Truy vấn dữ liệu thời AI (Phần 1): Tạo database index dùng MCP server và Claude
Tự động tạo và đề xuất database index với sự kết hợp giữa MCP server và Claude mở ra cách tiếp cận mới trong tối ưu truy vấn dữ liệu. Tuy nhiên, trên môi trường production nên cân nhắc các đánh đổi về chi phí cũng như vai trò của database admin.

Đây là bài viết mở đầu về cách các hệ quản trị cơ sở dữ liệu khai thác giá trị từ dữ liệu. Trong phần này, chúng ta sẽ tìm hiểu về database index - nền tảng cơ bản giúp truy vấn dữ liệu nhanh chóng và hiệu quả. Bài viết này sẽ gồm hai phần chính:
- Back to basic: Giải thích các loại index phổ biến và các tình huống sử dụng thực tế (use case).
- Sử dụng AI trong index: Hướng dẫn ứng dụng MCP server kết hợp với mô hình ngôn ngữ lớn (LLM) để tự động duy trì hoặc đề xuất các index phù hợp.
Ở phần tiếp theo, chúng ta sẽ khám phá database vector, một giải pháp hiệu quả cho các bài toán tìm kiếm ngữ nghĩa và ứng dụng AI.
Back to basic
Index là gì?
Index trong cơ sở dữ liệu (CSDL) là cấu trúc dữ liệu giúp tăng tốc độ truy vấn. Nó tương tự như mục lục của một cuốn sách. Không có index, hệ quản trị phải quét toàn bộ bảng dữ liệu. Việc này sẽ rất chậm nếu bảng có hàng triệu dòng.
Tuy nhiên, không có một loại index nào là tối ưu cho mọi tình huống. Nhưng tại sao không tạo index cho mọi cột, hoặc tối ưu mọi thứ một lúc? Câu trả lời nằm ở một nguyên lý RUM Conjecture (Giả thuyết RUM).
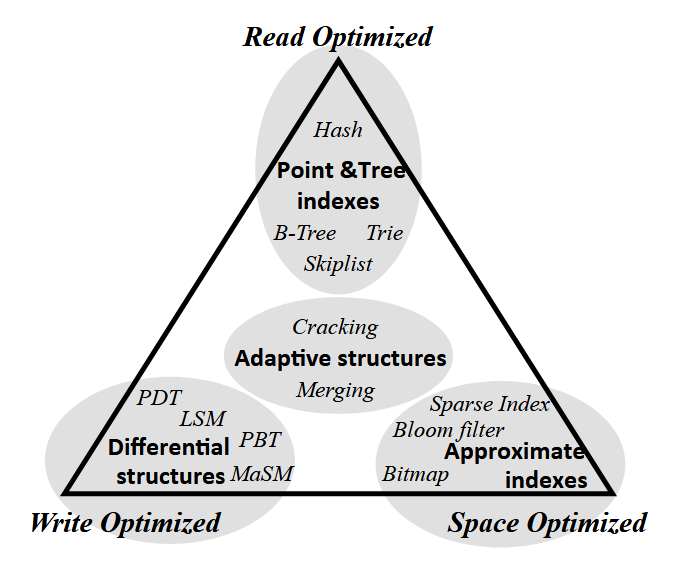
Mô hình RUM Conjecture
Nguyên lý này cho rằng, khi thiết kế cách lưu trữ và truy cập dữ liệu (access method), ta cần đánh đổi giữa 3 yếu tố chính:
- Read latency (thời gian truy xuất)
- Update cost (chi phí cập nhật)
- Memory overhead (chi phí bộ nhớ)
Không thể tối ưu đồng thời cả 3 yếu tố này mà ta chỉ có thể chọn tối đa hai yếu tố để tối ưu và chấp nhận đánh đổi ở yếu tố còn lại.
Phân loại index
Index có thể được phân loại theo 2 tiêu chí: Tổ chức dữ liệu vật lý (Data organization) và Cấu trúc dữ liệu được sử dụng để xây dựng index (Data structure).
1. Data organization
Cách tổ chức dữ liệu vật lý trong index ảnh hưởng trực tiếp đến hiệu năng truy vấn. Mỗi tình huống truy vấn sẽ có cách lựa chọn loại index phù hợp.
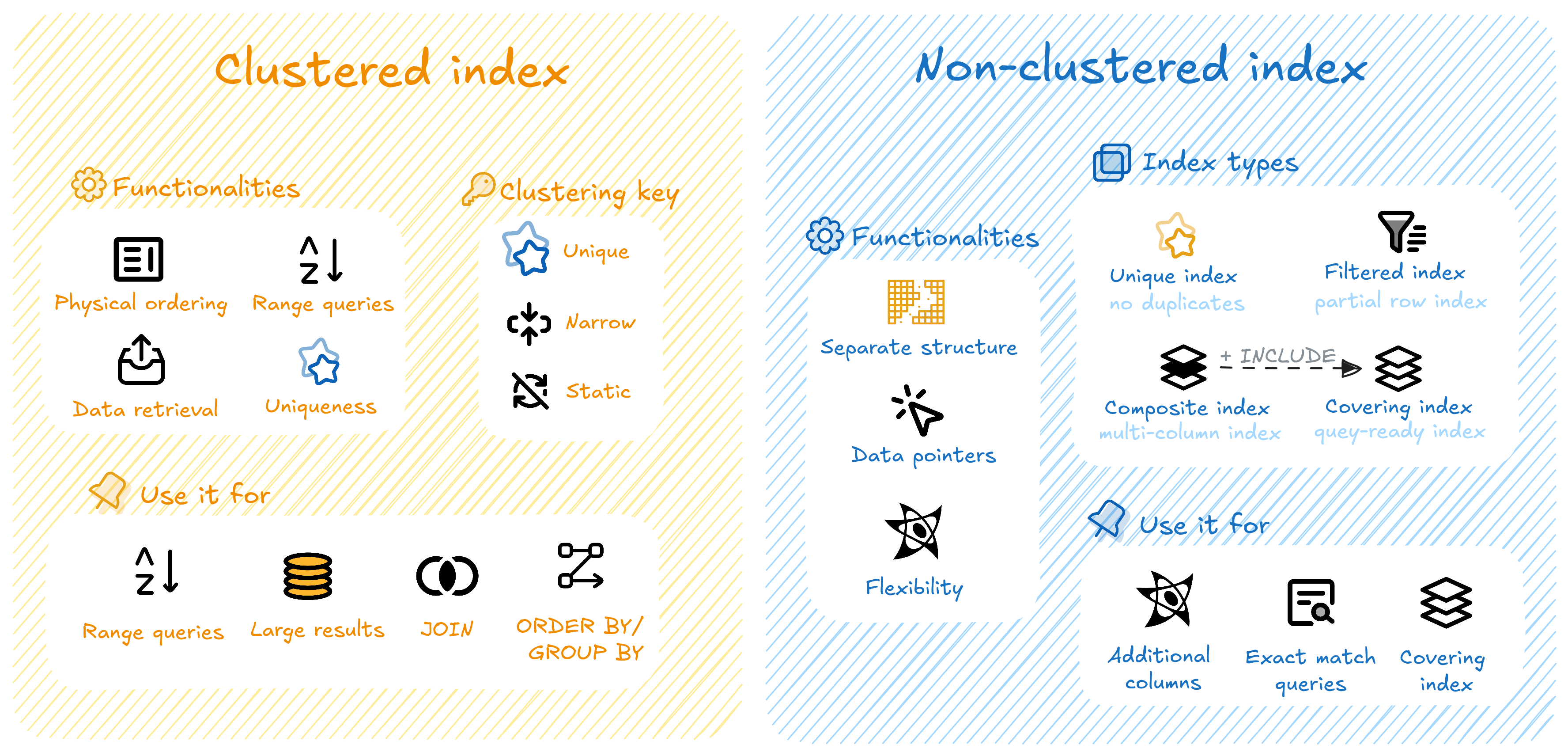
Hai cách tổ chức dữ liệu vật lý trong index
Clustered-index:
- Dữ liệu được sắp xếp vật lý theo thứ tự của index index
- Mỗi bảng chỉ có một clustered index
- Hiệu quả với truy vấn theo khoảng giá trị (
BETWEEN,>,<,>=,<=) và các truy vấnJOIN,ORDER BY,GROUP BY
Tham khảo tiêu chí chọn clustering key tốt.
Non-clustered Index:
- Index tách biệt khỏi dữ liệu gốc, chỉ chứa khóa và con trỏ tham chiếu đến dữ liệu
- Một bảng có thể có nhiều non-clustered index
- Hiệu quả với các truy vấn tìm kiếm chính xác (
WHERE) và truy vấn chỉ dùng một vài cột cụ thể (covering index)
Các biến thể phổ biến của non-clustered index:

2. Data structure
Bên cạnh cách tổ chức dữ liệu, cấu trúc dữ liệu của index cũng ảnh hưởng lớn đến hiệu năng truy vấn. Mỗi loại cấu trúc có ưu và nhược điểm riêng, phù hợp với từng kiểu truy vấn hoặc khối lượng đọc/ghi khác nhau. Các hệ quản trị hiện nay thường đã tích hợp sẵn các cấu trúc này, nên thay vì chọn thủ công, ta cần hiểu dữ liệu và nhu cầu truy vấn để chọn hệ quản trị phù hợp.
Chúng ta sẽ cùng tìm hiểu 5 cấu trúc dữ liệu phổ biến được dùng để xây dựng index.
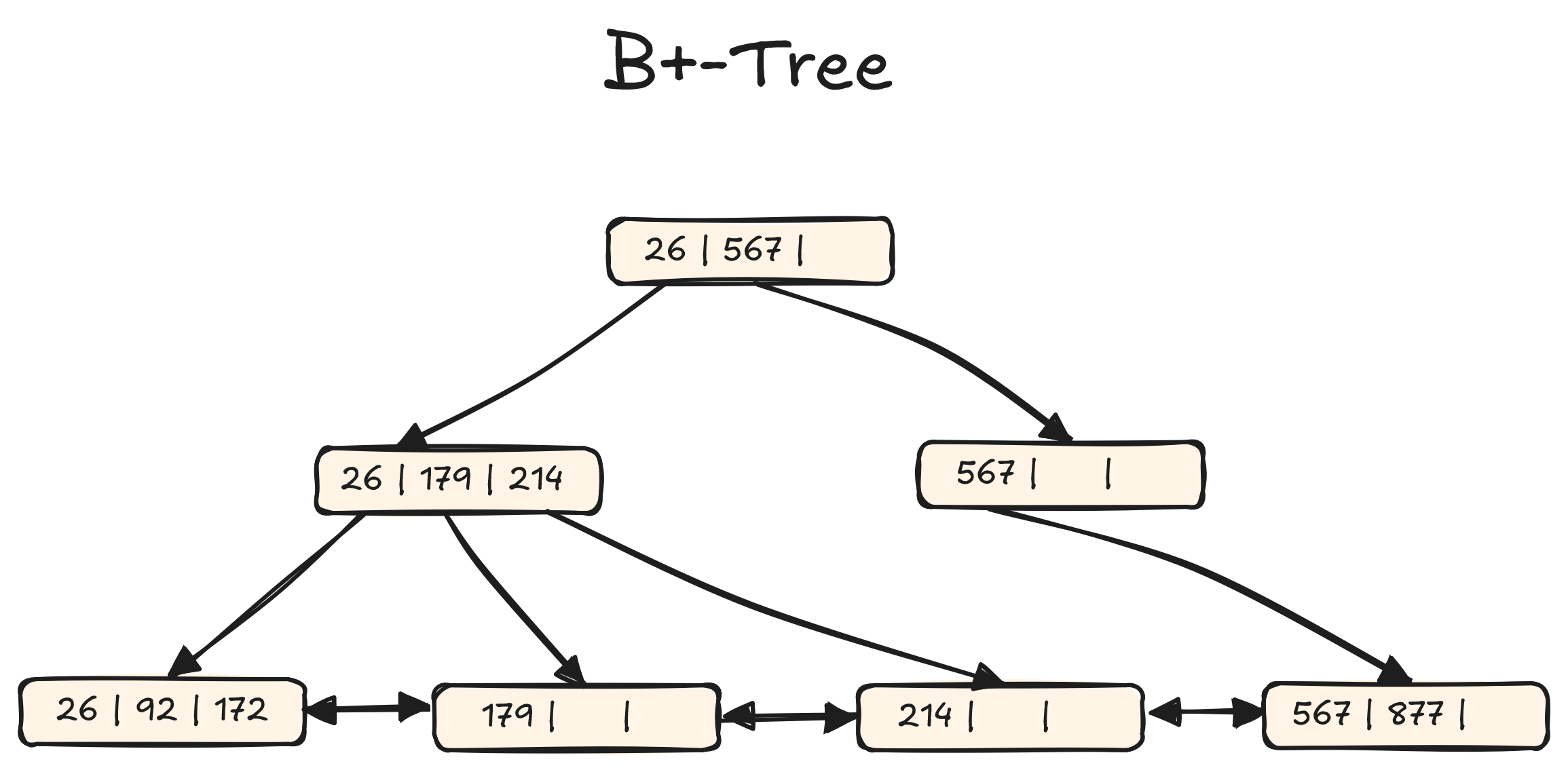
Đầu tiên, B+-tree là cấu trúc dữ liệu dạng cây cân bằng, phổ biến nhất trong các hệ quản trị cơ sở dữ liệu truyền thống. Dữ liệu được lưu theo thứ tự tăng dần và tất cả giá trị thực nằm ở các nút lá, giúp truy cập theo thứ tự rất nhanh. Đây là cấu trúc được sử dụng phổ biến để triển khai clustered và non-clustered index đã được đề cập ở phần trước.
Use case: read-heavy
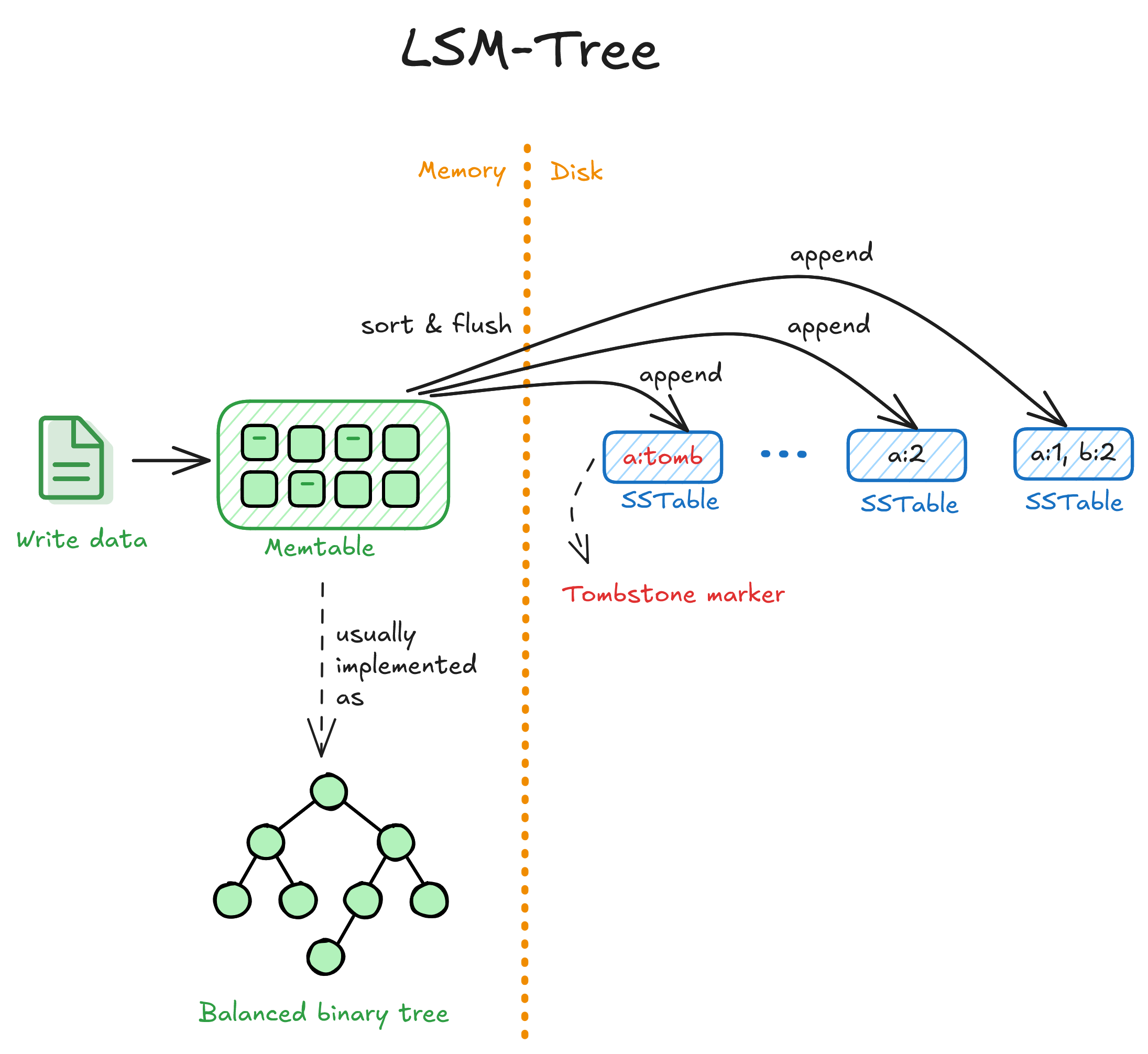
Tiếp theo, LSM-tree (Log-Structured Merge Tree) là cấu trúc tối ưu cho ghi/chèn dữ liệu. Dữ liệu mới được ghi vào bộ nhớ (memory buffer), sau đó ghi thành từng khối (SSTables) xuống đĩa. Các khối này được trộn định kỳ (merge) để tối ưu truy xuất.
Use case: write-heavy, ví dụ logging system, time-series database.
Hoạt động tương tự như hash table, Hash index dùng hash function để chuyển giá trị khóa (ví dụ: 'abc@example.com') thành một mã số, sau đó dùng mã đó để tra cứu nhanh vị trí lưu trữ dữ liệu – gần giống như cách chúng ta tra từ điển theo bảng chữ cái.
Use case: Truy vấn cần tìm kiếm chính xác theo giá trị, ví dụ WHERE email = 'abc@example.com'
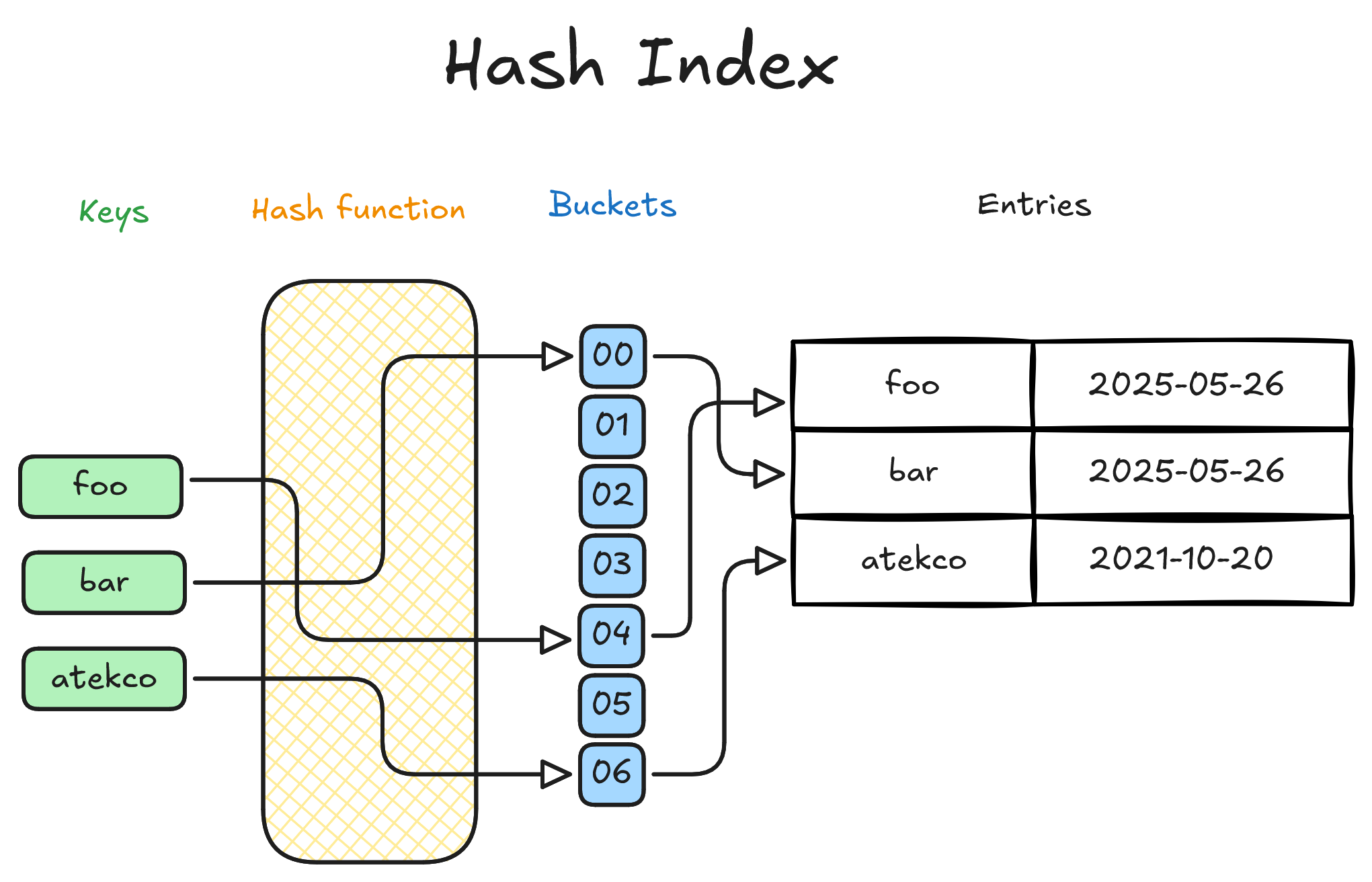
Theo mình biết thì hiệu năng Hash index trong thực tế không khác biệt quá nhiều so với B+- tree, nhất là khi xét đến các giới hạn như không hỗ trợ truy vấn theo khoảng. Ngoài ra, do hash index hoạt động tốt nhất khi dữ liệu nằm trong RAM, nên với dataset lớn, B+-tree thường là lựa chọn bền hơn.
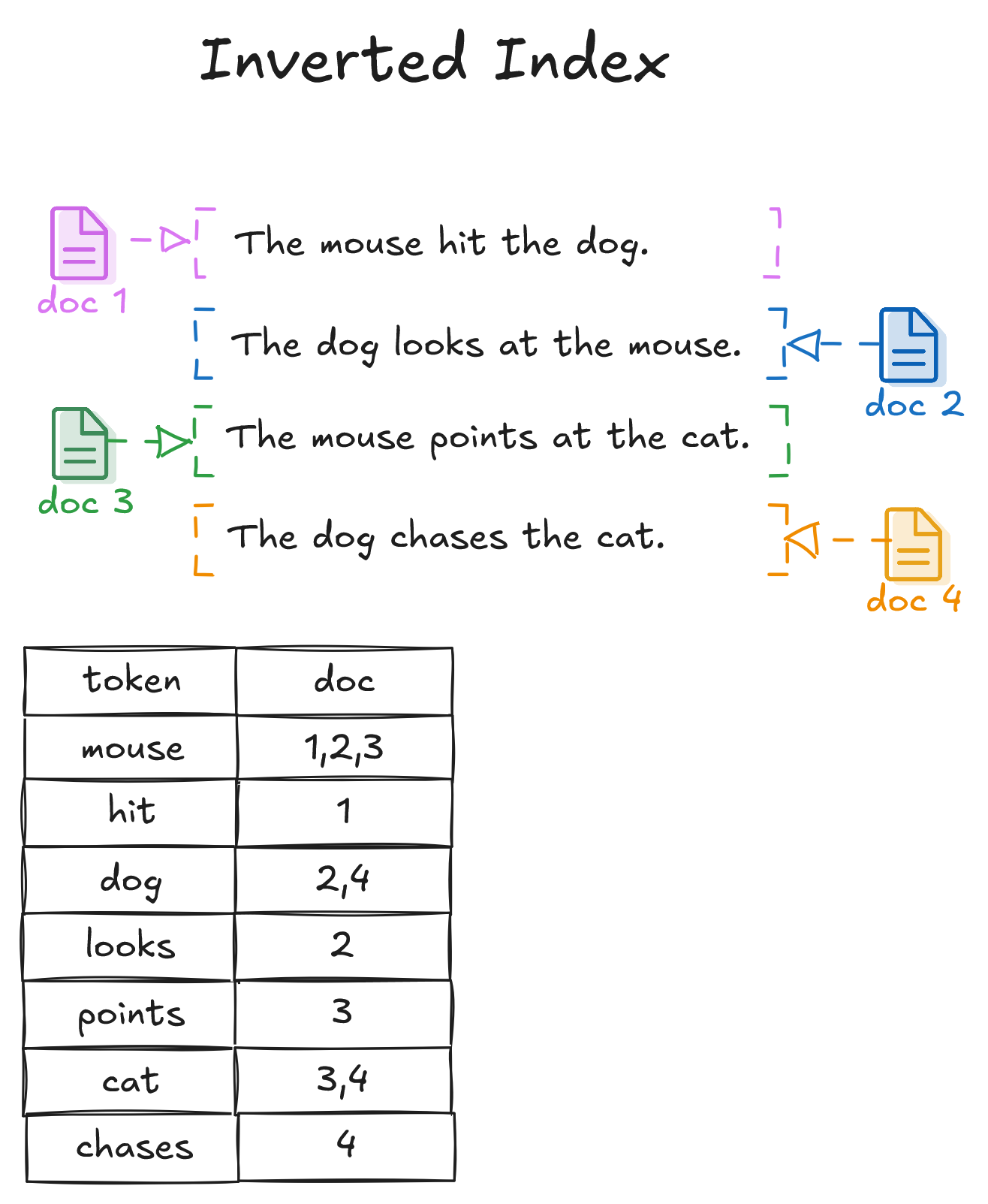
Kế đến, Inverted index là cấu trúc liên kết từ từ khóa → danh sách tài liệu chứa từ đó. Khác với các index truyền thống, nó hỗ trợ tìm kiếm từ hoặc cụm từ trong văn bản.
Use case:
- Full-text search (tìm kiếm văn bản)
- Tìm bài viết chứa từ khóa cụ thể
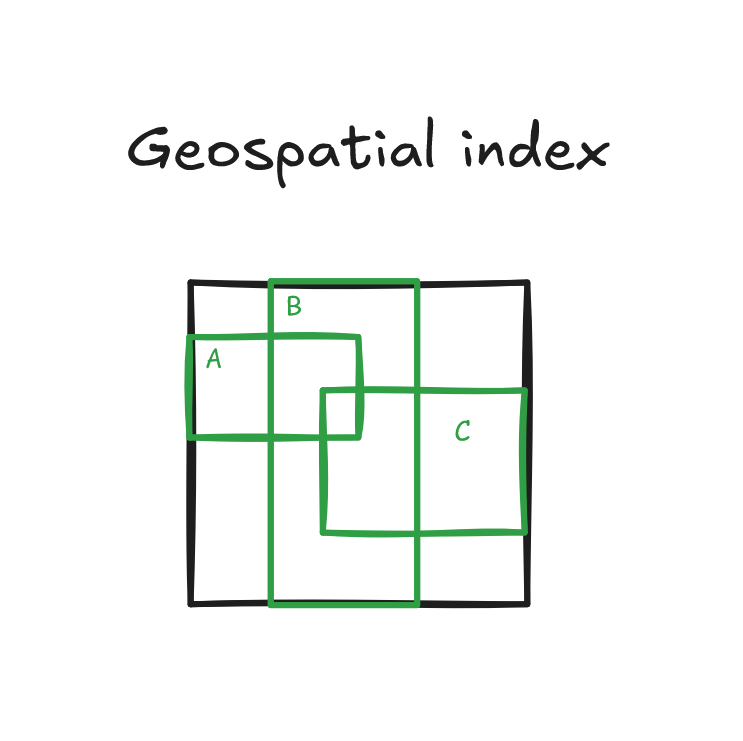
Cuối cùng, Geospatial index là cấu trúc đặc biệt (R-tree, GiST...) để xử lý dữ liệu không gian như điểm, đường, vùng (tọa độ).
Use case:
- Truy vấn dữ liệu địa lý như tìm điểm gần nhất hay là nằm trong vùng A
- Hệ thống bản đồ, định vị, GIS
Sử dụng MCP server để đề xuất và tạo index
Các mô hình AI hiện nay dù mạnh nhưng vẫn có giới hạn nhất định, ví dụ không thể truy cập trực tiếp vào file hệ thống, database, hay thực thi câu lệnh SQL. Đây chính là lý do vì sao chúng ta cần đến MCP server.
MCP server có thể hiểu đơn giản là một chương trình trung gian, đóng vai trò cầu nối giữa AI model và các công cụ, dữ liệu, hoặc dịch vụ bên ngoài. MCP server cung cấp các công cụ cần thiết, còn AI đóng vai trò như một 'quản gia' - AI yêu cầu sử dụng công cụ nào là do nó tự quyết định dựa trên ngữ cảnh và mục đích.
Sau đây là một demo cụ thể sử dụng Python, PostgreSQL và MCP Server để AI (trong demo này là Claude) có thể phân tích truy vấn SQL và tự động đề xuất các index phù hợp.
Demo thiết lập MCP server và tích hợp AI
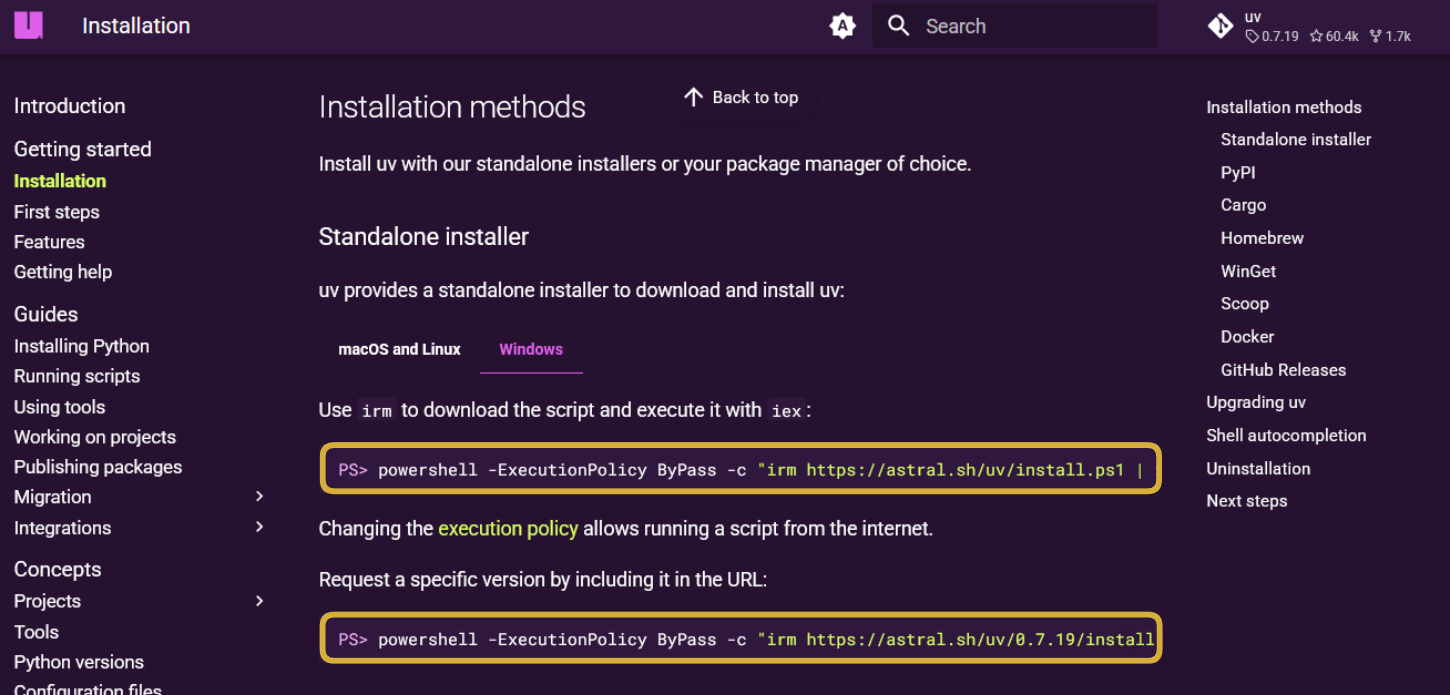
Bước 1: Cài đặt uv (Python package manager thay thế pip )
Chọn lệnh cài đặt phù hợp với hệ điều hành của máy tại đây.
Bước 2: Chuẩn bị thư mục project MCP server
Tạo một thư mục mới (ví dụ: mcp_server_demo) và mở bằng editor quen thuộc (VS Code, Pycharm,...).
Bước 3: Khởi tạo project Python và cài đặt các thư viện cần thiết
Mở terminal trong thư mục vừa tạo, chạy lần lượt các lệnh:
uv init .
uv add "mcp[cli]" psycopg2
mcp[cli]: Thư viện quản lý MCP Server.psycopg2: Thư viện để Python tương tác trực tiếp với PostgresSQL.
Bước 4: Tạo và cấu hình MCP server với PostgreSQL
Copy đoạn code dưới đây vào file main.py trong project, điều chỉnh cấu hình DB ( DB_NAME , DB_USER ,...) đúng với database PostgreSQL của bạn.
import json
from typing import List
import psycopg2
from psycopg2 import sql
from mcp.server.fastmcp import FastMCP
# Initialize an MCP server
mcp = FastMCP("Postgres_Demo")
# Connection to local PostgreSQL database
def get_db_connection():
return psycopg2.connect(
dbname="DB_NAME",
user="DB_USER",
password="DB_PASSWORD",
host="DB_HOST", # default: localhost
port="DB_PORT", # default: 5432
)
@mcp.tool()
def query_data(sql_query: str) -> str:
"""
Executes a safe SELECT SQL query against the PostgreSQL database and
returns the results in JSON format.
Args:
sql_query (str): A SQL query string that must start with 'SELECT'.
Returns:
str: A JSON-formatted string containing either the query results (as
a list of row tuples) or an error message if the query is invalid or
execution fails.
"""
# Reject non-SELECT queries for safety
if not sql_query.strip().lower().startswith("select"):
return json.dumps({"error": "Only SELECT queries are allowed."})
try:
# Use context manager to ensure the connection is properly closed
with get_db_connection() as conn:
# Open a cursor to perform database operations
with conn.cursor() as cursor:
# Execute the user's SQL SELECT query
cursor.execute(sql_query)
rows = cursor.fetchall()
except Exception as e:
return json.dumps({"error": str(e)})
return json.dumps(rows, indent=2)
@mcp.tool()
def get_table_indexes(table_name: str) -> str:
"""
Retrieves all indexes defined on a given table in the PostgreSQL
database.
Args:
table_name (str): The name of the table whose indexes should be
listed.
Returns:
str: A JSON-formatted string containing a list of indexes (name and
definition),or an error message if the query fails.
"""
try:
# Use context manager to ensure the connection is properly closed
with get_db_connection() as conn:
with conn.cursor() as cursor:
# Query PostgreSQL system catalog for indexes on the specified table
cursor.execute(""" SELECT indexname, indexdef FROM pg_indexes WHERE tablename = %s""", (table_name,))
rows = cursor.fetchall()
return json.dumps([{"indexname": r[0], "indexdef": r[1]} for r in rows], indent=2)
except Exception as e:
return json.dumps({"error": str(e)})
@mcp.tool()
def create_index(index_name: str, table_name: str, columns: str) -> str:
"""
Creates a new index on specified columns for a given table in the PostgreSQL
database.
Args:
index_name (str): The name to assign to the new index.
table_name (str): The name of the table on which to create the index.
columns (str): A comma-separated list of column names to include in the
index.
Returns:
str: A JSON-formatted string indicating success, or an error message if
creation fails.
"""
try:
# Construct the SQL CREATE INDEX statement (use with caution to avoid SQL injection)
sql = f'CREATE INDEX {index_name} ON {table_name} ({columns})'
# Use context manager to ensure the connection is properly closed
with get_db_connection() as conn:
with conn.cursor() as cursor:
cursor.execute(sql)
return json.dumps({"status": "Index created"})
except Exception as e:
return json.dumps({"error": str(e)})
if __name__ == "__main__":
mcp.run()
Các công cụ được định nghĩa trong đoạn code:
query_data: Cho phép AI thực hiện các truy vấn SELECT.get_table_indexes: AI kiểm tra các index hiện có trên bảng.create_index: AI tạo index mới theo phân tích của nó.
Bước 5: Cài đặt tool vào MCP server
Chạy lệnh sau trong terminal:
mcp install main.py
Bước 6: Mở ứng dụng Claude và kết nối MCP server
Mở ứng dụng Claude để AI nhận diện MCP server và công cụ vừa cấu hình.
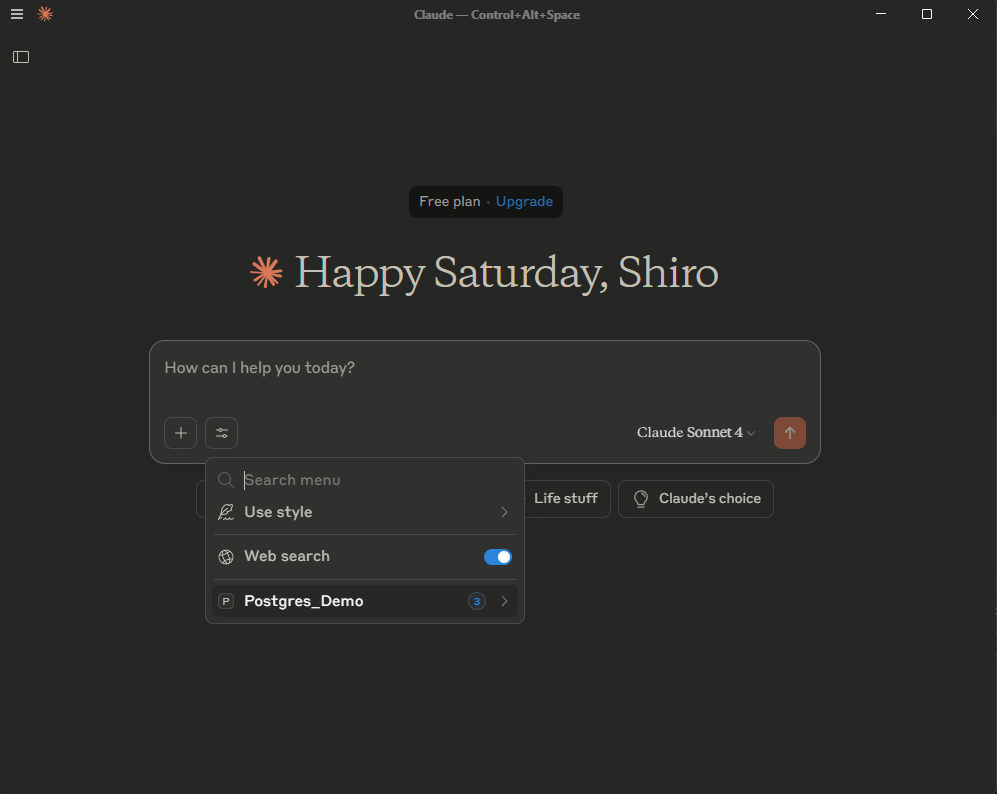
Nếu gặp lỗi Server disconnected, thực hiện cấu hình file claude_desktop_config.json như hướng dẫn dưới đây, sau đó restart ứng dụng Claude.
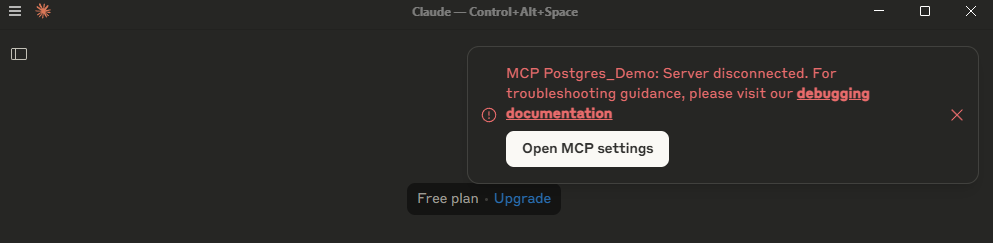
- Vào File → Settings → Developer → Edit Config

- App sẽ mở thư mục chứa file claude_desktop_config.json . Mở file này và chỉnh sửa nội dung cấu hình như bên dưới. Thay dòng
/ABSOLUTE/PATH/TO/mcp_server_demobằng đường dẫn tuyệt đối đến thư mục project MCP server trên máy.
{
"mcpServers": {
"Postgres_Demo": {
"command": "uv",
"args": [
"--directory",
"/ABSOLUTE/PATH/TO/mcp_server_demo",
"run",
"main.py"
]
}
}
- Mở Task Manager, tìm và đóng hoàn toàn ứng dụng Claude, rồi mở lại.
Bước 7: Thử nghiệm AI tự động đề xuất và tạo index
Hãy thử đặt câu hỏi, ví dụ: “Bạn có thể gợi ý index cho bảng book không?” - Quan sát xem Claude sử dụng đúng tool mình đã thiết lập chưa.
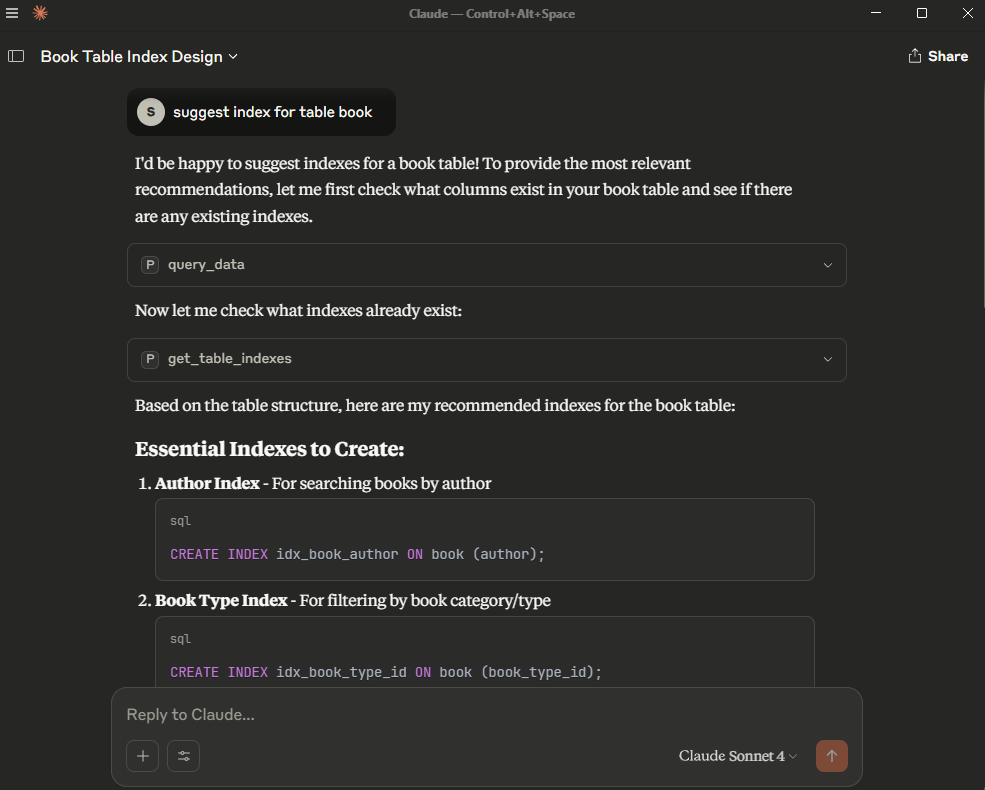
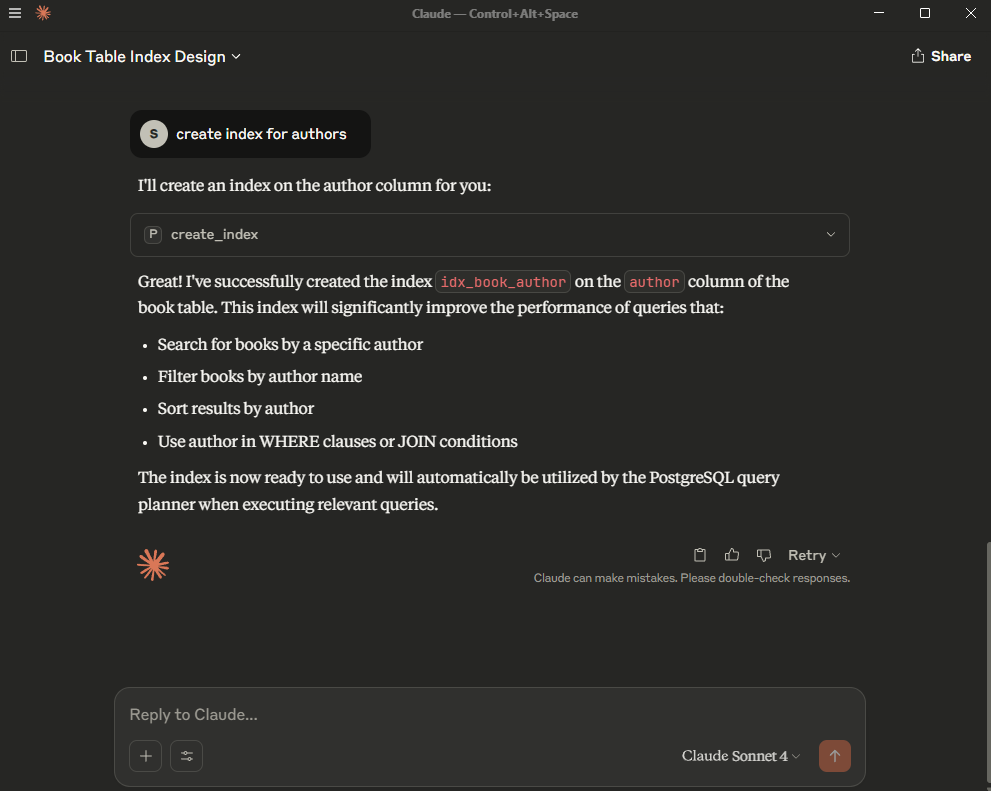
Kinh nghiệm sử dụng AI để tối ưu index
Thiết kế tool rõ ràng là yếu tố then chốt
Khi định nghĩa một tool trong MCP server, cần kèm mô tả chi tiết, rõ ràng về mục đích sử dụng và đầy đủ ngữ cảnh. Điều này giúp AI hiểu đúng ngữ cảnh sử dụng của từng tool và biết khi nào nên gọi tool nào, tránh dùng sai mục đích.
Khi nào nên áp dụng AI để tối ưu index?
AI đặc biệt hữu ích khi bạn phải phân tích workload lớn hoặc nhiều truy vấn phức tạp, giúp nhanh chóng xác định điểm nghẽn và đề xuất index phù hợp. Hoặc nếu DBA cần cần có insight nhanh về tình trạng hoạt động của các truy vấn, AI sẽ tiết kiệm đáng kể thời gian phân tích thủ công.
Cần cân nhắc gì trước khi đưa vào production?
Dù AI là công cụ đắc lực trong việc phân tích và đề xuất nhanh các giải pháp ban đầu, quyết định cuối cùng vẫn nên thuộc về DBA hoặc quản trị viên có kinh nghiệm. Hãy lưu ý:
- AI chỉ phân tích dựa trên workload tại thời điểm cụ thể, do đó không đảm bảo tính tối ưu lâu dài
- Tạo quá nhiều index có thể làm tăng chi phí lưu trữ và overhead khi ghi dữ liệu
Tóm lại, việc tạo index không chỉ là “tạo index nào để tăng tốc độ truy vấn”, mà là tạo index nào đủ nhanh để xứng đáng với chi phí lưu trữ và cập nhật. Hiểu rõ các loại index và các use case sẽ giúp chúng ta đưa ra quyết định đúng đắn trong từng trường hợp. Đặc biệt, nếu biết cách dùng MCP Server để giúp AI giao tiếp với các hệ thống bên ngoài như PostgreSQL, việc tạo và duy trì các index sẽ không còn là một bài toán khó với người làm dữ liệu.

