Toàn cảnh các kỹ thuật Advanced RAG
Tổng quan về các kỹ thuật Advanced RAG giúp tăng khả năng nhận thức ngữ cảnh, cải thiện độ liên quan và chính xác của các mô hình ngôn ngữ lớn trên các tập dữ liệu riêng mà không cần đào tạo lại.

Ngày nay, việc áp dụng các mô hình ngôn ngữ lớn (Large Language Models - LLM) vào hệ thống để xử lý và phân tích dữ liệu đã trở nên phổ biến. Tuy nhiên, để nâng cao chất lượng và độ chính xác của các phản hồi, việc ứng dụng RAG (Retrieval-Augmented Generation) là một bước đi cần thiết.
Hạn chế của kĩ thuật RAG cơ bản
RAG là một phương pháp nhằm cải thiện kết quả của các LLM bằng cách tận dụng thêm các nguồn dữ liệu tham khảo bên ngoài. Quy trình này bao gồm ba thành phần chính: hệ thống truy xuất, cơ sở dữ liệu chứa thông tin tham khảo và thành phần tạo sinh - LLM.

Trong Basic RAG, thông tin từ các nguồn dữ liệu bên ngoài được tải và phân tách thành các đoạn nhỏ (chunking), mã hóa thành vector bằng mô hình Transformer Encoder (embedding model), và lưu thành các index (indexing). Khi có truy vấn từ người dùng, hệ thống sẽ vector hóa truy vấn này và tìm kiếm trong các index để xác định các đoạn thông tin phù hợp nhất, sau đó tổng hợp và đưa vào LLM model dưới dạng ngữ cảnh để tạo nội dung phản hồi.
Dù có thể giải quyết được các nhu cầu cơ bản, tuy nhiên Basic RAG cũng có một số vấn đề như:
- Quá trình truy vấn: Thiếu độ chính xác trong việc lựa chọn thông tin liên quan đến câu hỏi của người dùng và có khả năng bỏ sót các chi tiết quan trọng.
- Quá trình tạo phản hồi: Sai lệch ngữ cảnh có thể dẫn đến việc tạo nội dung không chính xác, không liên quan, ảnh hưởng đến chất lượng và độ tin cậy của hệ thống.
- Quá trình tích hợp thông tin: Thông tin được lấy từ nhiều nguồn mà không có sự tổng hợp hoặc bổ sung sẽ có khả năng trùng lặp, xung đột, thiếu nhất quán về văn phong… ảnh hưởng đến sự mạch lạc của kết quả phản hồi, làm giảm trải nghiệm người dùng.
Những hạn chế của Basic RAG đã thúc đẩy sự phát triển của hệ thống phức tạp hơn mang tên Advanced RAG. Hệ thống này được cải tiến để khắc phục những điểm yếu bằng cách tinh chỉnh cơ chế truy xuất dữ liệu, tăng cường xử lý và tích hợp nội dung được truy xuất, cải thiện sự liền mạch và độ tin cậy của các phản hồi được tạo ra. Thông qua những cải tiến này, Advanced RAG có khả năng nhận thức ngữ cảnh tốt hơn, cung cấp các phản hồi liên quan, chính xác hơn trong các hệ thống sử dụng RAG.
Các kĩ thuật RAG nâng cao
Advanced RAG là các phương pháp kĩ thuật để cải tiến các quá trình xử lý trong RAG như ảnh minh họa bên dưới:

- Indexing: Tối ưu hóa giai đoạn vector hóa và chuyển đổi dữ liệu thành các định dạng tập trung ngữ nghĩa, giúp cải thiện hiệu quả truy vấn.
- Query Tranformation: Làm rõ và tinh chỉnh câu hỏi gốc của người dùng, tăng sự phù hợp với nhiệm vụ truy xuất.
- Query Routing: Chọn lựa nguồn dữ liệu và câu truy vấn phù hợp để tối đa hóa hiệu quả truy xuất.
- Retrieval: Đảm bảo nội dung truy xuất toàn vẹn và đầy đủ ngữ cảnh.
- Post-Retrieval: Tích hợp hiệu quả các đoạn nội dung đã truy xuất để cung cấp cho LLM model thông tin ngữ cảnh chính xác và cô đọng.
- Generation: Đánh giá và tái xếp hạng thông tin đã truy xuất, lựa chọn nội dung thiết yếu để tăng tính liên quan và tin cậy của phản hồi.
- Evaluation: Kiểm định chất lượng nội dung sinh ra theo các tiêu chí.
Tiếp theo, chúng ta sẽ khám phá một số kỹ thuật được áp dụng trong từng giai đoạn của Advanced RAG.
1. Indexing
Quá trình Indexing là bước thiết yếu, giúp cải thiện độ chính xác và hiệu quả của hệ thống sử dụng LLM. Indexing không chỉ đơn thuần là lưu trữ dữ liệu mà còn bao gồm việc tổ chức và tối ưu hóa dữ liệu để có thể dễ dàng hiểu và truy xuất thông tin cần thiết mà không mất đi ngữ cảnh quan trọng của dữ liệu.
Một số kỹ thuật trong quá trình Indexing:
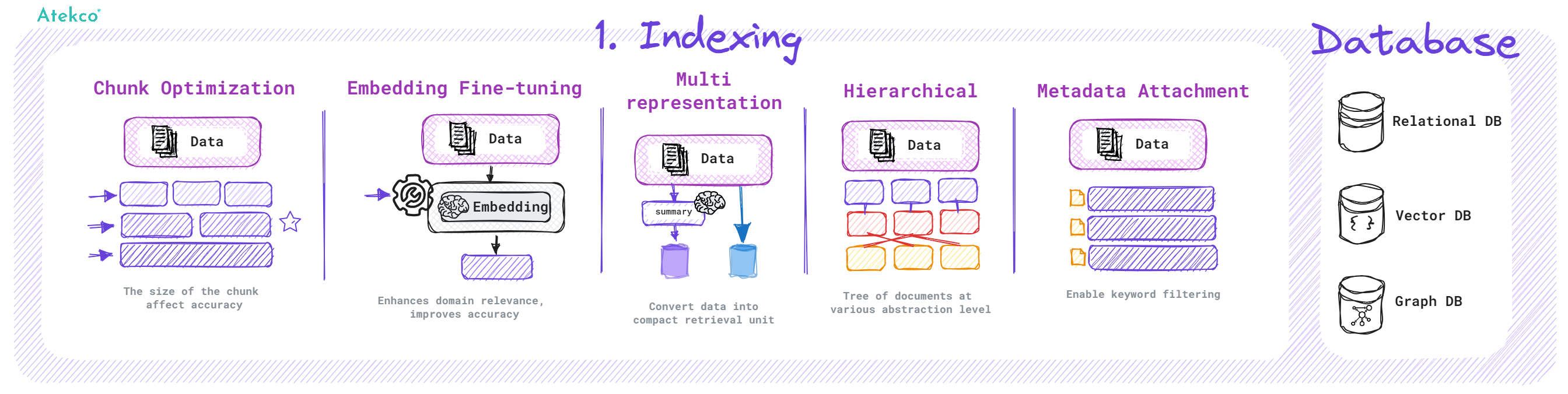
- Chunk Optimization: Tối ưu hóa kích thước và cấu trúc của các đoạn văn bản (chunk) để đảm bảo rằng chúng không quá lớn hay quá nhỏ, giúp duy trì ngữ cảnh cần thiết mà không vượt quá giới hạn độ dài của LLM.
- Embedding Fine-tuning: Tinh chỉnh embedding model giúp cải thiện khả năng hiểu ngữ nghĩa của dữ liệu được tạo index, qua đó tăng cường khả năng khớp nội dung truy xuất với yêu cầu của người dùng.
- Multi-Representation: Phương pháp này cho phép biến đổi tài liệu thành các đơn vị truy xuất gọn nhẹ như tóm tắt nội dung, giúp cải thiện độ chính xác và tốc độ của quá trình truy xuất khi người dùng cần thông tin cụ thể từ một tài liệu lớn.
- Hierarchical Indexing: Áp dụng mô hình phân cấp như RAPTOR để tổ chức dữ liệu thành các cấp độ tổng hợp khác nhau từ chi tiết đến tổng quát giúp cải thiện việc truy xuất thông tin dựa trên ngữ cảnh rộng hơn và chính xác hơn.
- Metadata Attachment: Thêm metadata vào từng chunk hoặc dữ liệu giúp tăng khả năng phân tích và phân loại thông tin, cho phép truy xuất dữ liệu một cách có hệ thống hơn, phù hợp với nhiều tình huống cụ thể.
2. Query Transformation & Query Routing
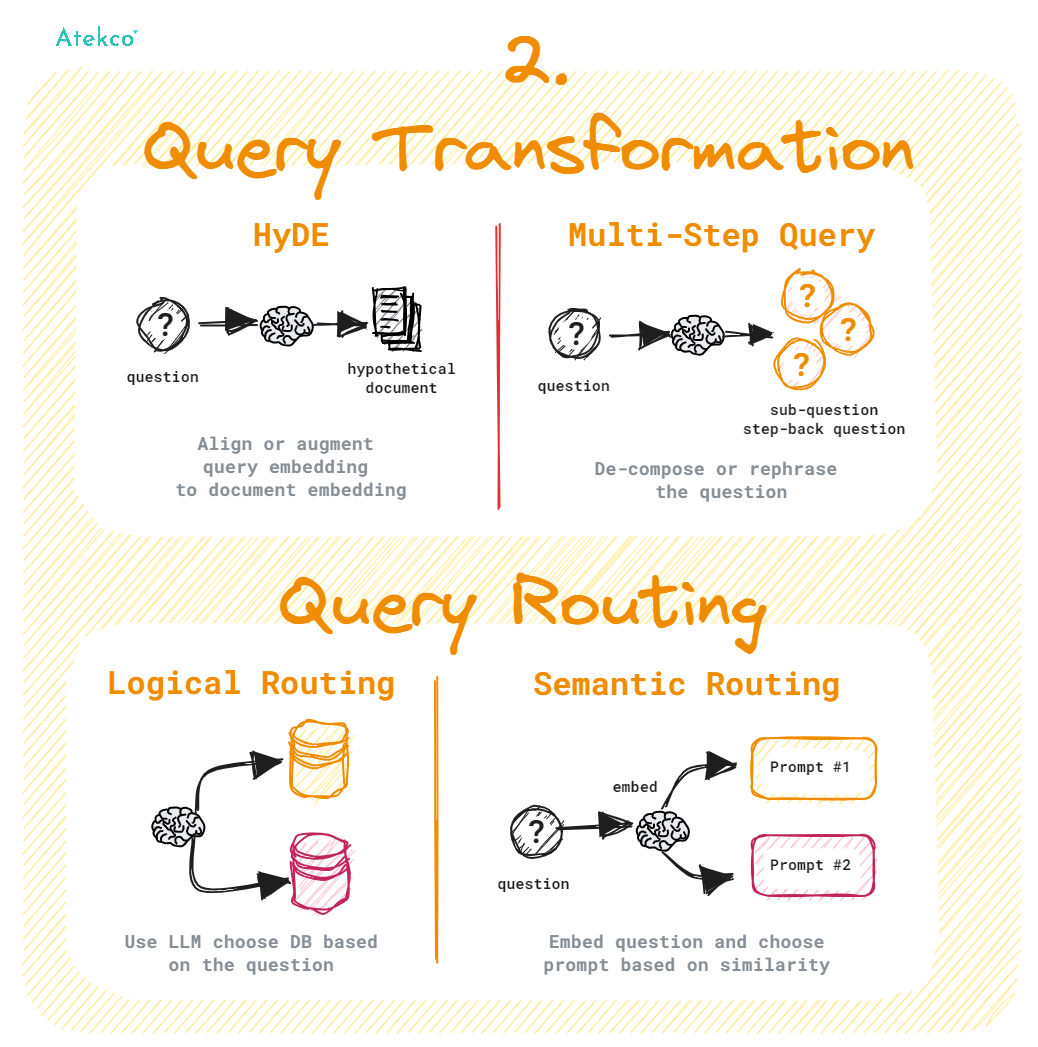
Quá trình Query Transformation là các kỹ thuật sử dụng mô hình LLM như một công cụ lý luận để chỉnh sửa đầu vào của người dùng nhằm cải thiện chất lượng truy xuất thông tin. LLM có thể chuyển đổi câu hỏi gốc thành các câu hỏi rõ ràng, dễ hiểu hơn, từ đó tăng khả năng tìm kiếm và truy xuất thông tin một cách hiệu quả.
Một số kỹ thuật trong quá trình Query Transformation:
- HyDE: Là một kỹ thuật đảo ngược trong đó LLM được yêu cầu sinh ra dữ liệu giả định dựa trên câu hỏi, sau đó sử dụng vector của dữ liệu này cùng với vector của câu hỏi để cải thiện chất lượng truy xuất thông tin tham khảo. Kỹ thuật này giúp nâng cao sự tương đồng ngữ nghĩa giữa câu hỏi và nội dung tham khảo được truy xuất, qua đó tăng cường độ chính xác và hiệu quả của quá trình truy vấn.
- Multi-Step Query: Là phương pháp phân rã câu hỏi phức tạp thành nhiều câu hỏi con đơn giản hơn, thực hiện truy xuất song song cho từng câu hỏi con này, và kết hợp các kết quả truy xuất lại với nhau. Điều này cho phép LLM tổng hợp và sinh ra câu phản hồi được chính xác hơn. Phương pháp này đặc biệt hữu ích trong các trường hợp không có thông tin trực tiếp về nội dung được hỏi.
Quá trình Query Routing là bước do LLM model thực hiện để xác định hành động tiếp theo dựa trên truy vấn của người dùng. Các lựa chọn có thể là tìm kiếm nội dung trong một tập dữ liệu cụ thể, hoặc thử nghiệm nhiều hướng tìm kiếm khác nhau và sau đó tổng hợp các kết quả lại thành một câu phản hồi thống nhất. Quá trình này giúp định hướng truy vấn đến nguồn dữ liệu phù hợp nhất, từ cơ sở dữ liệu vector cổ điển đến cơ sở dữ liệu đồ thị hoặc cơ sở dữ liệu quan hệ, hoặc thậm chí là các chỉ mục phân cấp khác nhau.
Một số kỹ thuật trong quá trình Query Routing:
- Logical Routing: Là kỹ thuật sử dụng logic để định hướng truy vấn đến nguồn dữ liệu phù hợp. Bằng cách phân tích cấu trúc và mục đích của câu hỏi, router lựa chọn index hoặc nguồn dữ liệu thích hợp nhất để thực hiện truy vấn. Điều này giúp tối ưu hóa quá trình truy xuất thông tin bằng cách đảm bảo rằng truy vấn được xử lý bởi nguồn dữ liệu có khả năng phản hồi chính xác nhất.
- Semantic Routing: Phương pháp này tận dụng ngữ nghĩa của câu hỏi để định hướng. Router phân tích ý nghĩa ngữ nghĩa của câu hỏi và định hướng nó đến index hoặc nguồn dữ liệu phù hợp, nhằm tăng khả năng tìm kiếm và truy xuất thông tin liên quan một cách chính xác. Phương pháp này đặc biệt hữu hiệu khi xử lý các truy vấn phức tạp, cần sự hiểu biết về ngữ cảnh và ý nghĩa của từng từ và cụm từ trong truy vấn.
3. Retrieval
Quá trình Retrieval là bước cốt lõi trong hệ thống RAG, tập trung vào việc lấy dữ liệu tham khảo từ các nguồn khác nhau để cung cấp ngữ cảnh và thông tin cần thiết cho LLM model thực hiện tạo sinh câu phản hồi.
Một số kỹ thuật trong quá trình Retrieval:
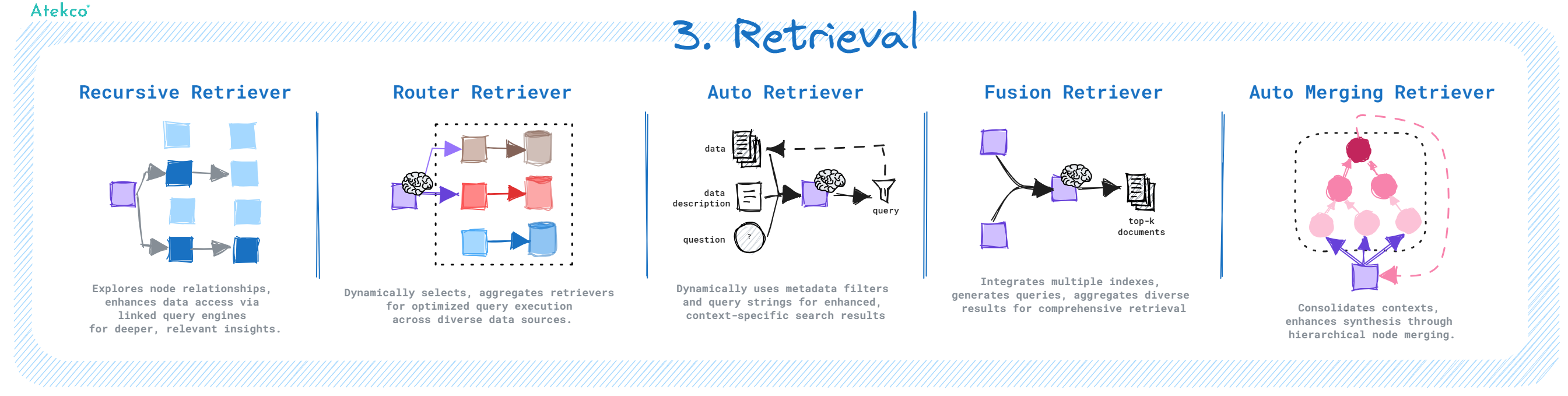
- Recursive Retriever: Là kỹ thuật cho phép truy xuất sâu vào các dữ liệu liên quan và thực hiện truy vấn thêm dữ liệu dựa trên kết quả truy vấn trước đó. Kỹ thuật này hữu ích trong các tình huống cần khám phá thông tin chi tiết hoặc chuyên sâu.
- Router Retriever: Là kỹ thuật sử dụng LLM để đưa ra quyết định động về nguồn dữ liệu hoặc công cụ truy vấn dữ liệu phù hợp cho mỗi truy vấn cụ thể.
- Auto Retriever: Phương pháp tự động truy vấn cơ sở dữ liệu bằng cách sử dụng LLM để xác định metadata để thực hiện filter hoặc tạo câu truy vấn phù hợp để truy xuất...
- Fusion Retriever: Kết hợp kết quả từ nhiều truy vấn và index khác nhau, giúp tối ưu hóa việc truy xuất thông tin và đảm bảo kết quả thu được là toàn diện và không bị trùng lặp, mang lại cái nhìn đa chiều cho quá trình truy xuất.
- Auto Merging Retriever: Khi có nhiều phân đoạn dữ liệu con được truy vấn, kỹ thuật này sẽ chuyển chúng thành phân đoạn dữ liệu cha, cho phép tập hợp các ngữ cảnh nhỏ lẻ thành một ngữ cảnh lớn hơn, hỗ trợ quá trình tổng hợp thông tin. Kỹ thuật này giúp cải thiện độ liên quan và tính toàn vẹn của ngữ cảnh.
4. Post-Retrieval
Quá trình Post-Retrieval là nơi kết quả truy xuất được tinh chỉnh thông qua việc lọc (filter), sắp xếp lại (reranking), hoặc biến đổi. Mục đích của quá trình này là để chuẩn bị và cải thiện ngữ cảnh trước khi đưa vào LLM model để sinh ra câu phản hồi cuối cùng, đảm bảo thông tin được cung cấp cho LLM là chính xác và hiệu quả nhất.
Một số kỹ thuật trong quá trình Post-Retrieval:
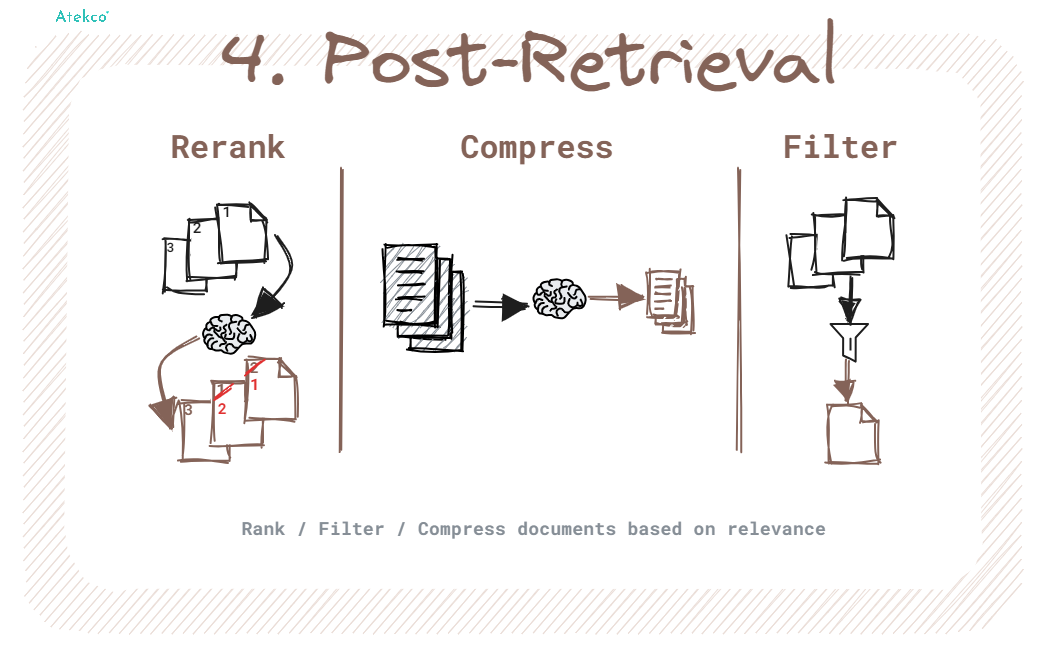
- Rerank: Tái sắp xếp các đoạn văn bản đã truy xuất để những kết quả liên quan nhất xuất hiện đầu tiên, giúp cải thiện độ chính xác của thông tin. Reranking không chỉ giúp giảm số lượng tài liệu cần đưa vào LLM model mà còn hoạt động như một bộ lọc để xử lý ngôn ngữ một cách chính xác hơn.
- Compress: Giảm bớt phần ngữ cảnh dư thừa và không cần thiết, loại bỏ các thông tin nhiễu để tăng cường nhận thức của LLM về các thông tin chính. Compress giúp tối ưu hóa độ dài của ngữ cảnh mà LLM có thể xử lý, từ đó nâng cao chất lượng của câu phản hồi bằng cách tập trung vào những thông tin quan trọng.
- Filter: Chọn lọc nội dung trước khi đưa vào LLM, loại bỏ những tài liệu hoặc thông tin không liên quan hoặc có độ chính xác thấp. Kỹ thuật này giúp đảm bảo rằng chỉ những thông tin phù hợp và chất lượng cao mới được sử dụng, từ đó cải thiện độ chính xác và độ tin cậy của câu phản hồi.
5. Generation
Quá trình Generation là giai đoạn LLM model sinh ra câu phản hồi dựa trên thông tin đã được truy xuất và xử lý từ các bước trước. Mục tiêu của quá trình này là tạo ra câu phản hồi chính xác và có liên quan cao đối với truy vấn ban đầu của người dùng.
Chất lượng của quá trình này phụ thuộc nhiều vào LLM model được chọn. Tuy nhiên, hệ thống có thể áp dụng một số kỹ thuật để tăng chất lượng cho kết quả của quá trình Generation:
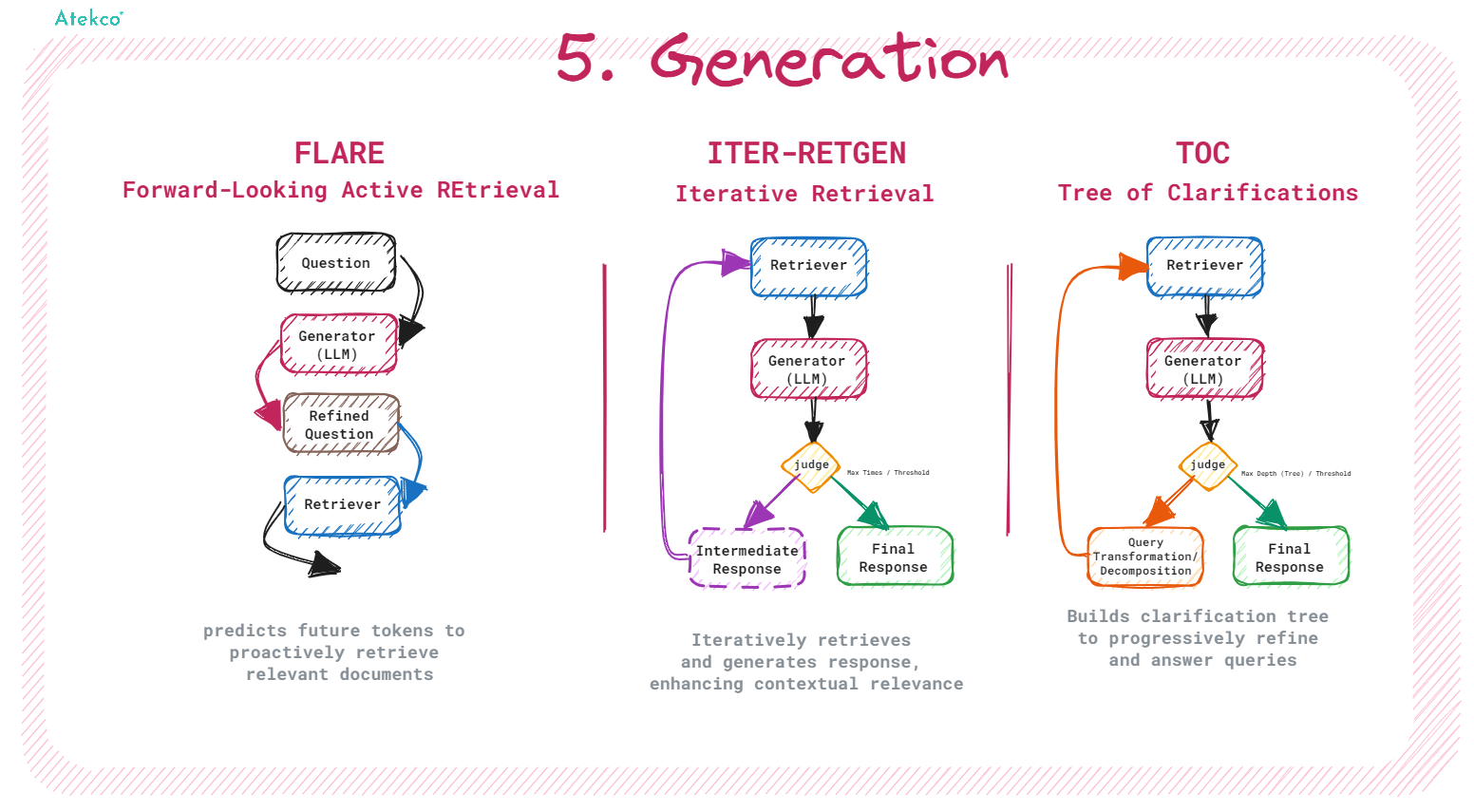
- FLARE: FLARE là phương pháp dựa trên kỹ thuật Prompt Engineering để kiểm soát khi nào mô hình ngôn ngữ lớn (LLM) nên thực hiện truy xuất dữ liệu. Kỹ thuật này giúp đảm bảo rằng LLM chỉ tiến hành truy xuất khi thiếu thông tin thiết yếu, nhằm tránh việc thu thập dữ liệu không cần thiết hoặc không phù hợp. Quá trình này liên tục điều chỉnh câu hỏi và kiểm tra các từ khóa có xác suất xuất hiện thấp; nếu những từ này xuất hiện, hệ thống sẽ truy xuất các tài liệu liên quan để cải thiện và tinh chỉnh câu phản hồi, qua đó nâng cao độ chính xác và độ liên quan của phản hồi cuối cùng.
- ITER-RETGEN: ITER-RETGEN là kỹ thuật lặp đi lặp lại quá trình Generation dựa trên thông tin đã truy xuất. Mỗi vòng lặp sử dụng kết quả từ lần lặp trước làm ngữ cảnh cụ thể để giúp truy xuất kiến thức liên quan hơn, từ đó liên tục cải thiện chất lượng của câu phản hồi.
- ToC (Tree of Clarifications): ToC là phương pháp thực hiện truy vấn một cách đệ quy để làm rõ câu hỏi ban đầu. Trong quá trình này, mỗi bước hỏi-đáp đều thực hiện đánh giá dựa trên truy vấn hiện tại để sinh ra một câu hỏi cụ thể hơn. Quá trình này giúp làm sáng tỏ các vấn đề mơ hồ trong câu hỏi ban đầu, qua đó cải thiện độ chính xác và chi tiết của câu phản hồi.
6. Evaluation
Quá trình Evaluation là bước thiết yếu để đảm bảo rằng cả quá trình RAG đều đạt hiệu quả cao và chính xác. Đánh giá này phản ánh khả năng của hệ thống trong việc đáp ứng các yêu cầu của người dùng và xử lý các câu hỏi phức tạp.

Các tiêu chí đánh giá chất lượng câu phản hồi:
- Context Relevance: Đánh giá độ chính xác và cụ thể của ngữ cảnh đã truy xuất, đảm bảo rằng thông tin liên quan được lựa chọn một cách chính xác và giảm thiểu chi phí xử lý cho nội dung không cần thiết.
- Answer Faithfulness: Đảm bảo các câu phản hồi sinh ra phải nhất quán với ngữ cảnh đã truy xuất, tăng cường độ tin cậy của câu phản hồi đối với người dùng.
- Answer Relevance: Yêu cầu các câu phản hồi được sinh ra phải có liên quan trực tiếp đến câu hỏi đã đặt ra. Điểm này đánh giá khả năng của hệ thống trong việc tập trung vào những thông tin quan trọng nhất đối với người dùng.
Các tiêu chí đánh giá khả năng của hệ thống:
- Noise Robustness: Đánh giá khả năng của hệ thống trong việc xử lý các tài liệu có liên quan đến câu hỏi nhưng thiếu thông tin có giá trị. Điều này quan trọng để đảm bảo rằng hệ thống không bị phân tâm bởi thông tin nhiễu.
- Negative Rejection: Đánh giá khả năng của hệ thống trong việc không đưa ra phản hồi khi các tài liệu truy xuất không chứa kiến thức cần thiết để phản hồi câu hỏi. Điều này giúp ngăn ngừa việc cung cấp thông tin sai lệch hoặc không chính xác.
- Information Integration: Đánh giá khả năng của hệ thống trong việc tổng hợp thông tin từ nhiều tài liệu để giải quyết các câu hỏi phức tạp. Khả năng này cần thiết cho những trường hợp cần hiểu và phân tích thông tin đa chiều.
- Counterfactual Robustness: Đánh giá khả năng của hệ thống trong việc nhận biết và bỏ qua các thông tin sai trái đã biết trong tài liệu. Điều này giúp tăng cường độ chính xác và độ tin cậy của thông tin được sinh ra.
Thử nghiệm với LlamaIndex
Hiện nay, LlamaIndex là công cụ lý tưởng để triển khai Advanced RAG. LlamaIndex cung cấp khả năng xử lý dữ liệu phức tạp và đa dạng, hỗ trợ thực hiện các kỹ thuật Advanced RAG dễ dàng và hiệu quả.
Demo dưới đây sẽ yêu cầu hệ thống phân tích câu hỏi của người dùng theo thông tin mô tả của từng Node dữ liệu và lựa chọn Node phù hợp để truy vấn. Nếu câu hỏi là về một tỷ phú cụ thể, hệ thống sẽ sử dụng Node thứ nhất chứa danh sách các tỷ phú để truy vấn thông tin. Còn khi câu hỏi là về một vấn đề tổng quát hơn, hệ thống sẽ sử dụng Node thứ hai chứa thông tin thống kê để trả lời.
Demo sử dụng LlamaIndex để hiện thực hóa kỹ thuật Recursive Retriever:
import camelot
from typing import List
from llama_index.llms.azure_openai import AzureOpenAI
from llama_index.embeddings.azure_openai import AzureOpenAIEmbedding
from llama_index.core import Settings, VectorStoreIndex
from llama_index.core.schema import IndexNode
from llama_index.experimental.query_engine import PandasQueryEngine
from llama_index.readers.file import PyMuPDFReader
from llama_index.core.retrievers import RecursiveRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core import get_response_synthesizer
# API and model configuration
api_key = ""
azure_endpoint = ""
api_version = ""
# Initialize
llm = AzureOpenAI(model="gpt-35-turbo", deployment_name="", api_key=api_key, azure_endpoint=azure_endpoint, api_version=api_version,)
embed_model = AzureOpenAIEmbedding(model="text-embedding-ada-002", deployment_name="", api_key=api_key, azure_endpoint=azure_endpoint, api_version=api_version,)
Settings.llm = llm
Settings.embed_model = embed_model
# PDF and Table Extraction
file_path = "billionaires_page.pdf"
reader = PyMuPDFReader()
docs = reader.load(file_path)
# use camelot to parse tables
def get_tables(path: str, pages: List[int]):
table_dfs = []
for page in pages:
table_list = camelot.read_pdf(path, pages=str(page))
table_df = table_list[0].df
table_df = (
table_df.rename(columns=table_df.iloc[0])
.drop(table_df.index[0])
.reset_index(drop=True)
)
table_dfs.append(table_df)
return table_dfs
table_dfs = get_tables(file_path, pages=[3, 29])
# Data Handling
df_query_engines = [PandasQueryEngine(df, llm=llm) for df in table_dfs]
doc_nodes = Settings.node_parser.get_nodes_from_documents(docs)
# Nodes and Indexing
summaries = [
"This node provides information about the world's richest billionaires in 2023",
"This node provides information on the number of billionaires and their combined net worth from 2000 to 2023."
]
df_nodes = [IndexNode(text=summary, index_id=f"pandas{idx}") for idx, summary in enumerate(summaries)]
vector_index = VectorStoreIndex(doc_nodes + df_nodes)
vector_retriever = vector_index.as_retriever(similarity_top_k=1)
# Retrieval and Querying
recursive_retriever = RecursiveRetriever("vector", retriever_dict={"vector": vector_retriever}, query_engine_dict={f"pandas{idx}": engine for idx, engine in enumerate(df_query_engines)}, verbose=True)
response_synthesizer = get_response_synthesizer(response_mode="compact")
query_engine = RetrieverQueryEngine.from_args(recursive_retriever, response_synthesizer=response_synthesizer)
# Example Queries
response1 = query_engine.query("What's the net worth of the second richest billionaire in 2023?")
response2 = query_engine.query("How many billionaires were there in 2009?")
print(response1, response2)
Đoạn code trên được tạo theo hướng dẫn Recursive Retriever + Query Engine Demo. Thông tin về billionaires_page.pdf bạn có thể trích xuất từ trang The World's Billionaires.
Đoạn code trên cho output như sau:
Retrieving with query id None: What's the net worth of the second richest billionaire in 2024?
Retrieved node with id, entering: pandas0
Retrieving with query id pandas0: What's the net worth of the second richest billionaire in 2024?
Got response: $195 billion
Retrieving with query id None: How many billionaires were there in 2009?
Retrieved node with id, entering: pandas1
Retrieving with query id pandas1: How many billionaires were there in 2009?
Got response: 793
Trong demo trên, LlamaIndex cung cấp lớp RecursiveRetriever và nhiều công cụ khác để phân tích và trả lời các câu hỏi từ dữ liệu trong tệp PDF một cách thuận tiện và nhanh chóng. Sự kết hợp của các công cụ này không chỉ tăng cường hiệu quả truy xuất thông tin mà còn cải thiện độ chính xác của các câu trả lời.
Hãy theo dõi để khám phá thêm về những khả năng mà LlamaIndex có thể mang lại trong các bài viết tiếp theo.

