Giải quyết bài toán SQL với Subquery và Window Function
Đừng chỉ dừng lại ở SELECT và JOIN. Subquery và Window Function mới là giải pháp lợi hại cho những bài toán phức tạp về tổng hợp, phân tích dữ liệu trong SQL.

Khi làm việc với cơ sở dữ liệu, chúng ta thường bắt đầu bằng những câu truy vấn SELECT cơ bản để lấy dữ liệu. Nhưng sớm thôi, chúng ta sẽ gặp những yêu cầu “khó nhằn” hơn. Ví dụ, cần tìm những bài viết có lượt xem cao hơn mức trung bình toàn website, hay theo dõi tổng số lượt xem lũy kế theo ngày để phân tích xu hướng. Với SELECT thông thường, các bài toán này khó giải quyết vì không thể vừa tổng hợp vừa so sánh ngay trong cùng một truy vấn. Đây là lúc Subquery và Window function phát huy sức mạnh. Chúng mở rộng khả năng của SQL, đưa những bài toán tưởng chừng phức tạp thành các truy vấn gọn gàng, rõ ràng hơn.
Trong bài viết, chúng ta sẽ minh họa các bài toán bằng bảng dữ liệu mẫu dưới đây.
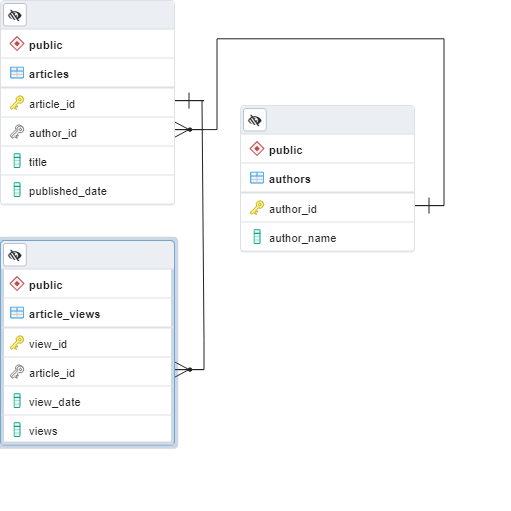
Subquery - Lấy dữ liệu trung gian cho outer query
Subquery là gì?
Subquery (còn gọi là nested query hoặc inner query) là một câu lệnh SQL được lồng bên trong một truy vấn khác, thường xuất hiện trong các mệnh đề WHERE, FROM hoặc SELECT. Mục đích cốt lõi của subquery là lấy ra tập dữ liệu trung gian để phục vụ cho outer query (truy vấn cha hay truy vấn bên ngoài).
Từ mục đích này, subquery có thể được khai thác theo 3 cách:
- Lọc dữ liệu để đưa vào outer query.
-- Bài toán: Tìm những tác giả không có bất kỳ bài viết nào.
SELECT author_name
FROM authors AS a
WHERE NOT EXISTS (
SELECT 1
FROM articles AS ar
WHERE ar.author_id = a.author_id
);
- Tính toán tổng hợp (
SUM,AVG,COUNT…) rồi đưa kết quả vào áp dụng ở outer query.
-- Bài toán: Tìm các bài viết có tổng lượt xem cao hơn mức trung bình của tất cả bài viết.
SELECT article_id, SUM(views) AS total_views
FROM article_views
GROUP BY article_id
HAVING SUM(views) > (
-- Subquery chứa lượt xem trung bình của tất cả bài viết
SELECT AVG(total_views)
FROM (
-- Subquery tính tổng lượt xem của từng bài viết
SELECT SUM(views) AS total_views
FROM article_views
GROUP BY article_id
) t
);
- Biến đổi dữ liệu (data manipulation) theo ngữ cảnh cần thiết trước khi lấy làm dữ liệu cho outer query.
Phân loại subquery
Khi nói đến subquery, ta có thể phân loại theo hình thức kết quả. Có loại chỉ trả về một giá trị duy nhất, có loại trả về một hàng nhiều cột, hoặc cả một bảng nhiều hàng. Tuy nhiên, đây chỉ là phân loại theo dữ liệu đầu ra. Quan trọng hơn là cách subquery “giao tiếp” với outer query, vì nó quyết định cơ chế thực thi và hiệu năng. Ở góc nhìn này, subquery thường được chia thành hai loại: independent và correlated.
Independent subquery
Independent subquery (hay non-correlated subquery) là loại chạy hoàn toàn độc lập, không tham chiếu tới bất kỳ cột nào từ outer query. Do đó, hệ quản trị cơ sở dữ liệu chỉ cần tính kết quả một lần, sau đó dùng lại cho toàn bộ outer query.
Ví dụ: Tìm các ngày của các bài viết có số lượt xem lớn hơn mức trung bình toàn hệ thống.
SELECT article_id, view_date, views
FROM article_views
WHERE views > (
SELECT AVG(views)
FROM article_views
);
Luồng thực thi câu truy vấn như sau:
- Subquery được tính trước, trả về một giá trị duy nhất (ví dụ: lượt xem trung bình = 80)
- Giá trị này được giữ lại, không phải tính lại cho từng dòng
- Outer query quét bảng
article_viewsvà so sánhviewscủa từng dòng với số trung bình. - Trả về những dòng thỏa điều kiện
views> 80
Nhờ đặc điểm tính toán này, independent subquery thường mang lại hiệu năng tốt và là lựa chọn ưu tiên khi bài toán cho phép.
Correlated subquery
Ngược lại với independent subquery chỉ cần tính toán một lần, correlated subquery phải chạy lại cho từng hàng của outer query, sử dụng giá trị từ hàng đó để tính toán. Đặc điểm này khiến nó phù hợp cho các bài toán yêu cầu so sánh hoặc tính toán chi tiết gắn với ngữ cảnh từng hàng trong outer query.
Ví dụ: Tìm những bài viết có lượt xem cao hơn mức trung bình các bài viết khác của cùng tác giả.
SELECT a.title, a.author_id
FROM articles a
WHERE (
SELECT AVG(v.views)
FROM article_views v
JOIN articles a2 ON v.article_id = a2.article_id
WHERE a2.author_id = a.author_id
) < (
SELECT SUM(v2.views)
FROM article_views v2
WHERE v2.article_id = a.article_id
);
Câu truy vấn sẽ được thực thi như sau:
-
Outer query duyệt từng bài viết trong bảng articles
- Giả sử đang xét bài viết có
author_id = 2,article_id = 101.
- Giả sử đang xét bài viết có
-
Thực thi subquery 1 – tính trung bình lượt xem của toàn bộ bài viết cùng tác giả
- Subquery này tham chiếu
a.author_idtừ outer query. - Hệ thống quét
article_views, kết nối vớiarticles, rồi gom tất cả bài viết củaauthor_id = 2để tính giá trị trung bình.
- Subquery này tham chiếu
-
Thực thi subquery 2 – tính tổng lượt xem của chính bài viết đang xét
- Subquery này tham chiếu
a.article_id. - Hệ thống lọc
article_viewstheoarticle_id = 101và tính tổng lượt xem.
- Subquery này tham chiếu
-
So sánh kết quả
- Outer query đối chiếu tổng lượt xem của bài viết (subquery 2) với trung bình lượt xem các bài cùng tác giả (subquery 1).
- Nếu tổng lượt xem lớn hơn trung bình, bài viết thỏa điều kiện và được đưa vào kết quả.
-
Lặp lại quy trình cho các bài viết khác trong bảng articles
Những lưu ý để tránh giảm hiệu năng
Subquery là công cụ mạnh mẽ, nhưng nếu sử dụng thiếu cân nhắc, chúng có thể khiến truy vấn trở nên kém hiệu quả. Sau đây là một vài điểm mà chúng ta cần lưu ý:
- Hạn chế lạm dụng subquery: Khi có thể, hãy xem xét việc dùng
JOIN, vì đa số hệ quản trị cơ sở dữ liệu tối ưu hóaJOINtốt hơn so với subquery. - Cẩn trọng với correlated subquery: Loại này phải chạy lại cho từng dòng của outer query, nên thường gây tốn kém hiệu năng. Nếu có thể, hãy viết lại thành independent subquery hoặc chuyển sang
JOIN. - Tận dụng index: Những cột được sử dụng trong điều kiện của subquery nên có index để tăng tốc độ truy vấn.
- Giới hạn dữ liệu cần thiết: Tránh
SELECT *trong subquery, chỉ chọn các cột cần dùng để giảm tải xử lý và cải thiện tốc độ.
Window function - Tính toán và phân tích trên từng dòng dữ liệu
Subquery hữu ích khi cần tính toán độc lập rồi kết hợp sử dụng trong outer query. Tuy nhiên, đối với các bài toán như tổng hợp (aggregates), xếp hạng (rankings) và tính tổng lũy kế (running totals), việc sử dụng subquery có thể dẫn đến giảm hiệu năng do thường phải dùng đến correlated subquery.
Thay vào đó, ta có một giải pháp hiệu quả hơn là window function. Tính chất tương tự như non-correlated, window function chỉ chạy một lần rồi lưu trữ kết quả trung gian và sử dụng lại mà không cần quét lại toàn bộ bảng.
Window function là gì?
Window function (hàm cửa sổ) cho phép thực hiện tính toán trên cửa sổ dữ liệu, tức là một tập hợp các hàng liên quan đến hàng hiện tại. Về bản chất, nó tương tự như các hàm tổng hợp (SUM, AVG, COUNT) trong GROUP BY, nhưng điểm khác biệt quan trọng là window function không gộp dữ liệu thành một bản ghi duy nhất mà vẫn giữ nguyên chi tiết từng hàng.
Window function được định nghĩa thông qua mệnh đề OVER(), thường đi kèm:
PARTITION BY: Chia dữ liệu thành các nhóm liên quan để tính toán.ORDER BY: Xác định thứ tự xử lý các hàng trong mỗi nhóm.
Để hình dung rõ hơn cách window function hoạt động, chúng ta hãy cùng xem thử bài toán: Theo dõi tổng lũy kế số lượt xem của từng bài viết theo thời gian.
SELECT
art.title,
av.view_date,
av.views,
-- Tính tổng lũy kế lượt xem của từng bài viết
SUM(av.views) OVER (
-- Nhóm các ngày xem theo bài viết bằng id
PARTITION BY av.article_id
-- Sắp xếp các ngày xem trong 1 nhóm/bài viết
ORDER BY av.view_date
) AS running_total_views
FROM article_views av
JOIN articles art ON av.article_id = art.article_id
ORDER BY art.title;
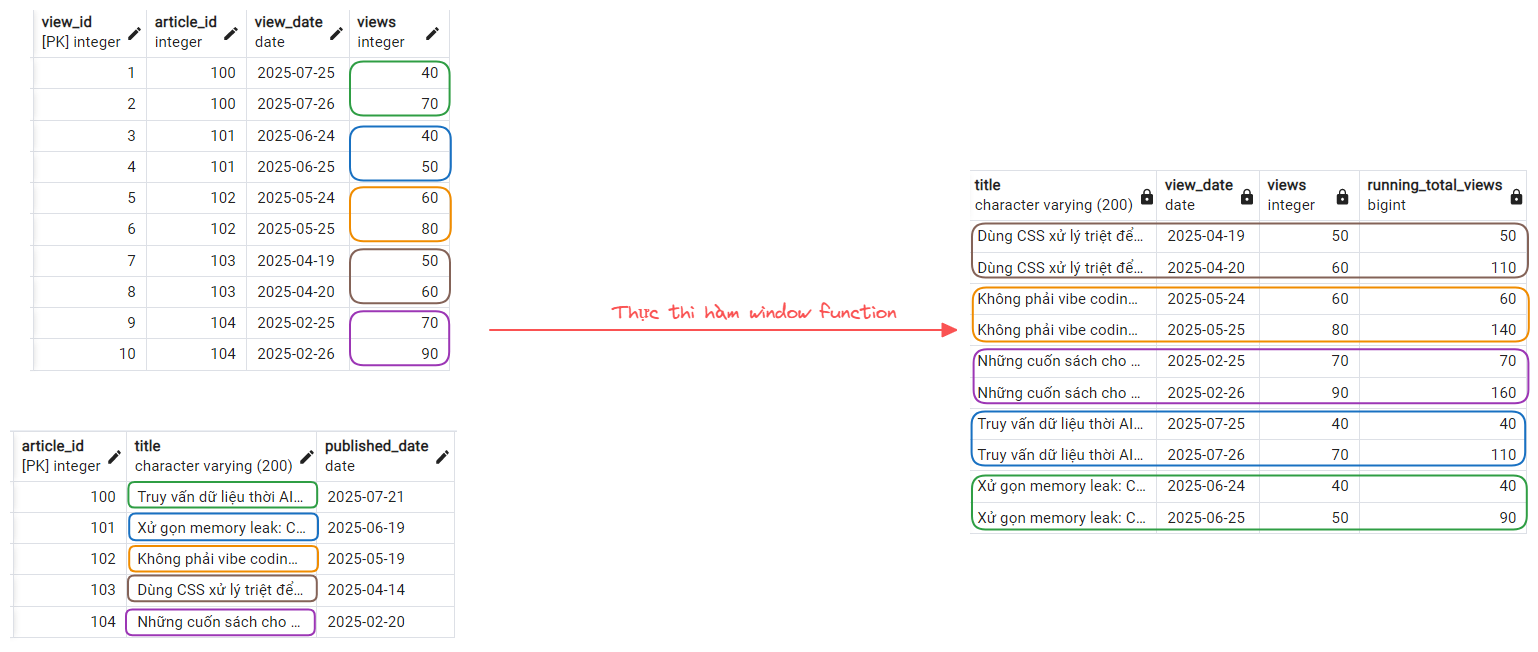
Câu query sử dụng SUM(av.views) OVER() với hai mệnh đề:
PARTITION BY av.article_id: Chia dữ liệu thành các nhóm riêng biệt theo từng bài viết.ORDER BY av.view_date: Sắp xếp bản ghi trong nhóm theo thời gian.
Window function sẽ "trượt" qua từng hàng trong mỗi nhóm và tính tổng lũy kế từ hàng đầu tiên đến hàng hiện tại. Ví dụ với bài viết có article_id = 103:
2025-04-19:views = 50→running_total_views = 502025-04-20:views = 60→running_total_views = 50 + 60 = 110
Kết quả cuối cùng vừa giữ lại chi tiết từng ngày, vừa bổ sung thêm cột running_total_views, giúp theo dõi xu hướng tăng trưởng lượt xem của từng bài viết một cách liên tục.
Các loại window function
Có thể chia window function thành 2 nhóm chính: Ranking Window Functions và Aggregate Window Function.
Ranking Window Functions
Loại này được sử dụng để xếp hạng các hàng trong một nhóm dựa trên tiêu chí sắp xếp trong ORDER BY. Các hàm phổ biến bao gồm:
ROW_NUMBER(): Gán số thứ tự duy nhất cho mỗi hàng, không có giá trị trùng lặpRANK(): Khi có giá trị bằng nhau, các hàng sẽ chia sẻ cùng một hạng, nhưng thứ hạng tiếp theo sẽ bị “nhảy cóc” (ví dụ: 1, 2, 2, 4...).DENSE_RANK(): Tương tự nhưRANK(), nhưng thứ hạng sẽ liên tục, không bị nhảy cóc khi có giá trị bằng nhau (ví dụ: 1, 2, 2, 3...).
Các hàm xếp hạng này đặc biệt hữu ích khi cần phân loại dữ liệu, hoặc tạo báo cáo thống kê theo thứ hạng. Ví dụ, với bài toán xếp hạng các bài viết theo tổng lượt xem, ta sẽ so sánh kết quả của RANK() và DENSE_RANK()
SELECT
a.article_id,
a.title,
-- Tính tổng view để dễ quan sát
SUM(av.views) as total_views,
-- Xếp hạng với RANK
RANK() OVER (ORDER BY SUM(av.views) DESC) as rank_by_views,
-- Xếp hạng với DENSE_RANK
DENSE_RANK() OVER (ORDER BY SUM(av.views) DESC) as dense_rank_by_views
FROM articles a
JOIN article_views av ON a.article_id = av.article_id
GROUP BY a.article_id, a.title
ORDER BY rank_by_views ASC;
![]()
Kết quả trên minh họa rõ sự khác biệt giữa hai hàm xếp hạng khi số lượt xem của hai bài viết (ví dụ article_id = 103 và 100) bằng nhau.
- Với
RANK(), hai bài viết này cùng được xếp hạng 3, nhưng hạng tiếp theo sẽ bị nhảy cóc thành 5. - Ngược lại, với
DENSE_RANK(), hai bài viết vẫn cùng hạng 3 và hạng kế tiếp là 4, tức là thứ hạng được giữ liên tục.
Aggregate Window Function
Bên cạnh nhóm hàm xếp hạng, chúng ta còn có một nhóm khác thường gặp là aggregate window function. Đây là nhóm các hàm tổng hợp như SUM, AVG, COUNT, MIN, MAX, nhưng thay vì gộp dữ liệu thành một bản ghi duy nhất (như khi dùng GROUP BY), chúng vẫn giữ nguyên chi tiết từng hàng. Chính vì thế, aggregate window functions rất hữu ích trong các bài toán vừa cần giữ chi tiết dữ liệu, vừa cần bổ sung thông tin tổng hợp, chẳng hạn như tính tổng lũy kế số lượt xem cho từng bài viết theo thời gian (ví dụ đã trình bày ở phần Window Function).
Tóm lược
Ta có thể thấy rằng subquery và window function đều là những công cụ mạnh mẽ giúp mở rộng khả năng biểu đạt của SQL. Tuy nhiên, chúng phù hợp với những trường hợp khác nhau. Bảng dưới đây tóm tắt sự khác biệt giữa hai công cụ này:
| Tiêu chí | Subquery | Window Function |
|---|---|---|
| Khái niệm | Truy vấn SQL lồng bên trong một truy vấn khác (có thể ở SELECT, FROM, WHERE...). Kết quả subquery được dùng bởi outer query. | Hàm SQL thực hiện tính toán trên một nhóm dữ liệu (hàng liên quan đến hàng hiện tại). Giữ nguyên chi tiết từng hàng thay vì gộp kết quả. |
| Phân loại | Theo quan hệ với outer query: • Independent: chạy độc lập, tính toán 1 lần. • Correlated: phụ thuộc outer query, chạy lại cho từng hàng. | - Ranking functions: Xếp hạng trong nhóm. • RANK(): nhảy cóc khi trùng giá trị • DENSE_RANK(): liên tục, không nhảy cóc khi trùng giá trị. - Aggregate functions: Áp dụng SUM, AVG, COUNT... trên nhóm của số nhưng giữ nguyên từng hàng. |
| Tính chất | - Independent: chỉ chạy 1 lần, nhanh hơn. - Correlated: chạy lại mỗi hàng, chậm hơn. | Tính toán 1 lần trên các nhóm của số dữ liệu, nhanh hơn correlated subquery |
| Trường hợp nên dùng | Khi cần lấy giá trị tính toán (tổng hợp, biến đổi, lọc) để sử dụng trong outer query. | Khi vừa cần giữ chi tiết từng hàng, vừa cần bổ sung thông tin tổng hợp (ví dụ: tổng lũy kế, xếp hạng, tổng hợp). |
Khi nắm vững đặc điểm và cách sử dụng của từng công cụ, ta sẽ dễ dàng lựa chọn giải pháp tối ưu cho từng bài toán. Điều này không chỉ giúp các câu lệnh SQL trở nên ngắn gọn mà còn nâng cao hiệu suất xử lý dữ liệu.

