Tích phân về AI - Apple Intelligence
Cùng đi tìm lời giải về cách Apple đã sử dụng để đưa các mô hình GenAI lên thiết bị di động trong tham vọng thay đổi định nghĩa AI = Apple Intelligence.
.jpg)
Đúng vậy, với Apple, AI = Apple Intelligence. Khác với rất nhiều công bố trước đây, AI luôn là 1 cụm từ Apple tránh nhắc tới, nhưng trong WWDC24 gần đây, AI (Apple Intelligence) lại là cụm từ nổi bật nhất. Theo như công bố, Apple Intelligence có thể tham gia các tác vụ và trải nghiệm người dùng như viết và tinh chỉnh văn bản, ưu tiên và tóm tắt thông báo, tạo hình ảnh vui nhộn cho các cuộc trò chuyện với gia đình và bạn bè, cũng như thực hiện các hành động trong ứng dụng để đơn giản hóa các tương tác giữa các ứng dụng.
Nhiều quan ngại về privacy đã nổ ra khi Apple Intelligence được công bố, đặc biệt khi Apple tuyên bố OpenAI là đối tác cung cấp một số model. Điển hình như việc Elon Musk đã tweet rằng nếu Apple tích hợp OpenAI ở mức độ hệ điều hành, ông sẽ cấm các thiết bị Apple trong các công ty của mình.
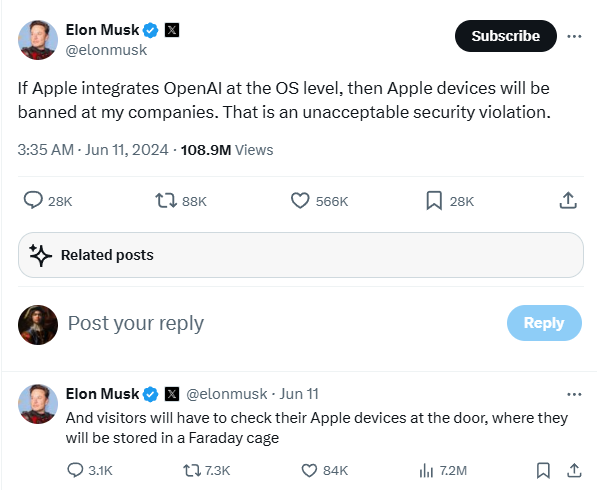
Nguồn: x.com
Rõ ràng Apple đã lường trước các phản ứng này. Vì vậy, Tim Cook đã nói rằng bất cứ khi nào có những thông tin cần đến OpenAI, người dùng sẽ nhận được thông báo xem có muốn thực hiện hay không, và dữ liệu sẽ chỉ được gửi đi khi có sự đồng thuận của người dùng. Do đó, ta có thể cho rằng, hầu hết các tác vụ của Apple Intelligence sẽ được thực hiện trên thiết bị hoặc trên hệ thống điện toán đám mây riêng của Apple. Nếu không, điều đó sẽ gây khó chịu về trải nghiệm người dùng.
Vậy, Apple thực hiện điều này bằng cách nào?
Trước hết, hãy xem xét những thách thức của on-device AI.
Những thách thức của on-device AI
Có thể điểm ra những thách thức lớn nhất khi thực hiện on-device AI:
- Specialization: Một trong những thách thức lớn nhất khi triển khai on-device AI là đảm bảo các mô hình AI có thể đảm bảo chất lượng của kết quả cho từng tác vụ cụ thể. Điều này đòi hỏi sự tinh chỉnh cẩn thận để đảm bảo rằng các mô hình có thể hiểu và thực hiện tốt các yêu cầu từ người dùng. Ví dụ, viết và tinh chỉnh văn bản đòi hỏi một loại mô hình AI khác với việc tạo hình ảnh vui nhộn cho các cuộc trò chuyện.
- Size: Thách thức thứ hai là kích thước của các mô hình AI. Để các mô hình này có thể hoạt động hiệu quả trên các thiết bị như iPhone, chúng phải đủ nhỏ gọn. Ví dụ như iPhone 15 pro chỉ có 6GB RAM, do đó đây là một thách thức lớn. Hãy nhớ rằng mới chỉ đầu năm ngoái thôi, các mô hình tốt đều có ít nhất 7 tỷ parameters, chưa nói tới việc các model phổ biến là hàng trăm tỷ parameters. Ngoài ra, nhà phát triển cũng cần tìm cách để các mô hình chuyên môn hóa (Specialization) không tốn quá nhiều bộ nhớ - một điều vô cùng đắt đỏ đối với các sản phẩm nhà táo.
- Performance: Cuối cùng, một thách thức không kém phần quan trọng là hiệu suất của các mô hình AI trong quá trình inference và tiêu thụ năng lượng. Các mô hình AI phải có khả năng cho ra kết quả nhanh chóng để cung cấp trải nghiệm người dùng mượt mà. Việc này đồng thời cũng khiến tiêu thụ năng lượng nhiều hơn, Apple phải tìm cách cân bằng giữa hiệu suất và tiêu thụ năng lượng để đảm bảo rằng người dùng có thể sử dụng các tính năng AI mà không lo lắng về việc sạc pin liên tục. Điều này đòi hỏi sự tối ưu hóa ở cả mức phần cứng và phần mềm, từ việc thiết kế chip xử lý cho đến việc tối ưu hóa thuật toán.
Vậy, Apple làm gì để đối mặt với các thách thức này? Dưới đây là những dự đoán của mình, dựa trên những thông tin mà Apple đã thông báo.
CoreML
CoreML là framework của Apple, giúp tích hợp các machine learning model vào những thiết bị của mình, đồng thời loại bỏ những phức tạp liên quan đến NVIDIA/CUDA. Với sự chủ động này, Apple hoàn toàn không phụ thuộc vào bất kỳ nhà cung cấp bên ngoài nào và có thể tối ưu hóa các mô hình AI theo cách riêng của mình. Apple cũng đã tích hợp sẵn nhiều tối ưu hóa trong CoreML (ví dụ như Palettization - phương pháp sẽ nhắc tới phía sau), đảm bảo rằng các biện pháp này đã được kiểm tra kỹ lưỡng và sẵn sàng sử dụng trên các thiết bị của Apple.
Một điểm lợi nữa khi chạy AI trên các thiết bị của Apple là khả năng tối ưu hóa để tiêu tốn ít năng lượng hơn. Các nhà phát triển ứng dụng trên Android thường phải đối mặt với sự đa dạng của chip/GPU trên các thiết bị và thiếu sự hỗ trợ của các API tối ưu, điều này làm cho việc triển khai AI trở nên phức tạp và ít hiệu quả hơn. Nhờ CoreML, Apple không chỉ cung cấp một môi trường phát triển thuận lợi mà còn đảm bảo rằng các tác vụ AI hoạt động mượt mà và hiệu quả trên các thiết bị của mình.
Sử dụng các foundation model với kích thước nhỏ
Những demo của Apple Intelligence cho thấy, nhiều khả năng các model on device của Apple chưa phải thuộc dạng multimodal, mà chia ra làm hai dạng chính là language (text) và image.
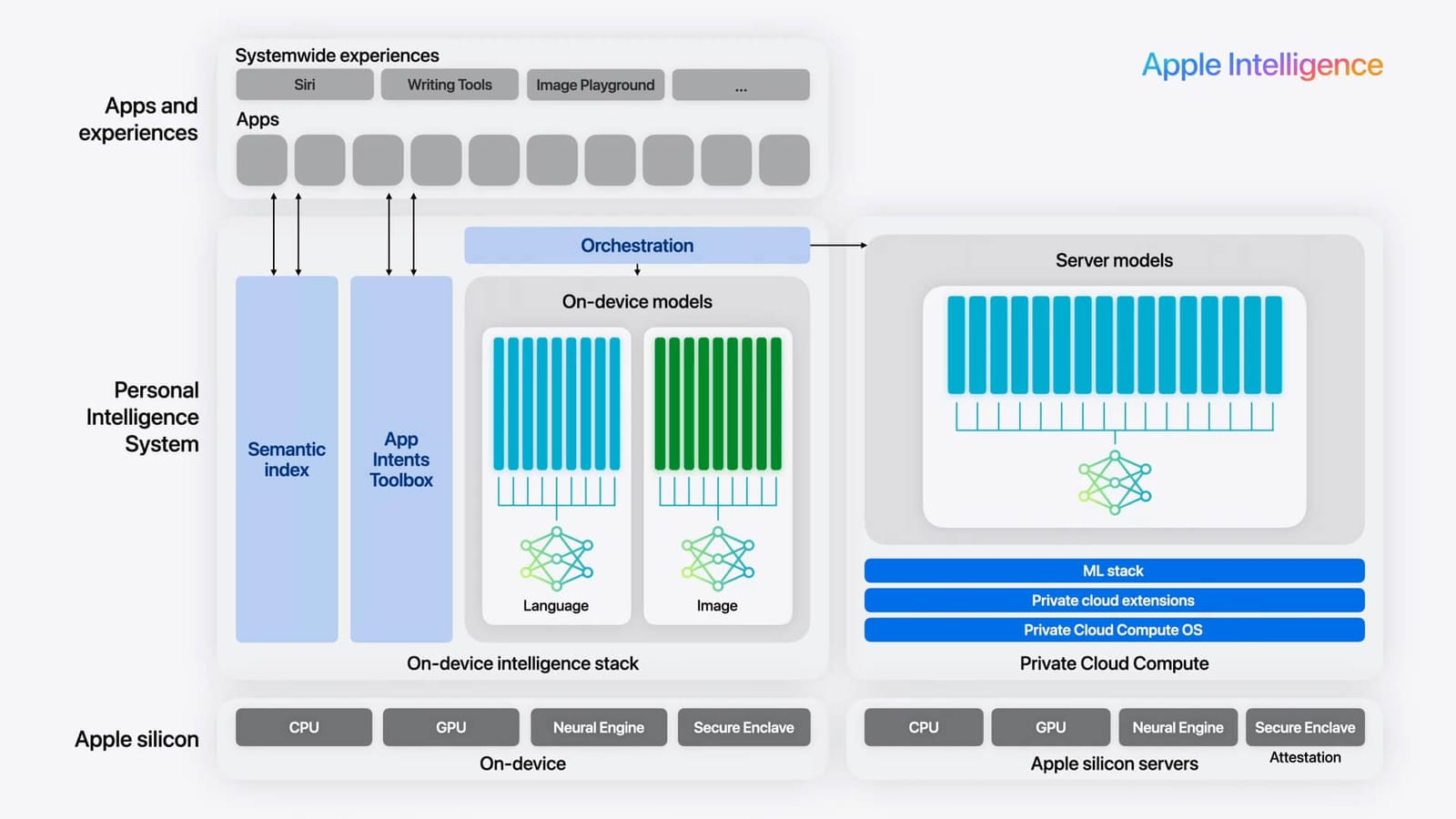
Minh họa về hệ sinh thái của Apple Intelligence. Nguồn: Apple
Text
Apple sử dụng một mô hình có 3 tỷ parameters (3b) để làm LLM giải quyết các tác vụ liên quan tới text. Đây là 1 model không lớn nhưng có kết quả rất tốt về Safety, Instruction-Following Eval (IFEval) và Writing.
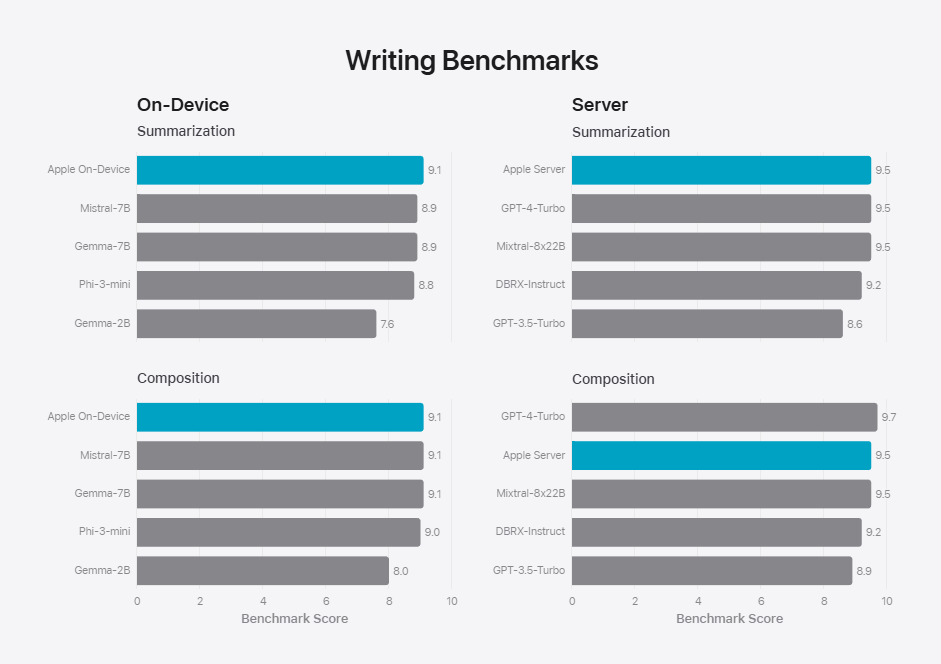
Model của Apple so với các model cùng kích thước. Nguồn: Apple
Với kích thước 3b, có thể cho rằng foundation model mà Apple dùng chính là một bản đã hiệu chỉnh của OpenELM, đây là mô hình LLM open-source của Apple mới được tung ra cuối tháng 4 vừa rồi.
Ngoài ra, LLM của Apple còn sử dụng thêm một số phương pháp để optimization bằng cách sử dụng grouped-query attention (tương tự như OpenELM) để tăng tốc độ text generation của model.
Apple cũng sử dụng chung một bảng vocab embedding cho input và output, từ đó có thể giảm được một phần yêu cầu về bộ nhớ cần sử dụng. Ở các thiết bị, model dùng 49k token vocab size (một điểm khác so với chỉ 32k size của OpenELM-3B-Instruct). Trên private server, model sử dụng có vocab size lớn hơn là 100k.
Apple cũng có dùng context pruning. Đây là một phương pháp giảm chi phí computation của LLM bằng việc bỏ bớt một số token không mang nhiều ý nghĩa khi thực hiện text generation.
Image
Apple không đưa ra nhiều thông tin về model mà họ sử dụng, nhưng chúng ta có thể cho rằng model mà Apple sử dụng vẫn dựa trên:
- Text-encoder: text encoder là 1 thành phần rất quan trọng trong việc giúp những bức ảnh đầu ra có thể tuân theo đúng instruction và tạo ra được những bức ảnh với instruction phức tạp. Cuối năm ngoái, Apple ra mắt MobileCLIP, một họ text-encoder model thân thiện với mobile, nhỏ hơn và latency thấp hơn. Xem thêm tại đây.
- Về phía Image decoder, không rõ Apple hiện sử dụng model gì. Ta chỉ có thể biết Apple sử dụng một diffusion model mà thôi. Rất có thể, đó là một version sử dụng low-bit palletization (Mixed-bit palettization), tương tự như model tại đây.
Nén model
Hiện nay, các model chạy ở local ngoài việc có số lượng parameter không quá lớn, thì thường được dùng kèm các biện pháp nén (compression). Điều này có thể giảm kích thước của model vài lần, giúp giảm bộ nhớ sử dụng một cách rất đáng kể. Hai phương pháp chính mà Apple dùng gồm có low-bit pallettization và quantization.
Low-bit paletization
Đây là một phương pháp nén model của Apple, có thể xem thêm tại Palettization Overview. Giải thích đơn giản, đây là phương pháp dựa trên weight clustering, ta tạo các cluster dựa trên weight của model, sau đó tạo một bảng lookup table (LUT) tương ứng với các centroid của cluster, và lưu các weight tương ứng với index của cluster mà weight thuộc về.
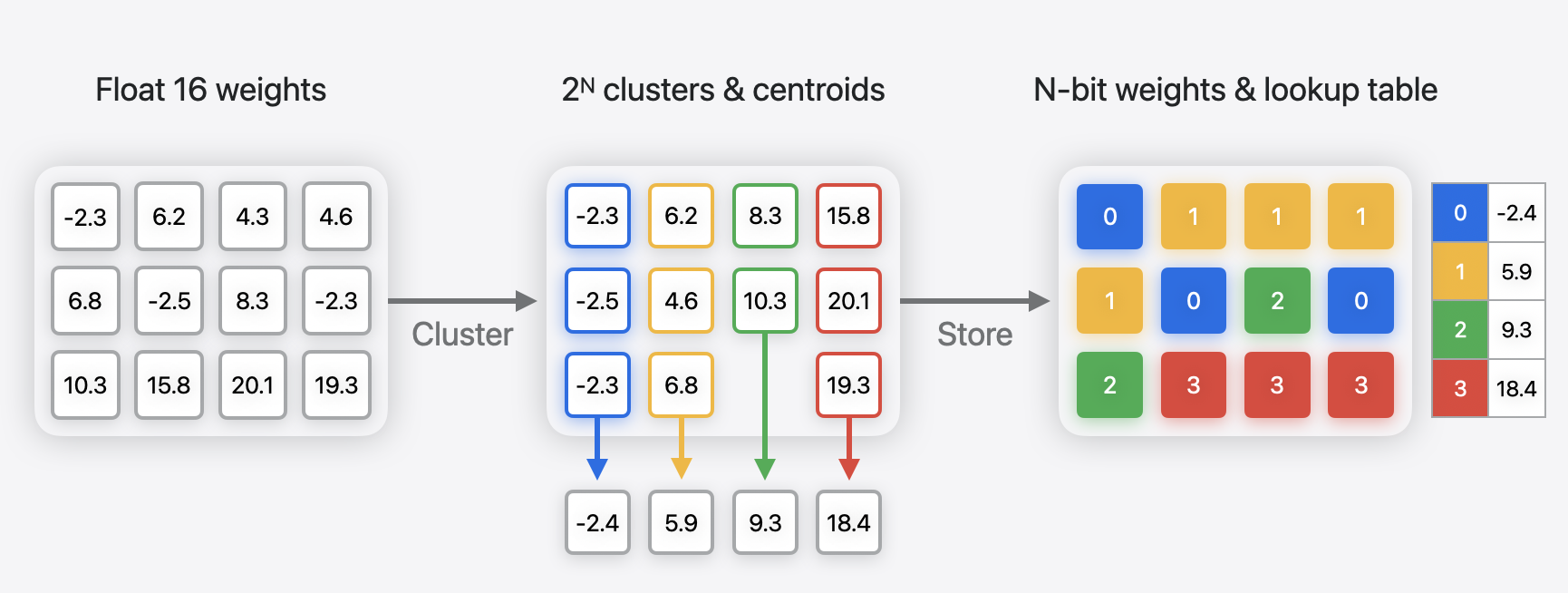
Minh họa về Palettization. Nguồn: Apple
Quantization
Quantization là phương pháp khá phổ biến hiện nay để giảm memory sử dụng khi thực hiện inference các LLM. Bản thân Apple cũng có một tool để có thể tối ưu việc lựa chọn bit rate cho các phép toán là Talaria . Apple thực hiện quantization ở activation cũng như embedding layers.
Có thể xem thêm về thuật toán GPTQ và QAT Apple dùng tại đây.
Kết quả
Kết hợp giữa việc sử dụng các foundation model kích thước nhỏ, các biện pháp tối ưu và nén model, Apple có thể cho ra kết quả rất đáng kinh ngạc: trên iPhone 15 Pro, time-to-first-token latency chỉ khoảng 0.6ms (trên prompt token), cũng như generation rate đạt tới 30 tokens/s. Một con số rất ổn cho nhiều tác vụ trên một thiết bị vô cùng nhỏ gọn.
Sử dụng các Adapter (LoRA)
Để có thể thực hiện các tác vụ chuyên môn hóa tốt hơn, đặc biệt khi sử dụng các foundation với kích thước nhỏ và đã được nén nhiều lần, Apple sử dụng rất nhiều bộ Adapter cho nhiệm vụ này.
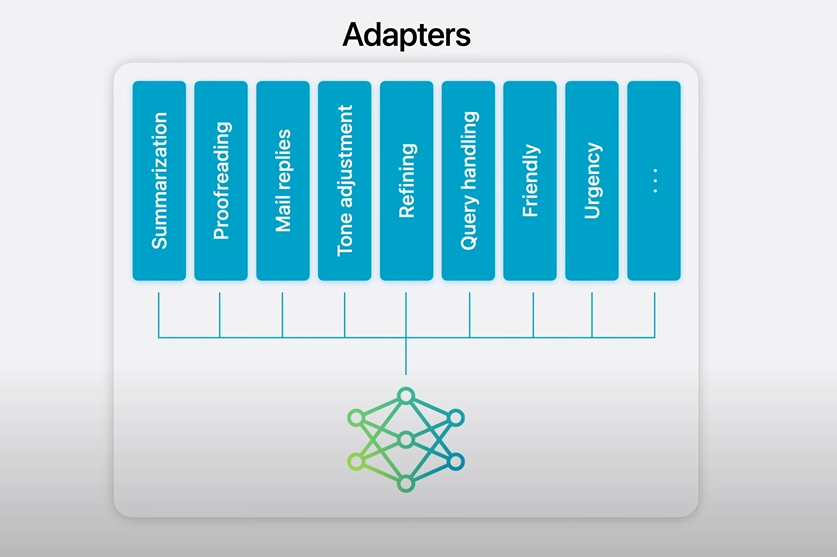
Nhiều Adapter ứng với nhiều tác vụ. Nguồn: Apple
Các Adapter, về cơ bản chính là các module neural network nhỏ, có thể ghép vào các layer của một model, sau đó được fine-tune cho các tác vụ chuyên biệt. Với việc sử dụng Adapters, foundation model vẫn được giữ nguyên, đảm bảo về memory cũng như các kiến thức chung, trong khi vẫn có thể cung cấp giải pháp chuyên môn hóa tối ưu cho từng tác vụ.
Các Adapters cũng vì thế mà có kích thước vừa phải, chỉ khoảng vài chục MB. Kích thước nhỏ của các Adapters tạo điều kiện cho các thiết kế UX và workflow linh hoạt hơn.
Để tìm hiểu thêm về Adapter, bạn có thể xem thêm về LoRA (Low-Rank Adaptation) và các biến thể khác.
Agentic workflow
Trong keynote của mình, Apple đã sử dụng rất nhiều ví dụ để cho thấy sự linh hoạt của Apple Intelligence với các input, ví dụ như:
- Show me all the photo of Mom, Olivia and me
- Pull up the files that Joz shared with me last week
- Play the podcast that my wife sent the other day
Với việc sử dụng nhiều foundation model và các adapter để điều chỉnh, Apple Intelligence không chỉ hoạt động như một model đơn lẻ, một công cụ hỗ trợ cho một tác vụ cụ thể mà cần phải linh hoạt trong các tác vụ, có thể tự động lựa chọn, điều phối các model liên quan dựa trên các yêu cầu của người dùng.
Để làm được điều này, nhiều khả năng Apple đã sử dụng một hệ thống agentic để điều phối dựa trên context và yêu cầu của người dùng. Để hiểu thêm về agentic, bạn có thể xem thêm bài viết Agentic Workflow: Hiệu quả hơn nhờ 'mô phỏng' chuyên gia.
Ví dụ như Apple sử dụng nhiều adapter (LoRA) cho các style image generation khác nhau, thì khi đó, việc chọn Adapter nào là phù hợp để dùng là một tác vụ cần agentic. Bạn có thể xem thêm một agentic workflow tương tự là Stylus.

Một điều nữa

Tuy không được nhắc tới, nhưng với tính năng Semantic search của Siri, có lẽ Apple đã sử dụng RAG để thực hiện tính năng này. Để có thể tìm kiếm dựa trên ý nghĩa thay vì keyword, nhiều khả năng Apple thực hiện:
- Một vector database xây dựng sẵn trong thiết bị, và index là multimodal (text, images, record)
- Nhiều khả năng Apple cũng có kèm theo một re-ranking model để cho ra kết quả tốt hơn, điều thường gặp ở Advanced RAG
Vài suy nghĩ cuối
Một trong những vấn đề lớn của GenAI là việc nó cần nguồn tài nguyên khổng lồ để có thể hoạt động. Tuy nhiên, Apple đã chứng minh rằng việc đưa các mô hình GenAI lên thiết bị di động không chỉ khả thi mà còn có thể đạt được hiệu suất và chất lượng cao.
Từ những điều mà Apple đã làm, chúng ta có thể học hỏi được rất nhiều kỹ thuật trong việc ứng dụng các mô hình GenAI trong các ứng dụng, và phần lớn những phương pháp này có thể ứng dụng rộng khắp, không chỉ riêng trên các thiết bị của Apple mà ở bất cứ đâu.
Tham khảo
WWDC24: Platforms State of the Union
Introducing Apple’s On-Device and Server Foundation Models - Apple Machine Learning Research
Talking Tech and AI with Tim Cook!
Understanding Apple’s On-Device and Server Foundation Models release

