Thử nghiệm vui vẻ: Fine-tune mô hình ngôn ngữ nhỏ với LoRA
Mình dùng kỹ thuật LoRA để fine‑tune mô hình Qwen2.5‑Coder (1.5B tham số), nhằm biến những mô tả ngắn thành CSS đúng chuẩn phong cách của team. Cùng xem mô hình nhỏ này có ‘bắt sóng’ đúng gu không nhé!

Sự xuất hiện của AI đã tạo ra một bước thay đổi lớn trong cách lập trình viên làm việc. Những công cụ như ChatGPT hay GitHub Copilot có thể hỗ trợ viết code từ mô tả ngắn, gợi ý sửa lỗi, thậm chí tạo tài liệu hoặc refactor lại code một cách nhanh chóng.
Tuy nhiên, khi chỉ sử dụng các mô hình ngôn ngữ lớn thông qua API như ChatGPT, Claude hay Gemini, một số hạn chế sẽ dần xuất hiện:
- Mô hình không hiểu phong cách viết code hoặc quy ước của từng nhóm phát triển
- Chi phí sử dụng tăng dần theo số lượng request
- Khó đảm bảo tính riêng tư của dữ liệu nội bộ
Chẳng hạn với frontend, AI được yêu cầu tạo một UI component, nhưng kết quả lại chưa đúng với phong cách của team.
Giải pháp hiệu quả nằm ở việc fine-tune một mô hình ngôn ngữ nhỏ bằng kỹ thuật PEFT - cụ thể là LoRA. Cách làm này giúp xây dựng một AI assistant tùy chỉnh, hiểu đúng ngữ cảnh và phong cách dự án, tiết kiệm chi phí và giữ toàn bộ dữ liệu được riêng tư.
Hiểu cơ bản về Fine-tuning, PEFT và LoRA
Fine-tuning: 'Dạy thêm' cho mô hình đã có kiến thức
Hình dung một đầu bếp đã được đào tạo bài bản về kỹ thuật nấu ăn và biết cách chế biến nhiều loại món cơ bản. Khi muốn họ nấu đúng chuẩn ẩm thực Việt Nam, chỉ cần hướng dẫn thêm về gia vị và cách chế biến đặc trưng. Đó chính là fine-tuning: điều chỉnh một mô hình ngôn ngữ đã được huấn luyện sẵn để hiểu rõ hơn một lĩnh vực hoặc một tác vụ cụ thể. So với việc huấn luyện từ đầu vốn tốn hàng tỷ token, nhiều GPU và chi phí lớn thì fine-tuning cần ít tài nguyên hơn.
PEFT (Parameter-Efficient Fine-Tuning)
Tuy nhiên, ngay cả full fine-tuning cũng yêu cầu cập nhật hàng tỷ tham số, khiến việc tinh chỉnh mô hình lớn (như 7B) trở nên khó khăn với người dùng phổ thông chỉ sở hữu các thiết bị như laptop bình thường.
PEFT (Parameter-Efficient Fine-Tuning) được phát triển để giải quyết vấn đề này. Thay vì cập nhật toàn bộ tham số của mô hình, phương pháp này chỉ điều chỉnh một lượng nhỏ tham số hoặc bổ sung các lớp tham số nhỏ gọn gắn vào mô hình gốc nhưng vẫn đạt được hiệu quả học tốt mà chi phí thì giảm đáng kể.
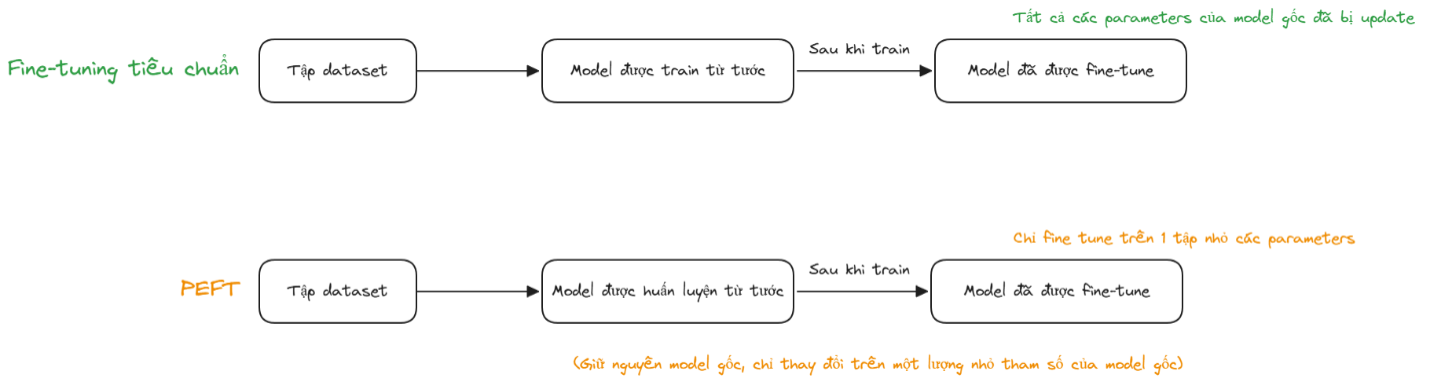
So sánh giữa fine-tuning tiêu chuẩn và kỹ thuật PEFT
LoRA (Low-Rank Adaptation)
Trong các kỹ thuật PEFT, LoRA (Low-Rank Adaptation) là phương pháp phổ biến và hiệu quả. Thay vì tinh chỉnh toàn bộ mô hình, LoRA chỉ tác động lên một lượng nhỏ tham số, giúp tiết kiệm tài nguyên đáng kể mà vẫn đạt hiệu quả cao.
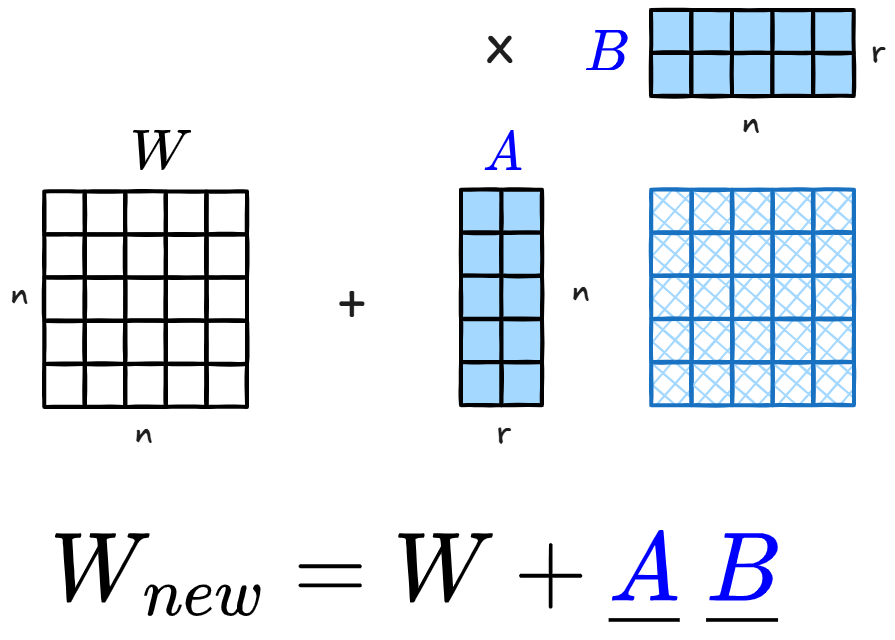
Minh họa đơn giản phương pháp tính toán của LoRA
Khi fine-tune, mô hình cập nhật trọng số ban đầu W thành:
W = W + ΔW
Ở full fine-tuning, toàn bộ ΔW (toàn bộ tham số) đều được huấn luyện. Với LoRA, phần thay đổi này được xấp xỉ bằng tích của hai ma trận nhỏ hơn:
ΔW ≈ A × B
Nếu ΔW là ma trận 1000×1000, thì thay vì phải cập nhật 1.000.000 tham số, LoRA chỉ cần:
- A: 1000 x r
- B: r x 1000
Giá trị r (gọi là rank) xác định số chiều mà hai ma trận nhỏ A và B sử dụng để biểu diễn phần thay đổi của trọng số của mô hình gốc. Với r = 8 (rank = 8), tổng số tham số cần train chỉ còn:
Tổng tham số = (1000 x 8) + (8 x 1000) = 16,000
Điều này tương đương ≈1,6% so với full fine-tuning, giảm rất nhiều mà mô hình vẫn học được các điều chỉnh cần thiết.
Fine-tune small language model thành CSS Assistant
Sau khi nắm cơ chế của LoRA, mình thử áp dụng nó vào một bài toán trong frontend: tạo CSS cho component đơn giản.
Việc viết CSS cho button, card hay input nghe có vẻ đơn giản, nhưng những thay đổi nhỏ về màu sắc, spacing hay kích thước lại khiến thao tác thủ công tốn thời gian.
Giải pháp cho vấn đề sẽ là fine-tune một small language model thành CSS Generation Assistant - trợ lý có thể sinh CSS đúng phong cách, tiêu chuẩn của cá nhân hoặc team chỉ từ mô tả ngắn như "blue button, round border, large size".
Mục tiêu là giúp mô hình hiểu mô tả tự nhiên và sinh ra CSS thống nhất với phong cách thiết kế định sẵn.
Chọn model phù hợp
Khi chọn mô hình để fine-tune, có hai loại là base model và instruct model.
- Base model là phiên bản gốc của mô hình ngôn ngữ, được huấn luyện trên khối lượng lớn dữ liệu văn bản để học cấu trúc và ngữ nghĩa của ngôn ngữ. Nó có khả năng hiểu ngữ cảnh và sinh văn bản tự nhiên, nhưng chưa được dạy cách làm theo hướng dẫn cụ thể của người dùng. Base model có thể trả lời bằng lời giải thích hoặc không tuân thủ đúng định dạng mà ta yêu cầu.
- Ngược lại, instruct model được huấn luyện thêm với các cặp dữ liệu “instruction - response”. Nhờ đó, mô hình sẽ làm tốt hơn trong việc hiểu ý định của người dùng và phản hồi đúng theo chỉ dẫn một cách nhất quán. Với cùng prompt trên, một instruct model sẽ sinh ra đoạn CSS theo đúng định dạng, yêu cầu, và phong cách một cách chính xác hơn.
Vì mục tiêu của mình là tạo ra một trợ lý AI có thể hiểu và sinh CSS code theo các chỉ dẫn nên instruct model sẽ là lựa hợp với mình.
Bài toán của mình liên quan đến sinh code nên mình chọn Qwen2.5-Coder (1.5B tham số), là một mô hình nhỏ đã được huấn luyện với dữ liệu lập trình, bao gồm cả CSS. Nhờ có kiến thức nền về code, quá trình fine-tune có thể tập trung vào việc điều chỉnh phong cách sinh code và khả năng phản hồi theo yêu cầu, thay vì phải huấn luyện lại kiến thức cơ bản.
Chuẩn bị dataset: Bước quan trọng nhất trong fine-tune
Chuẩn bị dataset là một trong những bước quan trọng nhất khi fine-tune mô hình, vì nó là yếu tố quyết định chất lượng đầu ra của mô hình. Với bài toán "CSS Generation" chưa có dataset sẵn, mình phải tự tạo dữ liệu huấn luyện.
Scope
Bước xác định scope rất quan trọng, vì nó ảnh hưởng trực tiếp đến độ phức tạp của bài toán và số lượng mẫu cần chuẩn bị. Mình sẽ bắt đầu xác định rõ phạm vi mà mô hình cần học bằng cách trả lời các câu hỏi như:
- Về màu sắc, sẽ có bao nhiêu màu được hỗ trợ? Càng nhiều màu, không gian học càng lớn và mô hình càng cần nhiều mẫu hơn.
- Về số lượng component, liệu chỉ gồm các phần tử đơn lẻ (button, card, input, badge) hay bao gồm cả các component kết hợp (ví dụ: card có chứa button)?
- Các biến thể (variants) của component như thế nào? Ví dụ button có thể có kiểu primary, outline, ghost, text.
- Có cần bao gồm các trạng thái (states) như hover, focus, disabled hay không?
- Phần miêu tả style sẽ bao gồm những thuộc tính nào - ví dụ "large" được định nghĩa bởi font-size, padding ra sao, và liệu giữa các component có thống nhất quy ước kích thước không?
Mình sẽ xác định như sau:
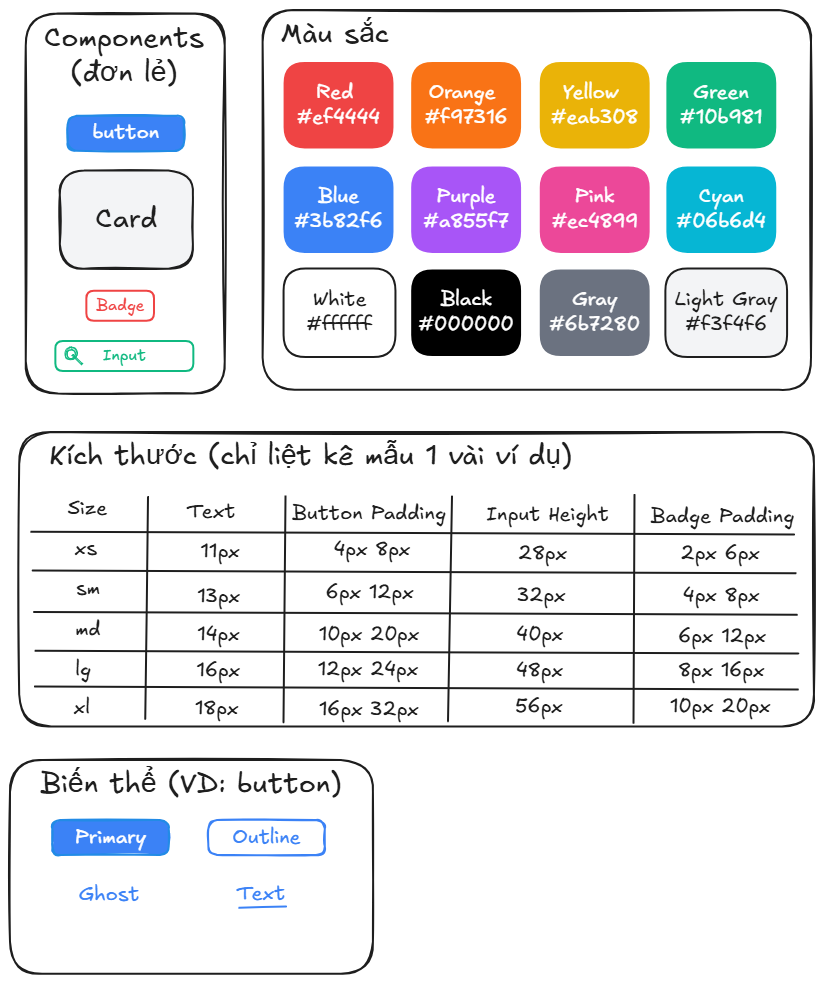
Xác định rõ phạm vi mà mô hình cần học là một bước rất quan trọng
Ngoài ra, mình cũng định nghĩa quy tắc format output (tên class, thứ tự thuộc tính, quy ước viết CSS, …) để model học được phong cách thống nhất.
Trong phạm vi thử nghiệm này, mình đã tạo khoảng 350 mẫu dữ liệu thủ công để huấn luyện mô hình.
Tạo các mẫu
Sau khi xác định phạm vi, mình bắt đầu tạo các mẫu huấn luyện. Mục tiêu là đảm bảo đa dạng và cân bằng: nếu một thuộc tính (màu, kích thước, ...) xuất hiện quá nhiều, model sẽ dễ bị học thiếu hay không nắm được pattern. Vì vậy, mình cố gắng phân bố đều các thuộc tính trong dataset.
Bên cạnh đó, phần mô tả đầu vào cũng được viết bằng nhiều cách khác nhau để tránh việc model 'học vẹt':
- "Create small button with primary style"
- "Generate primary button and small size"
- "Make a primary small button"
Ngoài ra, mình còn tạo các mẫu kết hợp nhiều thuộc tính để tăng độ phong phú:
- "primary small button with medium border radius"
- "button with square border and variant secondary in large size"
- "rounded blue ghost button with hover effect"
Và cả các mô tả ngắn, mơ hồ để mô phỏng cách người dùng thật tương tác:
- "generate for me a button"
- "primary button"
Tạo script để train model (dùng Jupyter Notebook trên Google Colab)
Bước đầu tiên là cài đặt các thư viện cần thiết để thực hiện quá trình fine-tune mô hình:
# Cài đặt các thư viện cần thiết cho fine-tuning
!pip install -q -U transformers peft accelerate trl datasets
# Import các thư viện cần thiết
import json
import torch
from datasets import Dataset
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
from peft import LoraConfig, get_peft_model, PeftModel
from trl import SFTTrainer
import random
Tiếp theo, load các dataset và chuyển chúng về định dạng phù hợp với model:
# Tải và load các dataset
dataset_files = [
'dataset.json',
]
all_data = []
for file in dataset_files:
with open(file, 'r', encoding='utf-8') as f:
all_data.extend(json.load(f))
# Tải tokenizer từ mô hình Qwen2.5-Coder
model_name = "Qwen/Qwen2.5-Coder-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# Định dạng dữ liệu sử dụng chat template của Qwen
def format_instruction(sample, tokenizer):
# Tạo cấu trúc messages với system, user, assistant
messages = [
{"role": "system", "content": "You are a CSS code generator. Generate clean, professional CSS code based on user descriptions."},
{"role": "user", "content": sample['input']},
{"role": "assistant", "content": sample['output']}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
return {"text": text}
# Định dạng toàn bộ dữ liệu
formatted_data = [format_instruction(sample, tokenizer) for sample in all_data]
Sau khi có dữ liệu đã định dạng, mình chia thành hai phần: 90% để huấn luyện và 10% để đánh giá, vì tập dữ liệu không quá lớn.
# Chia dữ liệu thành tập train và validation (90/10)
random.seed(42)
random.shuffle(formatted_data)
split_idx = int(len(formatted_data) * 0.9)
train_dataset = Dataset.from_list(formatted_data[:split_idx])
val_dataset = Dataset.from_list(formatted_data[split_idx:])
Tiếp theo, load mô hình gốc để fine-tune:
# Tải model gốc (từ Hugging Face)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
Tiếp đến là cấu hình LoRA và các training arguments. Chúng ta sẽ không có một bộ hyperparameter 'chuẩn' cho mọi bài toán - chúng cần được thử nghiệm và điều chỉnh tùy theo dữ liệu và mục tiêu. Dưới đây là thiết lập mà mình thấy hoạt động ổn định cho tập dữ liệu hiện tại:
# Cấu hình LoRA
lora_config = LoraConfig(
r=64, # Rank của LoRA (càng cao = càng nhiều khả năng học, càng tốn bộ nhớ)
lora_alpha=64, # Hệ số scaling của LoRA (thường gấp 2 lần rank)
target_modules=[ # Các layer của model gốc sẽ được fine-tune
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj"
],
)
# Áp dụng LoRA vào model gốc
model = get_peft_model(model, lora_config)
# Cấu hình tham số huấn luyện
output_dir = "./qwen-css-lora"
training_args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=10, # Số epoch huấn luyện
per_device_train_batch_size=2, # Batch size trên mỗi GPU
gradient_accumulation_steps=16, # Tích lũy gradient (Giải thích rõ hơn ở phần tiếp theo)
learning_rate=5e-5, # Tốc độ học (learning rate)
lr_scheduler_type="cosine", # LR giảm dần theo hàm cosine
logging_steps=10, # Log sau mỗi 10 steps
eval_strategy="steps", # Đánh giá theo steps
eval_steps=20, # Đánh giá sau mỗi 20 steps
save_strategy="epoch", # Lưu model sau mỗi epoch
fp16=True,
optim="adamw_torch", # Optimizer AdamW chuẩn
report_to="none"
)
Khi đã có cấu hình phù hợp, ta bắt đầu huấn luyện:
# Khởi tạo trainer với các tham số đã cấu hình
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=val_dataset,
args=training_args,
)
# Bắt đầu quá trình huấn luyện mô hình
trainer.train()
Cuối cùng, lưu lại mô hình đã fine-tune và tokenizer để sử dụng sau này:
# Lưu LoRA adapter đã fine-tune và tokenizer
trainer.model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
Fine tune các hyperparameter
Ở phần này, mình sẽ là phần giải thích rõ hơn về các siêu tham số (hyperparameter) quan trọng trong quá trình fine-tune.
1. LoRa hyperparameter
r (LoRA rank)
r là siêu tham số cốt lõi của LoRa giúp mô hình có thể cập nhật kiến thức mới mà không làm thay đổi toàn bộ trọng số mô hình gốc.
Giá trị của r:
- r thấp: mô hình khó học được các đặc trưng phức tạp..
- r cao : mô hình dễ overfit (mô hình ghi nhớ dữ liệu thay vì học quy luật) và tốn nhiều tài nguyên .
Bắt đầu với r = 16. Nếu mô hình chưa ổn định, tăng dần lên 32 hoặc 64 hoặc hơn nữa.
lora_alpha
lora_alpha điều chỉnh mức độ ảnh hưởng của các trọng số LoRA lên mô hình gốc. Hệ số này thường được chọn theo bằng r hoặc gấp đôi r (r*2) để có kết quả tốt nhất
Giá trị của lora_alpha:
- lora_alpha = r: Cân bằng, mô hình giữ được kiến thức gốc và học thêm một cách ổn định.
- lora_alpha = 2×r: Kiến thức mới có trọng số lớn hơn, phù hợp khi muốn mô hình thay đổi hành vi rõ ràng hơn.
Nếu mô hình sau fine-tune vẫn chưa thể hiện tốt trong domain mới, tăng alpha lên 2×r. Nếu kết quả trở nên bất ổn (overfitting, dấu hiệu mô hình quên kiến thức gốc), giảm lại bằng r.
target_modules - Chọn các lớp cần áp dụng LoRA
Tham số này xác định những layer của mô hình gốc sẽ được tinh chỉnh bằng LoRA, có thể là Attention, MLP, hoặc cả hai.
- Attention: q_proj, k_proj, v_proj, o_proj
- MLP: gate_proj, up_proj, down_proj
Thông thường, nên áp dụng LoRA cho tất cả các layer chính (q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj) để đạt hiệu quả fine-tune tốt nhất.
2. Training hyperparameter
Sau khi đã điều chỉnh các siêu tham số của LoRA, bước tiếp theo là cần tinh chỉnh các tham số huấn luyện.
num_train_epochs - Số vòng huấn luyện
Tham số này chỉ định số vòng lặp mà mô hình được huấn luyện trên toàn bộ tập dữ liệu.
- Nếu quá ít, mô hình có thể chưa học đủ (underfitting).
- Nếu quá nhiều, mô hình có thể học quá mức và nhớ dữ liệu huấn luyện (overfitting).
per_device_train_batch_size & gradient_accumulation_steps - Kích thước batch size thực tế
per_device_train_batch_size là số lượng mẫu dữ liệu mà mô hình xử lý cùng lúc trên mỗi GPU, giá trị càng lớn thì càng cần nhiều bộ nhớ GPU hơn.
gradient_accumulation_steps giúp 'giả lập' một batch lớn hơn bằng cách gộp nhiều batch nhỏ lại trước khi cập nhật trọng số của mô hình. Nhờ vậy, chúng ta vẫn có thể đạt hiệu quả tương tự như huấn luyện với batch lớn - ngay cả khi GPU không đủ RAM.
Kích thước batch size thực tế (effective batch size) được tính bằng:
effective batch size = per_device_train_batch_size x gradient_accumulation_steps
Batch size lớn giúp huấn luyện nhanh và ổn định hơn, nhưng có thể khiến mô hình hội tụ đến điểm cực tiểu kém tổng quát và hoạt động kém hơn khi gặp dữ liệu chưa thấy qua; ngược lại, batch size nhỏ giúp mô hình có xu hướng khái quát hóa và hoạt động tốt hơn trên dữ liệu mới chưa từng thấy, nhưng huấn luyện chậm hơn.
learning_rate - Tốc độ cập nhật trọng số
Tham số này điều chỉnh tốc độ cập nhật trọng số của mô hình sau mỗi bước học.
- Learning rate quá cao: mô hình cập nhật trọng số bằng những bước quá lớn, bỏ lỡ và không hội tụ được tại điểm tối ưu để cho ra kết quả tốt nhất.
- Learning rate quá thấp: mô hình học rất chậm vì mỗi lần cập nhật quá nhỏ, khiến thời gian huấn luyện kéo dài và dễ dừng ở một kết quả chưa tốt nhất.
Tóm lại, không có một công thức cố định cho mọi trường hợp; điều quan trọng là phải thử kết hợp tinh chỉnh các hyperparameter đến khi tìm được một thiết lập phù hợp cho kết quả đạt tiêu chuẩn được đề ra.
Để có thể hiểu tốt hơn về các tham số và cách hoạt động sâu hơn của chúng, bạn có thể truy cập vào bài viết này để tham khảo thêm.
Sử dụng model đã fine-tune
Sau khi quá trình fine-tune hoàn tất, mô hình có thể được sử dụng như một "CSS assistant" - chỉ cần nhập mô tả (prompt), mô hình sẽ sinh ra đoạn mã CSS tương ứng.
# Tải lại mô hình base
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
# Load LoRA adapter đã fine-tune
test_model = PeftModel.from_pretrained(base_model, output_dir)
test_model.eval() # Chuyển sang chế độ evaluation để tắt chế độ training
# Hàm để generate CSS từ prompt
def generate_css(prompt, model, tokenizer, max_length=1024):
# Tạo messages với system prompt và user prompt
messages = [
{"role": "system", "content": "You are a CSS code generator. Generate clean, professional CSS code based on user descriptions."},
{"role": "user", "content": prompt}
]
# Áp dụng chat template
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate text từ model
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_length,
temperature=0.1,
pad_token_id=tokenizer.eos_token_id
)
# Decode output và trả về kết quả
generated = tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
return generated.strip()
# Các prompt để test model
test_prompts = [
"Create a large blue button with rounded corners and hover effect",
"Design a small red badge with white text",
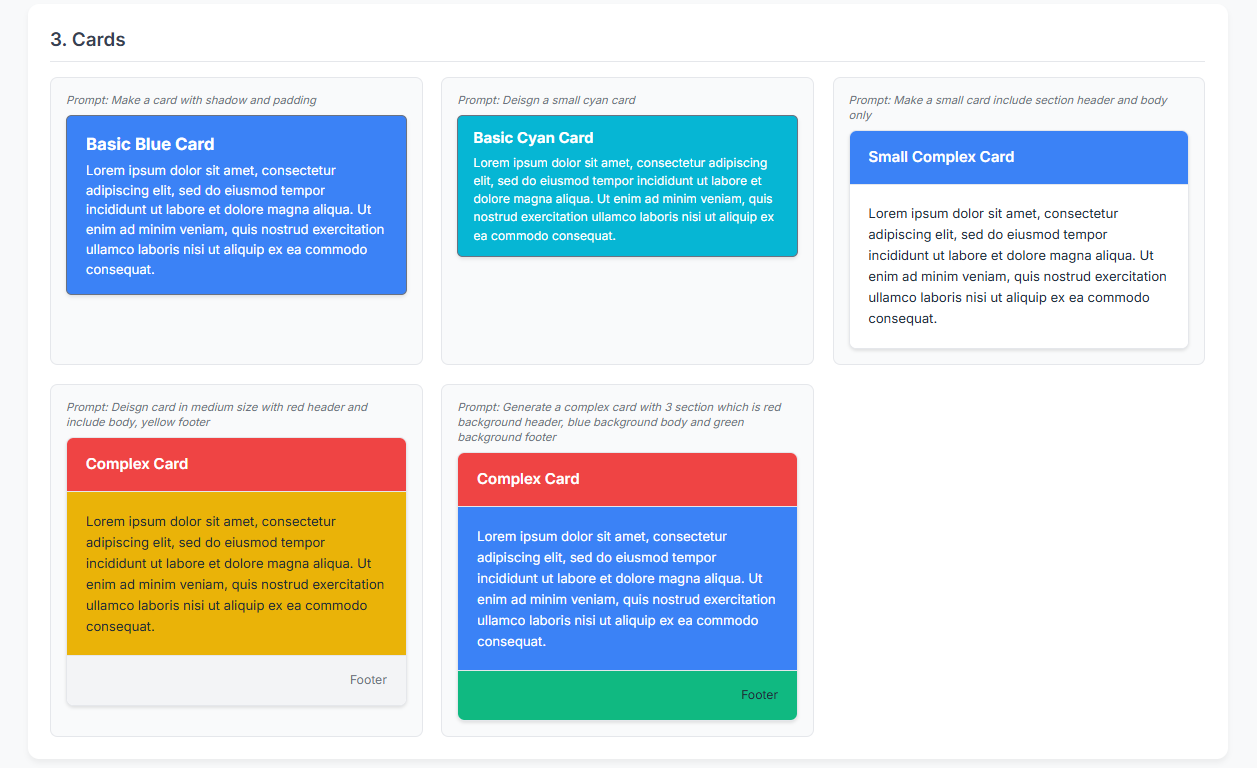
"Make a card with shadow and padding",
"Make a small card include section header and body only",
"Deisgn card in medium size with red header and include body, yellow footer",
"Deisgn a small cyan card",
"Build a text input with green focus border",
"Generate small size button in yellow and include hover effect only",
"Make ghost button medium with orange color",
"Make a ghost button (extra large, purple) with must include effect: hover, focus",
"Create a button with outline variant and large size with red color, it also must have hover and focus effect",
"Generate for me input (size large) with full border radius and focus in orange",
"Generate a complex card with 3 section which is red background header, blue background body and green background footer",
]
# Test với từng prompt
for prompt in test_prompts:
print(f"\nPrompt: {prompt}")
print("-" * 50)
print(generate_css(prompt, test_model, tokenizer))
print()
Khi chạy đoạn code trên, chúng ta sẽ có được kết quả CSS được sinh từ từng prompt. Kết quả của các component được tạo ra đa số đều theo các tiêu chuẩn đã định như màu sắc, kích thước, cách đặt tên, trạng thái (state), ..., chỉ có một số trường hợp như các component card phức tạp thì có sai sót.
Prompt: Create a large blue button with rounded corners and hover effect
--------------------------------------------------
/* Primary Button - Blue LG */
.btn-primary-blue-lg {
padding: 12px 24px;
font-size: 16px;
font-weight: 600;
color: #ffffff;
background-color: #3b82f6;
border: none;
border-radius: 6px;
cursor: pointer;
}
.btn-primary-blue-lg:hover {
opacity: 0.9;
}
Prompt: Design a small red badge with white text
--------------------------------------------------
/* Badge - Red Small */
.badge-red-sm {
display: inline-flex;
align-items: center;
padding: 4px 8px;
font-size: 13px;
font-weight: 500;
color: #ffffff;
background-color: #ef4444;
border-radius: 6px;
}
Prompt: Make a card with shadow and padding
--------------------------------------------------
/* Basic Card - Combined Characteristics */
.card-basic-blue-md {
display: block;
width: 100%;
max-width: 400px;
padding: 16px 20px;
font-size: 14px;
color: #ffffff;
background-color: #3b82f6;
border: 2px solid #6b7280;
border-radius: 6px;
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
}
Prompt: Make a small card include section header and body only
--------------------------------------------------
/* Complex Card - Simplified Structure */
.card-complex-small {
display: block;
width: 100%;
max-width: 400px;
background-color: #ffffff;
border: 1px solid #e5e7eb;
border-radius: 8px;
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
overflow: hidden;
transition: all 0.3s ease;
}
.card-complex-small:hover {
transform: translateY(-4px);
box-shadow: 0 12px 24px rgba(0, 0, 0, 0.15);
}
.card-complex-header-blue {
padding: 16px 20px;
font-size: 16px;
font-weight: 600;
color: #ffffff;
background-color: #3b82f6;
text-align: left;
border-bottom: 1px solid #e5e7eb;
}
.card-complex-body-white {
padding: 20px;
font-size: 14px;
color: #1f2937;
background-color: #ffffff;
line-height: 1.6;
}
Prompt: Deisgn card in medium size with red header and include body, yellow footer
--------------------------------------------------
/* Complex Card - Simplified Structure */
.card-complex-medium {
display: block;
width: 100%;
max-width: 400px;
background-color: #ffffff;
border: 1px solid #e5e7eb;
border-radius: 8px;
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
overflow: hidden;
transition: all 0.3s ease;
}
.card-complex-medium:hover {
transform: translateY(-4px);
box-shadow: 0 12px 24px rgba(0, 0, 0, 0.15);
}
.card-complex-header-red {
padding: 16px 20px;
font-size: 16px;
font-weight: 600;
color: #ffffff;
background-color: #ef4444;
text-align: left;
border-bottom: 1px solid #e5e7eb;
}
.card-complex-body-yellow {
padding: 20px;
font-size: 14px;
color: #1f2937;
background-color: #eab308;
line-height: 1.6;
}
.card-complex-footer-lightgray {
padding: 16px 20px;
font-size: 13px;
color: #6b7280;
background-color: #f3f4f6;
border-top: 1px solid #e5e7eb;
text-align: right;
}
Prompt: Deisgn a small cyan card
--------------------------------------------------
/* Basic Card - Combined Characteristics */
.card-basic-cyan-sm {
display: block;
width: 100%;
max-width: 400px;
padding: 12px 16px;
font-size: 13px;
color: #ffffff;
background-color: #06b6d4;
border: 2px solid #6b7280;
border-radius: 6px;
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
}
Prompt: Build a text input with green focus border
--------------------------------------------------
/* Text Input - MD Green Rounded */
.text-input-md-green-rounded {
/* Layout */
display: inline-block;
width: 100%;
/* Sizing */
height: 40px;
padding: 10px 16px;
/* Typography */
font-size: 14px;
font-family: system-ui, -apple-system, sans-serif;
color: #1f2937;
/* Colors */
background-color: #ffffff;
border: 1px solid #d1d5db;
/* Effects */
border-radius: 6px;
outline: none;
/* Transitions */
transition: all 0.2s ease;
}
.text-input-md-green-rounded:focus {
border-color: #10b981;
box-shadow: 0 0 0 3px rgba(16, 185, 129, 0.1);
}
.text-input-md-green-rounded:disabled {
opacity: 0.6;
cursor: not-allowed;
background-color: #f3f4f6;
}
.text-input-md-green-rounded::placeholder {
color: #9ca3af;
}
Prompt: Generate small size button in yellow and include hover effect only
--------------------------------------------------
/* Outline Button - Yellow SM */
.btn-outline-yellow-sm {
padding: 6px 12px;
font-size: 13px;
font-weight: 600;
color: #eab308;
background-color: transparent;
border: 2px solid #eab308;
border-radius: 6px;
cursor: pointer;
}
.btn-outline-yellow-sm:hover {
background-color: #eab308;
color: #ffffff;
}
Prompt: Make ghost button medium with orange color
--------------------------------------------------
/* Ghost Button - Orange MD */
.btn-ghost-orange-md {
padding: 10px 20px;
font-size: 14px;
font-weight: 600;
color: #f97316;
background-color: transparent;
border: none;
border-radius: 6px;
cursor: pointer;
}
.btn-ghost-orange-md:hover {
background-color: rgba(249, 115, 22, 0.1);
}
Prompt: Make a ghost button (extra large, purple) with must include effect: hover, focus
--------------------------------------------------
/* Ghost Button - Purple XL */
.btn-ghost-purple-xl {
padding: 16px 32px;
font-size: 18px;
font-weight: 600;
color: #a855f7;
background-color: transparent;
border: none;
border-radius: 6px;
cursor: pointer;
transition: all 0.2s ease;
}
.btn-ghost-purple-xl:hover {
background-color: rgba(168, 85, 247, 0.1);
}
.btn-ghost-purple-xl:active {
background-color: rgba(168, 85, 247, 0.2);
transform: scale(0.98);
}
.btn-ghost-purple-xl:focus {
outline: 2px solid #a855f7;
outline-offset: 2px;
}
Prompt: Create a button with outline variant and large size with red color, it also must have hover and focus effect
--------------------------------------------------
/* Outline Button - Red LG */
.btn-outline-red-lg {
padding: 12px 24px;
font-size: 16px;
font-weight: 600;
color: #ef4444;
background-color: transparent;
border: 2px solid #ef4444;
border-radius: 6px;
cursor: pointer;
transition: all 0.3s ease;
}
.btn-outline-red-lg:hover {
background-color: #ef4444;
color: #ffffff;
transform: translateY(-2px);
box-shadow: 0 4px 8px rgba(0, 0, 0, 0.12);
}
.btn-outline-red-lg:focus {
outline: 2px solid #ef4444;
outline-offset: 2px;
box-shadow: 0 0 0 3px rgba(239, 68, 68, 0.1);
}
.btn-outline-red-lg:disabled {
opacity: 0.5;
cursor: not-allowed;
}
Prompt: Generate for me input (size large) with full border radius and focus in orange
--------------------------------------------------
/* Text Input - MD Orange Rounded */
.text-input-md-orange-rounded {
/* Layout */
display: inline-block;
width: 100%;
/* Sizing */
height: 40px;
padding: 10px 16px;
/* Typography */
font-size: 14px;
font-family: system-ui, -apple-system, sans-serif;
color: #1f2937;
/* Colors */
background-color: #ffffff;
border: 1px solid #d1d5db;
/* Effects */
border-radius: 6px;
outline: none;
/* Transitions */
transition: all 0.2s ease;
}
.text-input-md-orange-rounded:focus {
border-color: #f97316;
box-shadow: 0 0 0 3px rgba(249, 115, 22, 0.1);
}
.text-input-md-orange-rounded:disabled {
opacity: 0.6;
cursor: not-allowed;
background-color: #f3f4f6;
}
.text-input-md-orange-rounded::placeholder {
color: #9ca3af;
}
Prompt: Generate a complex card with 3 section which is red background header, blue background body and green background footer
--------------------------------------------------
/* Complex Card - Simplified Structure */
.card-complex-medium {
display: block;
width: 100%;
max-width: 400px;
background-color: #ffffff;
border: 1px solid #e5e7eb;
border-radius: 8px;
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
overflow: hidden;
transition: all 0.3s ease;
}
.card-complex-medium:hover {
transform: translateY(-4px);
box-shadow: 0 12px 24px rgba(0, 0, 0, 0.15);
}
.card-complex-header-red {
padding: 16px 20px;
font-size: 16px;
font-weight: 600;
color: #ffffff;
background-color: #ef4444;
text-align: left;
border-bottom: 1px solid #e5e7eb;
}
.card-complex-body-blue {
padding: 20px;
font-size: 14px;
color: #1f2937;
background-color: #ffffff;
line-height: 1.6;
}
.card-complex-footer-green {
padding: 16px 20px;
font-size: 13px;
color: #1f2937;
background-color: #10b981;
border-top: 1px solid #e5e7eb;
text-align: right;
}
![]()
Kết luận
Fine-tune với LoRA giúp biến các mô hình nhỏ thành trợ lý AI phù hợp với các tiêu chí và tiêu chuẩn cá nhân đề ra, đồng thời tiết kiệm được chi phí và vẫn bảo đảm dữ liệu riêng tư. Khi được tùy chỉnh cho từng tác vụ cụ thể như sinh CSS, viết tài liệu hay hỗ trợ code, model có thể xử lý công việc lặp lại nhanh hơn và nhất quán hơn, từ đó nâng hiệu suất làm việc lên rõ rệt. Đây là bước khởi đầu để biến các mô hình nhỏ thành công cụ hỗ trợ đắc lực để tăng chất lượng trong công việc hàng ngày.

