Truy vấn dữ liệu thời AI (Phần 2): Tìm kiếm vector và tối ưu embedding
Hướng dẫn xây dựng, tối ưu hệ tìm kiếm vector với lựa chọn embedding model, giảm chiều dữ liệu và cân bằng tốc độ, độ chính xác cho ứng dụng AI.

Đọc thêm: Truy vấn dữ liệu thời AI (Phần 1): Tạo database index dùng MCP server và Claude
Một ngày mình vô tình làm đổ rượu lên chiếc áo yêu thích. Vội vã lên mạng, mình gõ "áo vết rượu" để tìm cách xử lý vết bẩn, nhưng lại quên gõ thêm từ "tẩy" để tìm kiếm. Vậy mà hàng loạt bài hướng dẫn cách làm sạch vết rượu trên áo vẫn xuất hiện trước mắt.
Đây chỉ là tưởng tượng của mình, nhưng là ví dụ để thể hiện sức mạnh của tìm kiếm ngữ nghĩa - nơi máy tính hiểu ý chứ không chỉ khớp từ.
Trong bài viết này, chúng ta sẽ bước sang không gian vector, tập trung vào database vector - nơi mức độ tương đồng về ngữ nghĩa giữa truy vấn và tài liệu được đo lường trực tiếp. Bài viết gồm hai phần chính:
- Back To Basic: vector index (IVF, HNSW, LSH…), đánh đổi giữa tốc độ - bộ nhớ - độ chính xác, và bức tranh tổng quan về semantic search.
- Applied AI: Một demo đơn giản so sánh semantic search (SBERT + FAISS) và lexical search (BM25) trong bối cảnh e-commerce.
Back to basic
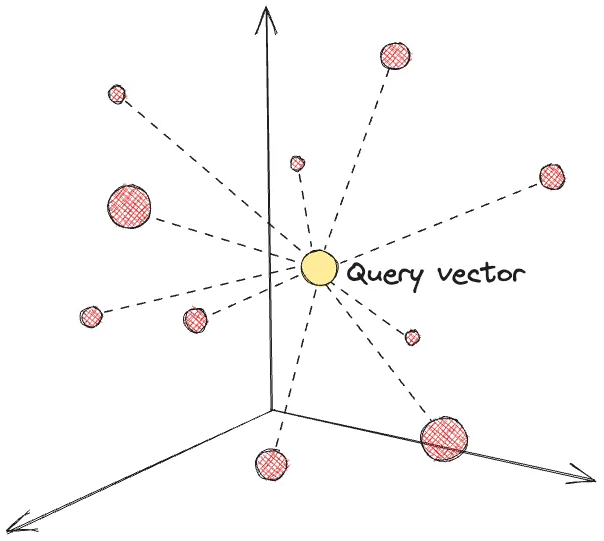
Nguồn: The Data Quarry
Cơ sở dữ liệu quan hệ truyền thống lưu thông tin dưới dạng các giá trị có kiểu, dễ đọc cho con người (hàng và cột gồm chữ và số). Ngược lại, cơ sở dữ liệu vector lưu các vector số nhiều chiều - những dãy số như [0.12, -0.73, …]- để máy có thể đo độ tương tự nhanh chóng.
Chỉ mục vector (Vector index)
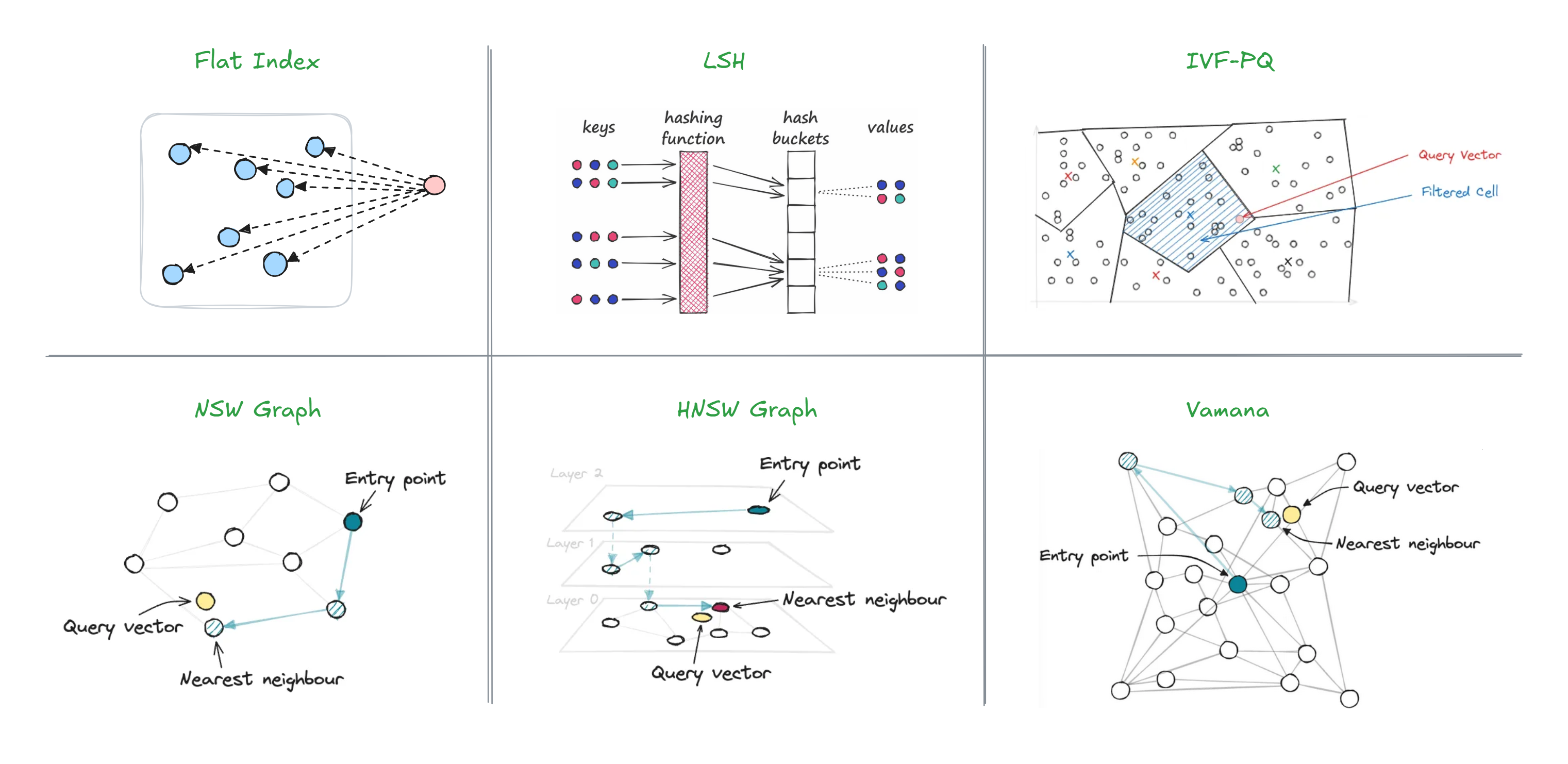
Nguồn: Tổng hợp
Chỉ mục là cấu trúc dữ liệu (ví dụ B-tree, hash) giúp tăng tốc độ truy vấn. Chỉ mục vector được xây dựng để tìm các vector 'gần nhau' một cách hiệu quả.
Khác với chỉ mục truyền thống, chỉ mục vector cho phép dùng các thuật toán xấp xỉ để tăng tốc truy vấn tìm kiếm lân cận (nearest neighbor) mà vẫn giữ độ chính xác đủ cao cho ứng dụng thực tế. Vì vậy, tuning ảnh hưởng cả hiệu năng lẫn chất lượng kết quả (thường đo bằng recall, đôi khi cả precision). Xem thêm Evaluation Metrics Revisited.
Chỉ mục vector có thể được triển khai theo hai hướng: trong các thư viện phục vụ xử lý và tìm kiếm vector như FAISS, hoặc trong các CSDL vector chuyên dụng. Ngoài ra, một số CSDL quan hệ như PostgreSQL cũng hỗ trợ kiểu dữ liệu vector, thường qua extension như pgvector.
Lưu ý khi triển khai chỉ mục vector:
- Tốc độ và độ chính xác: Mọi phương pháp chỉ mục luôn có đánh đổi giữa tốc độ truy vấn, tìm các vector phù hợp và độ chính xác của kết quả.
Ví dụ: Với khoảng < 100.000 vector, ta có thể dùng brute force để đạt recall hoàn hảo (≈1.0) mà độ trễ vẫn chấp nhận được. Nhưng khi tăng lên khoảng ~1.000.000 vector, sẽ hiệu quả hơn nếu dùng ANN (HNSW, IVF...) chấp nhận đánh đổi một phần nhỏ recall để tăng tốc truy vấn đáng kể. Ngoài ra còn tùy thuộc vào bài toán cần giải quyết: real-time recommendation system có thể ưu tiên độ trễ < 50ms/truy vấn và chấp nhận recall ~80%, còn batch data analysis tool có thể chấp nhận độ trễ cao hơn để đạt recall ~95%.
- Bộ nhớ: Một số chỉ mục cần thêm dữ liệu phụ để chạy nhanh.
Ví dụ: Bộ nhớ của index phụ thuộc vào cấu trúc dữ liệu, mức độ nén qua quantization và refiner được sử dụng. Chỉ mục dựa trên đồ thị (như HNSW) thường có dung lượng bộ nhớ cao do cấu trúc graph phức tạp với overhead đáng kể cho mỗi vector. IVF và các biến thể hiệu quả hơn về bộ nhớ vì ít overhead trên mỗi vector hơn. Phương pháp hybrid (như DiskANN) cho phép lưu một phần index (graph hoặc refiner) trên disk, giảm tải RAM trong khi vẫn duy trì hiệu năng tốt. Chi tiết xem tại đây.
- Cập nhật: Chỉ mục phải được build xong trước truy cấn. Chúng ta cần đánh giá độ phức tạp của bước build. Nếu việc thêm vector mới khiến rebuild toàn phần, chúng ta cần xác định tần suất cập nhật phù hợp.
Ví dụ: Các index có đặc điểm cập nhật khác nhau tùy thuộc vào cấu trúc. FLAT có thời gian build tối thiểu và hỗ trợ cập nhật thời gian thực rất linh hoạt, phù hợp với tập dữ liệu động thay đổi thường xuyên; tuy nhiên thời gian truy vấn chậm khi tập dữ liệu lớn. IVF (như IVF-FLAT, IVF-PQ) có thời gian build dài hơn do cần phân vùng clusters nhưng truy vấn nhanh hơn nhiều; việc cập nhật phức tạp hơn vì có thể cần điều chỉnh các clusters, do đó phù hợp cho tập dữ liệu lớn, tương đối static. HNSW có thời gian build dài nhất do phải xây dựng cấu trúc đồ thị phức tạp nhưng truy vấn cực nhanh; index này cho phép thêm/xóa vector nhưng tốn kém về mặt tính toán vì có thể cần tái cấu hình đồ thị, phù hợp khi ưu tiên tốc độ truy vấn và ít cập nhật.
- Số chiều vector: Chiều dài vector (dimensionality) ảnh hưởng trực tiếp đến hiệu năng và bộ nhớ - vector càng nhiều chiều càng tốn RAM và thời gian tính toán. Matryoshka embeddings cho phép cắt giảm số chiều từ mô hình embedding (ví dụ từ 768 xuống 256 chiều) mà vẫn giữ được phần lớn thông tin, giảm đáng kể bộ nhớ và tăng tốc truy vấn. Cũng có thể áp dụng các kỹ thuật giảm số chiều (ví dụ PCA, t-SNE), song cần đánh đổi với mức độ mất mát thông tin.
Tìm kiếm ngữ nghĩa (Semantic search)
Thay vì khớp từ khóa, tìm kiếm ngữ nghĩa xếp hạng nội dung theo ý nghĩa và ý định của người dùng. Hệ thống còn có thể tận dụng bối cảnh như vị trí, lịch sử truy vấn, từ đồng/đa nghĩa và quan hệ giữa các khái niệm. Nền tảng kỹ thuật của nó là tìm kiếm vector (vector search).
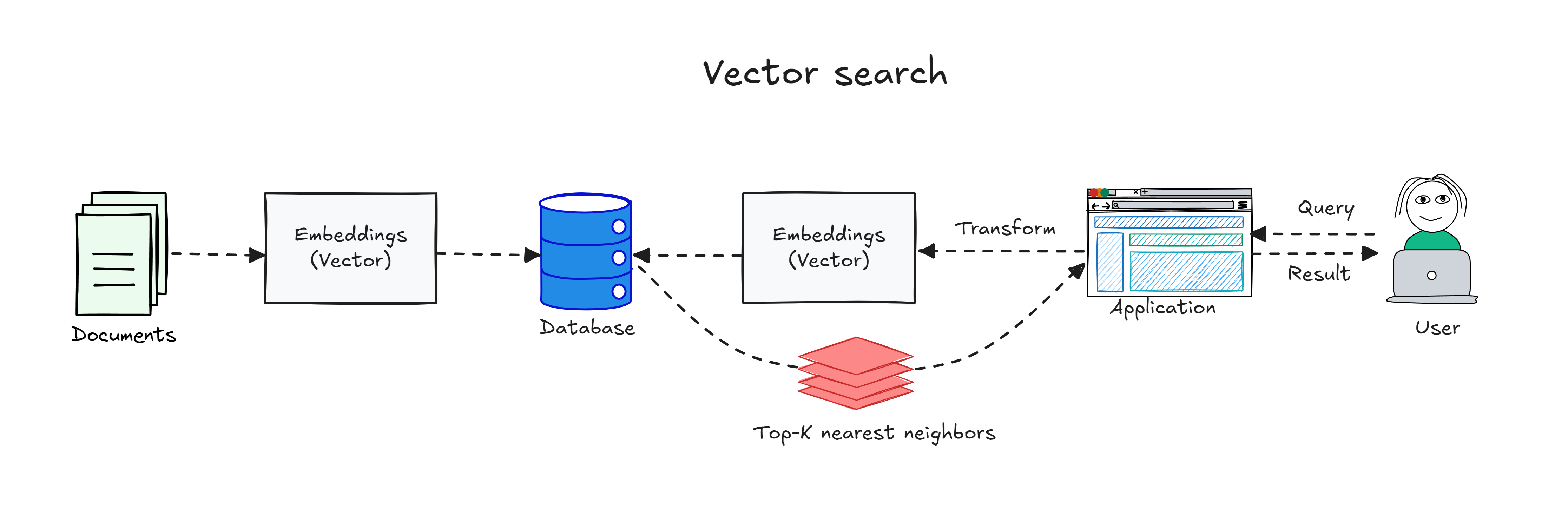
Quy trình cơ bản của vector search: cả truy vấn của người dùng và tài liệu đều được embedding (biểu diễn thành vector) bằng cùng một mô hình embedding (embedding model). Embedding của tài liệu được tính trước và lưu trong CSDL (thường nằm trong một chỉ mục vector). Khi người dùng truy vấn, hệ thống tạo embedding cho truy vấn rồi tìm các tìm kiếm lân cận gần nhất trong tập vector đã lưu (ví dụ bằng độ tương tự cosin) để lấy top-k kết quả phù hợp nhất.
Ứng dụng của semantic search:
- Search engine: Hiểu truy vấn phức tạp và ý định người dùng để trả kết quả sát nghĩa hơn
- Tìm kiếm nội bộ: Giúp nhân viên nhanh chóng tìm đúng tài liệu (chính sách, quy trình…) dựa trên ý định thay vì chỉ khớp từ
- Thương mại điện tử (ecommerce): Cải thiện kết quả ngay cả khi từ khóa người dùng tìm kiếm không trùng với mô tả sản phẩm
- Giáo dục & e-learning: Cá nhân hóa gợi ý tài nguyên học tập theo nhu cầu và ngữ cảnh truy vấn
Applied AI: Demo full-text & semantic cho e-commerce
Trong thực tế, người dùng khi tìm kiếm sản phẩm thường diễn đạt ý định tìm kiếm rất đa dạng, có lúc họ gõ chính xác tên mẫu (lexical), có lúc lại mô tả nhu cầu bằng ngôn ngữ tự nhiên (semantic). Chúng ta sẽdemo đơn giản bằng Python để so sánh tìm kiếm ngữ nghĩa (SentenceTransformers + FAISS) và tìm kiếm theo từ khóa (BM25) trên tập tiêu đề sản phẩm.
Demo step-by-step: Thiết lập và chạy so sánh Semantic vs. Lexical
Bước 1: Khởi tạo project Python
Tạo một thư mục mới (ví dụ: product_search_demo) và mở bằng editor quen thuộc (VS Code, Pycharm,...).
Trong terminal tại thư mục đó, chạy lệnh sau để khởi tạo project:
uv init .
Bước 2: Cài đặt dependencies
Chạy các lệnh dưới để cài đặt các thư viện:
sentence-transformers: tạo vector embedding cho văn bản (tiêu đề sản phẩm, truy vấn, …)faiss-cpu: tìm kiếm lân cận gần nhất (nearest neighbor) trên các vector embeddingnumpy: thư viện mảng số học, dùng để chứa và thao tác embeddingrank-bm25: triển khai BM25 dùng cho lexical (full-text) search
uv add sentence-transformers faiss-cpu numpy rank-bm25
Bước 3: Chuẩn bị dữ liệu & tham số
Giải thích dữ liệu & tham số (vì sao chọn như vậy?)
-
top_k = 3: đủ nhỏ để thấy rõ khác biệt giữa hai phương pháp. -
query_text = "cloth wine stain": truy vấn cố ý diễn đạt nhu cầu (“vết rượu trên vải”) thay vì tên sản phẩm chính xác. -
product_titles: tập tiêu đề có chủ đích pha trộn:- (1) Mục liên quan bề mặt theo từ vựng (wine/cloth) nhưng không giải quyết “vết bẩn” (kệ rượu, sổ nếm rượu, khăn vải…).
- (2) Mục giải pháp tẩy vết bẩn nhưng không chứa từ “wine/cloth”.
Nhờ vậy ta có tương phản: semantic nên ưu tiên nhóm (2), còn BM25 có xu hướng ưu tiên nhóm (1) vì khớp từ khóa.
top_k = 3 # top k results
query_text = "cloth wine stain" # demo query
product_titles = [
# (1) keyword match 'wine/cloth' but wrong intent
"wine aerator pourer stainless steel",
"bamboo countertop wine rack",
"wine yeast for home brewing",
"wine tasting journal notebook",
"wine cork shadow box",
"merlot red cloth table runner",
"linen cloth napkins 12-pack",
"cloth tote bag canvas",
"cloth diaper covers waterproof",
"reusable cloth face mask",
# (2) Relevant (stain-removal solutions for fabric)
"enzyme laundry stain remover for tannin stains",
"oxygen bleach color-safe powder for clothes",
"hydrogen peroxide-based stain remover for textiles",
"prewash stain treatment for colored garments",
"portable stain remover wipes for clothing",
"stain remover gel for upholstery and carpets",
"laundry detergent with enzymes for tough stains",
"oxidizing stain pen for spill emergencies",
"pre-treat spray for beverage stains on fabric"
]
Bước 4: Semantic search (SBERT + FAISS)
Ở bước này, mình mã hoá tiêu đề sản phẩm và truy vấn thành các vector ngữ nghĩa bằng model SBERT phổ biến all-MiniLM-L6-v2 (xem thêm các model khác tại đây). Mỗi vector tóm tắt ý nghĩa của câu trong một không gian nhiều chiều, giúp so sánh “gần về nghĩa” chứ không chỉ trùng từ.
- Mã hoá văn bản → embedding
Mình dùngSentenceTransformerđể encode toàn bộ tiêu đề và truy vấn thành mảngfloat32. - Khởi tạo FAISS index (L2)
Tiếp theo, mình xây FAISS indexIndexFlatL2và dùng khoảng cách Euclid (L2) để đo mức gần nhau giữa truy vấn và từng sản phẩm.IndexFlatL2thực hiện exhaustive search (duyệt hết) nên dễ hiểu, không cần train, rất phù hợp cho demo hoặc tập dữ liệu nhỏ - vừa.
NgoàiIndexFlatL2, FAISS có các index ưu tiên tốc độ tra cứu, đổi lại không bảo đảm tìm đúng tuyệt đối như exhaustive search. Xem thêm trong danh mục index FAISS. - Nạp dữ liệu vào index
Thêm tất cả embedding của tiêu đề vào index để sẵn sàng tra cứu. - Truy vấn và lấy
top_k
Cuối cùng, mình truy vấn lấytop_kláng giềng gần nhất. FAISS trả về khoảng cách L2 - càng nhỏ thì càng liên quan - từ đó xếp hạng và in ra các sản phẩm phù hợp nhất theo ngữ nghĩa.
# Load the embedding model
encoder_model = SentenceTransformer("all-MiniLM-L6-v2")
# 1) Encode documents and query into float32 vectors
document_embeddings = encoder_model.encode(product_titles).astype("float32")
query_embedding = encoder_model.encode([query_text]).astype("float32")
# 2) Build a FAISS index that uses Euclidean (L2) distance
faiss_index = faiss.IndexFlatL2(document_embeddings.shape[1])
# 3) Add the document vectors to the index
faiss_index.add(document_embeddings)
# 4) Search the K nearest documents for the query
# Note: FAISS returns L2 distances; smaller is more similar.
distances, nearest_indices = faiss_index.search(query_embedding, top_k)
Bước 5: Lexical search (BM25)
Ở bước này, mình xếp hạng tài liệu theo mức độ khớp từ khoá bằng BM25. Khác với embedding ngữ nghĩa, BM25 dựa trên tần suất từ, độ hiếm từ và chuẩn hoá độ dài tài liệu, vì vậy tiêu đề chứa đúng từ khoá thường được ưu tiên.
- Token hóa tập văn bản và truy vấn
Trước hết, mình token hóa toàn bộ tiêu đề và truy vấn: câu được tách thành các từ đơn lẻ (tokens) - đây là bước tiền xử lý quan trọng vì BM25 hoạt động trên mức token. - Khởi tạo chỉ mục BM25
Sau đó, mình xây một chỉ mục BM25 từ tập tài liệu đã token hóa. - Chấm điểm truy vấn
Khi chấm điểm truy vấn, mô hình trả về một điểm BM25 cho mỗi tài liệu (điểm càng cao thì càng liên quan theo tiêu chí từ khoá). - Xếp hạng và gom kết quả
Cuối cùng, mình sắp xếp điểm giảm dần và lấytop_kkết quả tốt nhất, rồi tổng hợp thành cặp (title, score) để in ra và đối chiếu trực tiếp với bảng xếp hạng theo ngữ nghĩa ở bước 4.
# 1) Tokenize documents & query
tokenized_corpus = [title.split(" ") for title in product_titles]
tokenized_query = query_text.split(" ")
# 2) Build BM25 index from the tokenized document corpus
bm25_index = BM25Okapi(tokenized_corpus)
# 3) Score each document
bm25_scores = bm25_index.get_scores(tokenized_query)
# 4) Rank & collect top_k
top_indices = np.argsort(-bm25_scores)[:top_k]
bm25_results: List[Tuple[str, float]] = [
(product_titles[i], float(bm25_scores[i])) for i in top_indices
]
Bước 6: Chạy demo và quan sát kết quả
Ở bước này, mình in ra hai bảng xếp hạng từ cùng một truy vấn:
- Semantic (SBERT + FAISS, L2): Trả về khoảng cách giữa embedding truy vấn và từng tiêu đề. Khoảng cách càng nhỏ → càng giống về nghĩa. Vì vậy top 3 đều là chất tẩy/tiền xử lý vết đồ uống trên vải (đúng với ý “cloth wine stain”).
- Lexical (BM25): Xếp hạng theo khớp từ khoá. Do truy vấn chứa “cloth/wine”, BM25 ưu tiên những tiêu đề có từ “cloth/wine” (kệ rượu, sổ nhật ký nếm rượu, khăn vải) dù không giúp tẩy vết bẩn.
print("\n[Semantic — (SBERT + FAISS with L2 distance; lower is better)]")
for rank in range(top_k):
title = product_titles[nearest_indices[0][rank]]
distance = distances[0][rank]
print(f"{rank+1}. {title} (Distance: {distance:.4f})")
print("\n[Lexical Search — BM25 (rank-bm25; higher is better)]")
for rank, (title, score) in enumerate(bm25_results, 1):
print(f"{rank}. {title} (score: {score:.3f})")
[Semantic — (SBERT + FAISS with L2 distance; lower is better)]
1. pre-treat spray for beverage stains on fabric (Distance: 0.6469)
2. prewash stain treatment for colored garments (Distance: 0.7183)
3. portable stain remover wipes for clothing (Distance: 0.8361)
[Lexical Search — BM25 (rank-bm25; higher is better)]
1. bamboo countertop wine rack (score: 1.091)
2. wine tasting journal notebook (score: 1.091)
3. linen cloth napkins 12-pack (score: 1.091)
Lexical Search vs. Semantic Search

Khi nào nên dùng Lexical Search và Semantic Search?
Lexical Search phù hợp khi cần độ chính xác tuyệt đối: tra cứu tài liệu kỹ thuật hoặc văn bản pháp lý, tìm mã sản phẩm trong cơ sở dữ liệu, hay định vị cụm từ nguyên văn trong một tập tài liệu lớn.
Ngược lại, Semantic Search tỏa sáng ở các tác vụ 'hiểu ý', như trợ lý số/chatbot, khám phá sản phẩm trong thương mại điện tử, và nghiên cứu học thuật nơi ta cần tìm các bài viết liên quan về mặt khái niệm.
Chúng ta có thể chọn Hybrid Search để kết hợp điểm mạnh của cả hai, tự cân bằng giữa khớp từ khóa và mức độ liên quan ngữ nghĩa, đồng thời triển khai phân tích truy vấn để nhận diện truy vấn cụ thể hay ngôn ngữ tự nhiên, từ đó chọn phương pháp tìm kiếm phù hợp theo ngữ cảnh và đúng với ý định/thói quen người dùng.
Lựa chọn model embedding và vector size cho production
Khi triển khai semantic search vào production, việc lựa chọn model và kích thước vector phù hợp ảnh hưởng trực tiếp đến hiệu năng, chi phí và chất lượng kết quả.
Lựa chọn model embedding
Model all-MiniLM-L6-v2 trong demo này phù hợp cho thử nghiệm nhanh (384 chiều). Khi triển khai thực tế, cần cân nhắc ba yếu tố: độ chính xác ngữ nghĩa (đánh giá qua benchmark như MTEB), yêu cầu domain chuyên ngành (model tổng quát thường không đủ - ví dụ y học cần BioBERT, pháp lý cần Legal-BERT), và chi phí tính toán (model lớn hơn thường chính xác hơn nhưng tốn tài nguyên hơn).
So sánh các lựa chọn phổ biến:
- Model mã nguồn mở (
all-mpnet-base-v2,BGE-M3,GTE-Base...): Miễn phí, toàn quyền kiểm soát, có thể tự fine-tune và đảm bảo riêng tư dữ liệu. Đổi lại cần đầu tư hạ tầng và bảo mật. - Model thương mại (OpenAI, Cohere...): Hiệu năng tốt sẵn, hạ tầng được quản lý, cập nhật thường xuyên, dễ tích hợp. Đổi lại tính phí theo token và có thể bị phụ thuộc nhà cung cấp.
- Cách tiếp cận kết hợp: Nhiều doanh nghiệp kết hợp cả hai để cân bằng tính linh hoạt - chi phí - tuân thủ.
Lựa chọn kích thước vector
Kích thước vector phụ thuộc vào độ phức tạp dữ liệu, tài nguyên tính toán và sự cân bằng giữa tốc độ - độ chính xác - bộ nhớ. Vector ngắn (50-300 chiều) thường đủ cho tác vụ đơn giản như khớp từ khóa, trong khi semantic search hoặc language modeling cần kích thước cao hơn (768-1024 chiều).
Nếu tự train embedding, có thể bắt đầu dựa vào quy mô dataset: ~10,000 token phù hợp với 128 chiều, ~1 triệu token thường cần 512 chiều trở lên. Các công cụ như PCA hoặc t-SNE giúp trực quan hóa embedding để đánh giá xem kích thước hiện tại có phù hợp không.
Ngoài ra, cần cân nhắc ràng buộc thực tế của môi trường triển khai. Thiết bị mobile yêu cầu chiều thấp hơn để tiết kiệm tài nguyên. Ví dụ: embedding 1024 chiều cho 1 triệu vector cần 4GB RAM (float 32-bit), trong khi 256 chiều chỉ cần 1GB - chênh lệch đáng kể trong môi trường hạn chế tài nguyên.
Kết
Vector database lưu các biểu diễn số nhiều chiều dưới dạng embedding để máy đo nhanh mức độ tương tự, tạo nền tảng cho tìm kiếm ngữ nghĩa, nơi hệ thống xếp hạng theo ý nghĩa và ý định của truy vấn thay vì chỉ khớp từ khóa.
Dù vậy, vector index không tự thân mang lại tốc độ tối đa vì nhiều kỹ thuật là xấp xỉ nên luôn tồn tại đánh đổi giữa tốc độ, bộ nhớ và độ chính xác, và việc tinh chỉnh tham số sẽ tác động trực tiếp đến chất lượng kết quả lẫn chi phí vận hành. Vì thế, lựa chọn công nghệ tìm kiếm không đơn thuần là áp dụng vector cho nhanh hơn mà cần xác định đúng loại chỉ mục và chiến lược phù hợp với ý định tìm kiếm, với chi phí cập nhật và mục tiêu chất lượng đề ra. Ở quy mô sản xuất, một cách tiếp cận bền vững là vừa giám sát các thước đo như recall và precision, vừa tối ưu vận hành, đồng thời cân nhắc kết hợp hybrid search để đạt hiệu quả ổn định lâu dài.

