AI tạm được hay xuất sắc: Context Engineering quyết định tất cả
Bí quyết để xây dựng một AI đáng tin cậy là gì? Câu trả lời nằm ở kỹ thuật Context Engineering mà kiến trúc sư xây dựng ở đằng sau mỗi hệ thống.

Chúng ta cố gắng xây dựng các trợ lý AI để tự động thực hiện những tác vụ dài hạn, nhưng một ngày bỗng dưng trợ lý này lại đi chệch hướng, lặp lại một hành động vô ích hoặc tệ hơn là phát biểu sai sự thật. Tại sao lại như vậy?
Câu trả lời nằm ở bộ nhớ làm việc của AI, hay còn gọi là cửa sổ ngữ cảnh.
Tại sao Context Engineering lại quan trọng?
Giống như con người, AI không thể suy nghĩ hiệu quả trong một môi trường lộn xộn, nhiễu loạn thông tin. Khi ngữ cảnh cung cấp cho AI bị quá tải, chứa đựng mâu thuẫn hoặc thậm chí là một lỗi sai nhỏ, nó có thể gây ra hiệu ứng domino. Các chuyên gia gọi đây là những thất bại ngữ cảnh (context failure): Từ nhiễm độc ngữ cảnh (context poisoning), nơi một lỗi nhỏ ban đầu làm hỏng toàn bộ chuỗi suy luận, cho đến gây nhiễu (context distraction) và nhầm lẫn (context confusion), khiến mô hình mất tập trung vào nhiệm vụ chính.
"Context Engineering is everything!". Nguồn: Langchain blog
Rõ ràng, việc chỉ 'ném' dữ liệu vào AI và hy vọng vào điều tốt nhất là không đủ. Chúng ta cần một cách tiếp cận bài bản hơn.
Đó chính là lý do Context Engineering (kỹ thuật ngữ cảnh) ra đời. Kỹ thuật này tập trung vào việc quản lý, tối ưu hóa và cung cấp thông tin một cách chiến lược cho LLM. Nó là cầu nối giữa tiềm năng vô hạn của AI và những yêu cầu khắt khe của thế giới thực. Hãy cùng tìm hiểu cách Context Engineering biến những trợ lý AI hay 'ảo giác' thành những cộng sự đáng tin cậy và hiệu quả.
Context Engineering là gì?
Context Engineering tập trung vào việc tổ chức, tối ưu hóa và quản lý tất cả các dạng thông tin được cung cấp cho AI.
Nếu Prompt Engineering là viết lời nhắc tĩnh (static prompt), thì Context Engineering sẽ xây dựng cả một hệ thống tự động phía sau. Nó xem ngữ cảnh là một sản phẩm linh động, được kết nối từ nhiều nguồn thông qua các bước được lập trình sẵn, như truy xuất dữ liệu hay gọi API, đồng thời phải luôn tuân thủ các giới hạn thực tế về chi phí, tốc độ và dung lượng.
Mục đích cốt lõi của nó là chuyển đổi AI từ một công cụ hữu ích thành một đối tác mạnh mẽ, đáng tin cậy. Thay vì chỉ biết sự thật, Context Engineering giúp AI hiểu sâu sắc ý định, nhận biết mục tiêu và hành động chính xác. Việc này không chỉ tối đa hóa hiệu suất và giảm thiểu 'ảo giác', mà còn tối ưu hóa chi phí và độ trễ, là giải pháp để khắc phục các thất bại ngữ cảnh.

Để làm được điều này, người kỹ sư ngữ cảnh phải đóng vai một kiến trúc sư, thiết kế dòng chảy thông tin từ nhiều nguồn đa dạng:
- Nền móng của công trình - ngữ cảnh của người dùng và hệ thống, bao gồm: chỉ dẫn cấp cao (system prompt), yêu cầu cụ thể (user input), vai trò mà AI cần thể hiện (persona) và các quy tắc ràng buộc (constraint).
- Khung sườn chính - bộ nhớ và lịch sử, nơi lưu giữ các cuộc trò chuyện trước đó để duy trì sự liền mạch và học hỏi từ tương tác.
- Hệ thống kết nối công trình với thế giới bên ngoài - khả năng kết nối với các nguồn lực bên ngoài: truy xuất kiến thức từ cơ sở dữ liệu (RAG), sử dụng các công cụ (API) để hành động, và xử lý kết quả trả về.
Việc điều phối nhịp nhàng tất cả các nguồn thông tin này chính là bản chất của Context Engineering.
Context Engineering: Kỹ thuật và cạm bẫy
3 kỹ thuật chính
Để xây dựng một hệ thống ngữ cảnh mạnh mẽ, chúng ta không chỉ đơn thuần lấy dữ liệu mà cần phải xử lý nó một cách có chiến lược. Quá trình này có thể hình dung qua 3 bước chính: Chuẩn bị, tìm kiếm và tinh lọc.
Đầu tiên là bước chuẩn bị dữ liệu. Thay vì cắt văn bản một cách máy móc khiến một câu quan trọng có thể bị gãy đôi, chúng ta có thể áp dụng nhiều cách chia nhỏ dữ liệu (chunking), ví dụ:
- Chia nhỏ dữ liệu theo loại tài liệu: Framework cung cấp các bộ parsers/slitters
- Một số chiến lược chia nhỏ dữ liệu sẽ đọc và tách văn bản tại các điểm ngắt tự nhiên (chẳng hạn như cuối đoạn văn), giúp giữ trọn vẹn ngữ nghĩa cho AI, áp dụng cho LLM apps, RAG apps
Sau khi đã có một thư viện thông tin được sắp xếp khoa học, chúng ta bước vào giai đoạn tìm kiếm. Đây là lúc các kỹ thuật truy xuất thông minh (intelligent retrieval) phát huy tác dụng. Cách tiếp cận hiệu quả nhất là kết hợp nhiều lớp tìm kiếm.
Đầu tiên, tìm kiếm vector sẽ giúp tìm ra các tài liệu có nội dung tương đồng về mặt khái niệm, ngay cả khi chúng không chứa chính xác từ khóa bạn tìm. Song song đó, tìm kiếm từ khóa (keyword search) đảm bảo rằng không một dữ liệu nào bị bỏ sót. Sự kết hợp của hai phương pháp này, gọi là tìm kiếm lai (hybrid search), sẽ tạo ra một danh sách kết quả ban đầu vừa rộng về ý nghĩa, vừa chính xác về chi tiết. Cuối cùng, một bước gọi là sắp xếp lại (re-ranking) sẽ dùng một mô hình chuyên biệt để đánh giá lại danh sách này và đẩy những kết quả phù hợp nhất lên đầu. Việc sử dụng các model embedding mạnh mẽ (như Gemini Text 004) và thuật toán ranking (như BM25) cho các bước này giúp tăng đáng kể chất lượng dữ liệu truy xuất được.
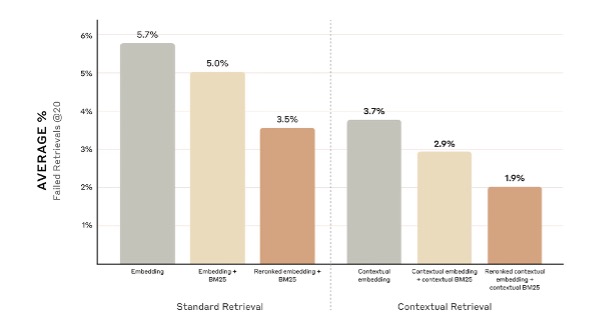
Hiệu quả của việc áp dụng truy xuất thông minh. Nguồn: Anthropic
Cuối cùng, trước khi đưa thông tin cho AI, chúng ta cần tinh lọc nó. Đây là bước 'chưng cất' thông tin, hay còn gọi là nén ngữ cảnh (context compression). Thay vì đưa cho AI cả một trang sách, kỹ thuật này sẽ tự động rút ra đúng một vài câu trả lời trực tiếp cho câu hỏi, giúp AI tập trung vào đúng vấn đề, đồng thời tiết kiệm đáng kể chi phí và tăng tốc độ phản hồi.
Cạm bẫy vô hình
Tuy nhiên, ngay cả khi nắm vững các kỹ thuật trên, hành trình triển khai Context Engineering vẫn sẽ có những bẫy vô hình và khó đoán.
Cạm bẫy lớn nhất là ảo tưởng rằng AI có thể tự xử lý dữ liệu lộn xộn. Việc ném toàn bộ kho tài liệu lỗi thời và mâu thuẫn vào hệ thống sẽ tạo ra một AI phản chiếu đúng sự hỗn loạn đó. Bài học ở đây rất rõ ràng: làm sạch và quản lý dữ liệu (data curation) phải là bước số 0.
Một trong những lỗi khó phát hiện nhất nhưng lại gây ra hậu quả nghiêm trọng là Lost in the Middle. Lỗi này xảy ra khi LLM có xu hướng đọc lướt, chỉ tập trung vào các thông tin ở phần đầu và cuối prompt, khiến nội dung quan trọng bị lãng quên nếu bị chèn ở giữa. Ví dụ như trong tập dữ liệu cho AI đọc có câu "Chính sách hoàn trả cho sản phẩm XYZ là 30 ngày", nhưng lại đặt nó vào giữa hàng loạt lịch sử trò chuyện. Kết quả là AI trả lời "Tôi không tìm thấy thông tin", không phải vì thông tin không có, mà vì nó đã bị "lạc trôi" ở giữa. Bài học xương máu ở đây là: vị trí rất quan trọng. Hãy luôn đặt thông tin cốt lõi nhất ở gần đầu hoặc cuối prompt.

Nếu dữ liệu là bộ não của AI, thì công cụ (tools) chính là tay và chân. Tuy nhiên, AI không nhìn thấy công cụ, nó chỉ đọc được mô tả về công cụ. Việc coi nhẹ mô tả công cụ sẽ khiến AI rơi vào ma trận nhầm lẫn, không biết nên dùng 'cánh tay' nào cho đúng việc. Nếu mô tả chung chung như "lấy thông tin người dùng" sẽ khiến AI không thể phân biệt được công cụ này với một công cụ khác cũng có chức năng tương tự. AI cũng không biết cần cung cấp tham số nào (user_id hay email?). Hậu quả là AI sẽ chọn sai công cụ, hoặc gọi đúng công cụ nhưng lại thất bại vì thiếu tham số. Bài học ở đây là hãy viết mô tả như cách viết tài liệu kỹ thuật: rõ ràng, súc tích và nêu bật sự khác biệt.
Cuối cùng, một sai lầm phổ biến khi xây dựng chatbot là để bộ nhớ phát triển vô hạn. Nguyên nhân xuất phát từ cách tiếp cận ngây thơ bằng việc nối toàn bộ lịch sử trò chuyện vào mỗi yêu cầu mới. Ban đầu, cách này có vẻ hiệu quả, nhưng nhanh chóng dẫn đến những hệ quả nghiêm trọng: chi phí tăng vọt và tốc độ phản hồi chậm chạp. Tệ hơn nữa, một bộ-nhớ-quá-tải sẽ khiến AI nhiễu loạn, thiếu mạch lạc và lặp lại vấn đề "Lost in the Middle". Do đó, quản lý bộ nhớ một cách chiến lược là điều bắt buộc. Thay vì chỉ nối chuỗi, chúng ta có thể áp dụng các kỹ thuật tinh vi hơn:
- Tóm tắt (Summarization): Đây là phương pháp phổ biến nhất, dùng một lệnh gọi LLM riêng để tóm tắt cuộc trò chuyện. Bản tóm tắt này sẽ được dùng làm bộ nhớ cho các lượt sau, giúp giữ lại ý chính mà vẫn tiết kiệm token.
- Cửa sổ trượt (Sliding Window): Một cách đơn giản là chỉ giữ lại N tin nhắn gần nhất. Kỹ thuật này nhanh và rẻ, nhưng có nguy cơ đánh mất những thông tin quan trọng được đề cập ở đầu cuộc hội thoại.
- Cô đọng rồi chọn lọc (Condense then Select): Đây là một phương pháp lai mạnh mẽ. Hệ thống vừa tạo ra một bản tóm tắt (condense) để có cái nhìn tổng quan, vừa lưu trữ các tin nhắn riêng lẻ dưới dạng vector. Khi có câu hỏi mới, nó không chỉ lấy bản tóm tắt mà còn tìm kiếm và chọn lọc (select) những tin nhắn cũ có liên quan nhất. Cách này kết hợp được cả bối cảnh tổng thể và các chi tiết cụ thể, mang lại hiệu quả cao nhất.
Việc lựa chọn kỹ thuật nào phụ thuộc vào yêu cầu cụ thể của ứng dụng, nhưng việc chủ động quản lý bộ nhớ không phải là một tùy chọn, mà là điều kiện tiên quyết để xây dựng một chatbot thông minh và ổn định trong dài hạn.
Cám dỗ của 1 triệu token context window
Tại sao phải cần kỹ thuật phức tạp khi ta có thể ném hết mọi thứ vào prompt?
Đây là một ý tưởng đầy cám dỗ khi các mô hình với cửa sổ ngữ cảnh khổng lồ ra đời.
Suy nghĩ này, tuy hấp dẫn, nhưng lại bỏ qua những đánh đổi cơ bản về chi phí, tốc độ và độ chính xác. Việc xử lý một triệu token không chỉ đắt đỏ và chậm chạp, mà còn có thể làm trầm trọng thêm vấn đề "Lost in the Middle", biến việc tìm kiếm một chi tiết quan trọng trở thành nhiệm vụ mò kim đáy bể. Hơn nữa, ngay cả một triệu token cũng chỉ là một giọt nước so với đại dương kiến thức của một doanh nghiệp, nơi mà việc truy xuất thông minh vẫn là con đường duy nhất.
Vậy, ý nghĩa thực sự của cuộc cách mạng này là gì?
Cửa sổ ngữ cảnh lớn không phải là lý do để chúng ta lười biếng, mà là một sự nâng cấp vượt bậc cho bộ công cụ của người kỹ sư. Nó không thay thế Context Engineering, mà là trao quyền cho nó.
Giờ đây, thay vì chỉ truy xuất vài đoạn văn bản ngắn, chúng ta có thể nạp vào ngữ cảnh hàng chục tài liệu liên quan, cho phép AI có cái nhìn toàn cảnh và đưa ra những câu trả lời sâu sắc hơn. Đối với các AI Agent phức tạp, bộ nhớ khổng lồ này cho phép chúng duy trì một 'dòng suy nghĩ' dài và liền mạch hơn. Cửa sổ ngữ cảnh lớn đã biến không gian làm việc của AI từ một chiếc bàn chật hẹp thành một phân xưởng rộng lớn, mở ra những khả năng mới cho các tác vụ suy luận phức tạp mà trước đây chúng ta không dám mơ tới.
Context Engineering là một hành trình
Tóm lại, Context Engineering không phải là một giải pháp tạm thời hay một mẹo kỹ thuật, mà là một sự thay đổi trong tư duy xây dựng ứng dụng AI.
Từ việc quản lý dữ liệu đầu vào, tối ưu hóa truy xuất, cho đến việc tận dụng chiến lược các cửa sổ ngữ cảnh lớn, tất cả đều cho thấy rằng chất lượng của AI phụ thuộc trực tiếp vào chất lượng của ngữ cảnh mà chúng ta cung cấp. Trong tương lai, sự khác biệt giữa một ứng dụng AI 'tạm được' và một ứng dụng 'xuất sắc' sẽ không nằm ở mô hình, mà ở trình độ của người kỹ sư ngữ cảnh đằng sau nó.
Tham khảo
The rise of context engineering
Lost in the Middle: How Language Models Use Long Contexts
Context Engineering for Agents
Context Engineering - What it is, and techniques to consider

