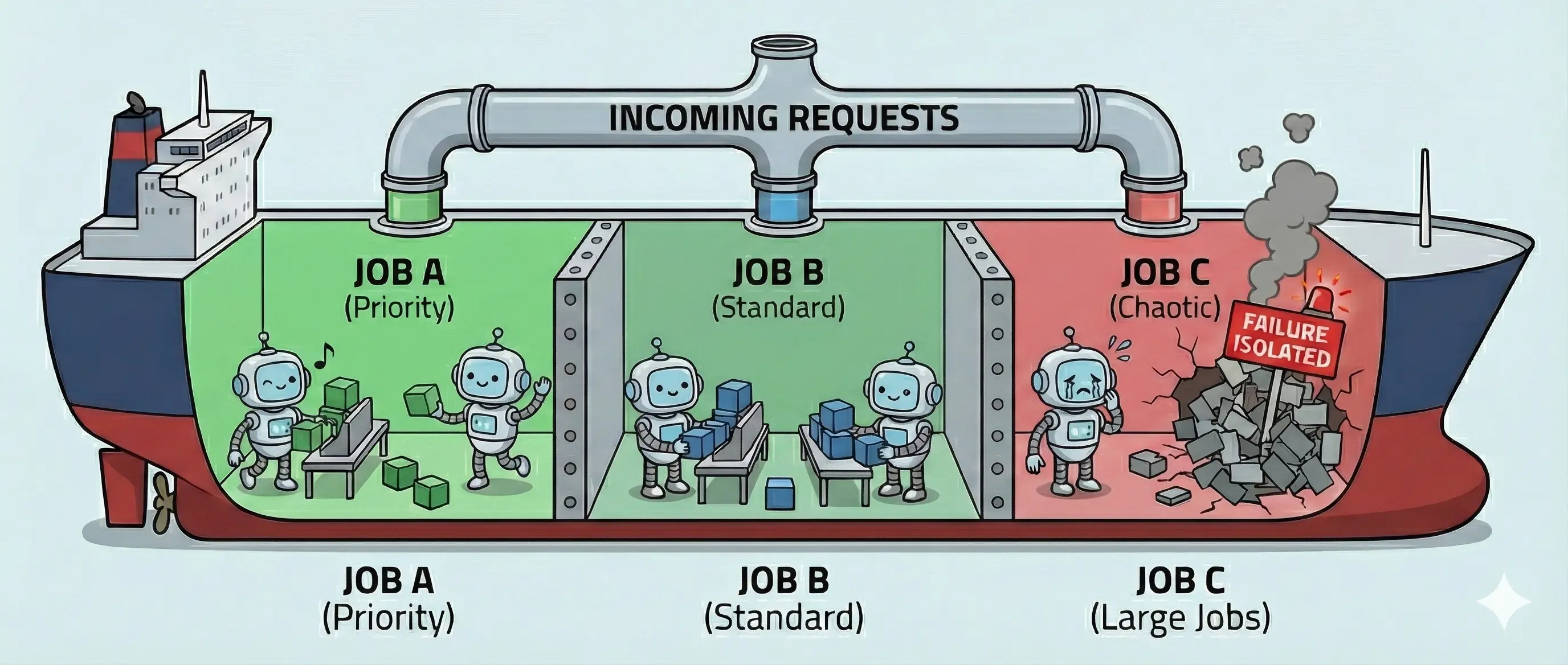
Bulkhead Pattern
Bulkhead pattern được áp dụng để xử lý vấn đề này bằng cách chia tách tài nguyên embedding thành các ngăn (bulkhead) độc lập. Mỗi ngăn có mức giới hạn tài nguyên riêng. Trong hệ thống embedding, mỗi ngăn có thể tương ứng với một nhóm worker riêng hay một queue riêng cho từng loại job.
Nhờ cơ chế này, mỗi job embedding chỉ có thể tiêu thụ tài nguyên trong phạm vi bulkhead của nó, không thể chiếm dụng toàn bộ connection hay token budget của hệ thống. Các job hoặc user khác vẫn có thể tiếp tục được xử lý bình thường, ngay cả khi một bulkhead gặp sự cố như 429, timeout hoặc OOM.
Trong thực tế, bulkhead thường được kết hợp với queue và rate-limit coordinator để kiểm soát tải hiệu quả hơn.
Bulkhead pattern không trực tiếp làm tăng throughput, nhưng đóng vai trò quan trọng trong việc ngăn lỗi lan truyền, cô lập sự cố và duy trì khả năng phục vụ ổn định khi tải tăng, đặc biệt trong các hệ thống embedding vận hành ở quy mô lớn.
Tính ổn định của hệ thống
Khi hệ thống vận hành ở mức tải cao, dễ phát sinh lỗi 429 theo hiệu ứng dây chuyền. Vì thế, hầu hết hệ thống không chạy sát mức tối đa lý thuyết, mà duy trì ở mức khoảng 85–95% ngân sách tokens-per-minute. Cách làm này tạo biên độ an toàn để hệ thống xử lý biến động về latency hoặc thời gian chờ của API. Điều này đặc biệt quan trọng trong mô hình multi-worker, nơi chỉ một worker gặp sự cố cũng có thể gây ảnh hưởng đến tốc độ xử lý chung.
RAM và tài nguyên hệ thống
Payload size lớn giúp giảm số lượng request, nhưng đồng thời gây áp lực nặng lên RAM vì phải chứa toàn bộ batch tokens và embedding output. Với embedding dimension 1536, chỉ vài chục chunk đã có thể chiếm tới hàng MB bộ nhớ. Trong môi trường nhiều worker, tổng mức tiêu thụ RAM tăng tuyến tính theo số worker và concurrency của mỗi worker. Vì vậy, payload size không thể chỉ tối ưu theo throughput mà phải cân đối với giới hạn tài nguyên thực tế của máy chủ. Nếu RAM hạn chế, hệ thống có thể chọn payload size trung bình và tăng concurrency để bù throughput, nhưng cách này lại làm tăng overhead HTTP và yêu cầu quản lý load phức tạp hơn.
Các kỹ thuật hỗ trợ RAG
Tối ưu quá trình RAG
Trong quá trình vận hành hệ thống RAG, việc xây dựng pipeline mới chỉ là bước khởi đầu. Khi hệ thống bắt đầu xử lý dữ liệu và phục vụ người dùng, các vấn đề về độ chính xác, độ bao phủ thông tin và hiệu năng sẽ dần bộc lộ. Vì vậy, RAG cần được monitor liên tục và tinh chỉnh, thay vì chỉ dựa vào cấu hình cố định.
Các kỹ thuật dưới đây tập trung giải quyết một số vấn đề thường gặp trong RAG, từ cách giúp mô hình hiểu thuật ngữ chuyên ngành, cải tiến cách truy vấn dữ liệu, cho đến việc kiểm soát quá trình suy luận và khả năng mở rộng nguồn tri thức. Khi được áp dụng đúng cách, những kỹ thuật này giúp nâng cao chất lượng câu trả lời, giảm sai lệch, đồng thời tối ưu chi phí và hiệu năng trong quá trình vận hành hệ thống.
1. Domain glossary: Giải quyết sự nhập nhằng thuật ngữ
Trong các bài toán như dịch thuật, hỏi đáp chuyên môn hoặc phân tích tài liệu, hệ thống có thể xây dựng một bộ từ điển gồm các từ, cụm từ và khái niệm đặc thù. Khi người dùng truy vấn, ta dùng thuật toán tìm kiếm/so khớp để phát hiện các thuật ngữ này và chèn chúng vào prompt hoặc vào bước chuẩn hoá dữ liệu.
Việc tìm kiếm và bổ sung trước các thuật ngữ chuẩn giúp mô hình:
- Giữ chuẩn xác về ngôn ngữ chuyên ngành
- Giảm sai lệch và đảm bảo nhất quán giữa các lần xử lý
- Giảm kích thước prompt, tiết kiệm chi phí so với việc nạp toàn bộ từ điển vào mô hình trong mỗi lần gọi
Bộ từ điển thuật ngữ chuyên ngành đặc biệt quan trọng trong các lĩnh vực như y tế, tài chính, pháp lý hoặc các domain kỹ thuật phức tạp.
2. Query transformation: Một câu hỏi không đủ để tìm đúng thông tin
Trước khi đi vào retrieval, hệ thống có thể tạo thêm các phiên bản biến đổi từ câu hỏi gốc để tăng độ bao phủ ngữ nghĩa. Các biến đổi phổ biến gồm:
- Mở rộng từ đồng nghĩa hoặc cụm từ tương đương
- Chuẩn hoá văn phong, cấu trúc câu,...
- Chuyển đổi kiểu diễn đạt (câu hỏi → mô tả, mô tả → mục tiêu)
- Tách câu phức thành nhiều câu nhỏ, dễ tìm kiếm hơn
Chiến lược này giúp tăng xác suất tìm đúng đoạn nội dung, đặc biệt hiệu quả trong các hệ thống có dữ liệu không đồng nhất hoặc khi người dùng đặt câu hỏi theo ngôn ngữ tự nhiên, phi cấu trúc.
3. RAG prompt template: Kiểm soát cách mô hình suy luận
Prompt template mặc định của từng framework RAG thường được thiết kế để phục vụ mục đích chung. Vì vậy, tối ưu prompt template là một trong những yếu tố quan trọng để tăng chất lượng câu trả lời.
Một template tốt cần điều chỉnh rõ:
- Cách mô hình kết hợp giữa knowledge và reasoning
- Cách gọi tool hoặc tương tác với MCP server
- Các ràng buộc về định dạng, ngữ điệu và yêu cầu output
Với các hệ thống tích hợp nhiều nguồn dữ liệu hoặc nhiều công cụ hỗ trợ, prompt template giữ vai trò như "orchestrator", đảm bảo mô hình hiểu đúng vai trò của từng nguồn thông tin.
4. External knowledge base: Để câu trả lời đáng tin hơn
Trong thực tế, knowledge base do người dùng tự tạo thường không đủ để bao quát mọi trường hợp. Vì vậy, việc bổ sung external knowledge base là cách phổ biến để tăng tính toàn diện của câu trả lời.
Để làm điều này hiệu quả, hệ thống cần:
- Kiến trúc plug-and-play cho phép tích hợp nhiều knowledge base khác nhau đơn giản
- Khả năng cấu hình chunking strategy theo từng dạng tài liệu
- Cơ chế chọn knowledge base theo ngữ cảnh truy vấn
External knowledge base giúp mở rộng phạm vi hiểu biết, giảm tình trạng thiếu dữ liệu và làm câu trả lời trở nên sâu sắc và đáng tin cậy hơn.
Kết luận
Trong quá trình vận hành, hệ thống sẽ phát sinh nhiều vấn đề không thể lường trước: dữ liệu không đồng nhất, giới hạn API, vấn đề hiệu năng, hay những trường hợp đặc biệt từ người dùng. Việc liên tục phân tích, thử nghiệm và giải quyết những vấn đề này là cách tích lũy kinh nghiệm và từng bước cải thiện hiệu quả của toàn hệ thống. Mỗi thách thức vì thế lại trở thành một cơ hội tự nhiên để hệ thống AI ngày càng hoàn thiện hơn.

