So sánh chi tiết các định dạng Lakehouse
Hudi, Iceberg và Delta Lake là ba định dạng Lakehouse được sử dụng phổ biến hiện nay. Mỗi hệ thống có những đánh đổi quan trọng về mặt thiết kế, rất cần chúng ta cân nhắc cẩn thận nhu cầu để đưa ra giải pháp phù hợp nhất.

Trong lĩnh vực quản lý dữ liệu phân tích, sự xuất hiện của data lake (hồ dữ liệu) đánh dấu một bước tiến quan trọng, kết hợp thành công những ưu điểm vượt trội của hai hệ thống truyền thống: data lake chi phí thấp và data warehouse (kho dữ liệu) hiệu suất cao.
Data lake nổi tiếng với khả năng lưu trữ dữ liệu phi cấu trúc khổng lồ với chi phí tiết kiệm. Tuy nhiên, điểm hạn chế của chúng nằm ở khả năng truy vấn và phân tích dữ liệu phức tạp. Ngược lại, data warehouse tuy mạnh mẽ về phân tích nhưng lại tốn kém và thiếu linh hoạt trong việc mở rộng lưu trữ dữ liệu đa dạng.
Lakehouse giải quyết những hạn chế này bằng cách sử dụng các định dạng lưu trữ mở như Delta Lake, Apache Hudi và Apache Iceberg. Các định dạng này cung cấp khả năng giao dịch, lập chỉ mục và các chức năng DBMS trên nền tảng lưu trữ giá rẻ như Amazon S3, cho phép truy cập và xử lý dữ liệu hiệu quả.
Sự phổ biến của lakehouse ngày càng tăng bởi những lợi ích thiết thực:
- Hiệu quả về chi phí: Lưu trữ dữ liệu đa dạng với giá thành thấp
- Khả năng mở rộng: Dễ dàng mở rộng dung lượng lưu trữ mà không ảnh hưởng hiệu suất
- Linh hoạt: Hỗ trợ truy vấn và phân tích dữ liệu phức tạp trên nhiều công cụ xử lý khác nhau
- Tính minh bạch: Dữ liệu được lưu trữ ở dạng gốc, dễ dàng truy cập và kiểm tra
Nhiều công ty lớn như Databricks, Uber và Netflix đã sử dụng lakehouse cho hệ thống phân tích dữ liệu của họ. Hơn 70% dữ liệu khách hàng của Databricks ghi vào Delta Lake, Uber và Netflix chạy phân tích của họ trên Hudi và Iceberg. Các dịch vụ dữ liệu đám mây hàng đầu như Synapse, Redshift, EMR và Dataproc cũng đang tích hợp hỗ trợ cho các định dạng này.
Các hệ thống lakehouse rất khó thiết kế vì một số lý do:
- Chúng cần phải chạy trên các hệ thống lưu trữ giá rẻ, chẳng hạn như Amazon S3 hoặc Azure Data Lake Storage (ADLS), có độ trễ tương đối cao so với cụm kho dữ liệu tùy chỉnh truyền thống và cung cấp các đảm bảo giao dịch yếu.
- Chúng nhằm mục đích hỗ trợ nhiều quy mô khối lượng công việc và mục tiêu khác nhau - từ việc load và transform hàng trăm petabyte dữ liệu, đến việc hoạt động như một data warehouse, nơi có nhu cầu tương tác trên các bảng nhỏ hơn, và có nhu cầu độ trễ dưới một giây.
- Các hệ thống lakehouse nhằm mục đích có thể truy cập từ nhiều engine tính toán thông qua các chuẩn dữ liệu mở, không giống như hệ thống data warehouse truyền thống mà bao gồm cả engine xử lý dữ liệu. Các giao thức được sử dụng để truy cập dữ liệu cần được thiết kế cẩn thận để hỗ trợ các ACID transaction, khả năng mở rộng và hiệu suất cao, điều này đặc biệt khó khăn khi hệ thống lakehouse chạy trên hệ thống lưu trữ có độ trễ cao và không hỗ trợ transaction.
Những thách thức này dẫn đến một số đánh đổi thiết kế mà chúng ta thấy trong ba hệ thống lakehouse phổ biến được sử dụng ngày nay.
Quản lý transaction
Hudi, Iceberg và Delta Lake đều là các định dạng bảng mã nguồn mở cho phép lưu trữ dữ liệu theo dạng transactional trong data lake. Tuy nhiên, có một số điểm khác biệt chính trong cách xử lý transaction đồng thời.
Cả ba hệ thống lakehouse này đều quản lý transaction bằng cách sử dụng nhiều phiên bản (multi-version concurrency control - MVCC). Một siêu dữ liệu (metadata) xác định các phiên bản file nào thuộc về bảng nào. Khi một transaction bắt đầu, nó sẽ đọc metadata để lấy snapshot của bảng và đọc dữ liệu từ snapshot. Transaction được commit bằng cách cập nhật metadata một cách nguyên tử, tức là mọi thay đổi về dữ liệu phải đảm bảo trọn vẹn, nếu các tiến trình thực hiện thành công hoặc là sẽ không có bất kỳ sự thay đổi nào về dữ liệu nếu có sự cố tiến trình xảy ra.
Delta Lake dựa vào dịch vụ lưu trữ để cung cấp tính nguyên tử thông qua tính năng như put-if-absent, còn Hudi và Iceberg sử dụng khóa ở bảng (table-level locks) được triển khai trong ZooKeeper, Hive MetaStore. Cần chú ý là cách triển khai dựa trên khóa (lock-based) phổ biến nhất là sử dụng Hive MetaStore, lại không đảm bảo; ví dụ, trong Iceberg, một transaction có thể bị ghi bẩn (dirty write) nếu khóa Hive MetaStore hết thời gian giữa nhịp tim khóa (lock heartbeat) và ghi metadata.
Để đảm bảo tính isolated giữa các transaction, Delta Lake, Hudi và Iceberg đều sử dụng optimistic concurrency control. Transaction được xác thực trước khi commit để kiểm tra xem có xung đột nào với các transaction khác đang commit đồng thời.
Các transaction luôn đọc dữ liệu từ snapshot có commit hợp lệ tính đến thời điểm transaction bắt đầu và chỉ có thể commit nếu tại thời điểm commit không có transaction nào ghi dữ liệu định ghi. Do đó, nó có khả năng tuần tự hóa (serializability), là kết quả của một chuỗi transaction tương đương với thứ tự transaction, nhưng không nhất thiết phải theo thứ tự trong nhật ký giao dịch (transaction log).
Delta Lake có thể tuỳ chọn thực hiện việc kiểm tra này cho các hoạt động chỉ đọc (ví dụ câu lệnh SELECT), làm giảm đồng thời đọc-ghi nhưng cung cấp tính strict serializability, nghĩa là tất cả các giao dịch (bao gồm cả đọc) được tuần tự hóa theo thứ tự chúng xuất hiện trong nhật ký giao dịch.
Phương thức đọc ghi dữ liệu
Các giải pháp lakehouse áp dụng hai chiến lược cập nhật dữ liệu, với những đánh đổi khác nhau giữa hiệu suất đọc và ghi:
- Chiến lược ghi đè (Copy-On-Write - CoW): Xác định các file chứa các bản ghi cần cập nhật và ghi đè chúng vào các file mới với dữ liệu đã cập nhật. Điều này dẫn đến việc ghi nhiều lần (write amplification) nhưng không cần đọc nhiều lần (read amplification).
- Chiến lược hợp nhất khi đọc (Merge-On-Read - MoR): Không ghi đè các file. Thay vào đó, MoR ghi ra các file bổ sung chứa thông tin về các thay đổi ở cấp độ bản ghi và kết hợp các thay đổi này khi truy vấn dữ liệu. Do đó, MoR có độ ghi ít lần hơn (tức là ghi nhanh hơn CoW - Sao chép khi ghi) nhưng cần đọc nhiều lần hơn (tức là đọc chậm hơn CoW). Đôi khi việc giảm thiểu độ trễ ghi (write latency) với đánh đổi là tăng độ trễ đọc (read latency) là cần thiết cho các khối lượng công việc thường xuyên áp dụng các thay đổi ở cấp độ bản ghi (ví dụ: sao chép liên tục các thay đổi từ cơ sở dữ liệu này sang cơ sở dữ liệu khác).
Cả ba hệ thống đều hỗ trợ CoW, vì hầu hết các khối lượng công việc của lakehouse đều ưu tiên hiệu suất đọc cao. Iceberg và Hudi hiện đang hỗ trợ MoR, Delta cũng có kế hoạch hỗ trợ MoR.
MoR của Iceberg (và tương lai là Delta) sử dụng các file 'đánh dấu' phụ để đánh dấu các bản ghi trong các file Parquet/ORC. Tại thời điểm truy vấn, các bản ghi tombstone này được lọc ra. Việc cập nhật bản ghi được thực hiện bằng cách đánh dấu bản ghi hiện có và ghi bản ghi được cập nhật vào các tệp Parquet/ORC.
Ngược lại, MoR của Hudi lưu trữ tất cả các bản ghi Insert/Delete/Update trong các file Avro. Khi truy vấn, Hudi kết hợp các thay đổi này trong khi đọc dữ liệu từ các tệp Parquet. Điểm chú ý là Hudi theo mặc định sẽ loại bỏ trùng lặp và sắp xếp dữ liệu được nhập theo khóa, do đó gây ra độ trễ khi ghi bổ sung ngay cả khi sử dụng MoR.
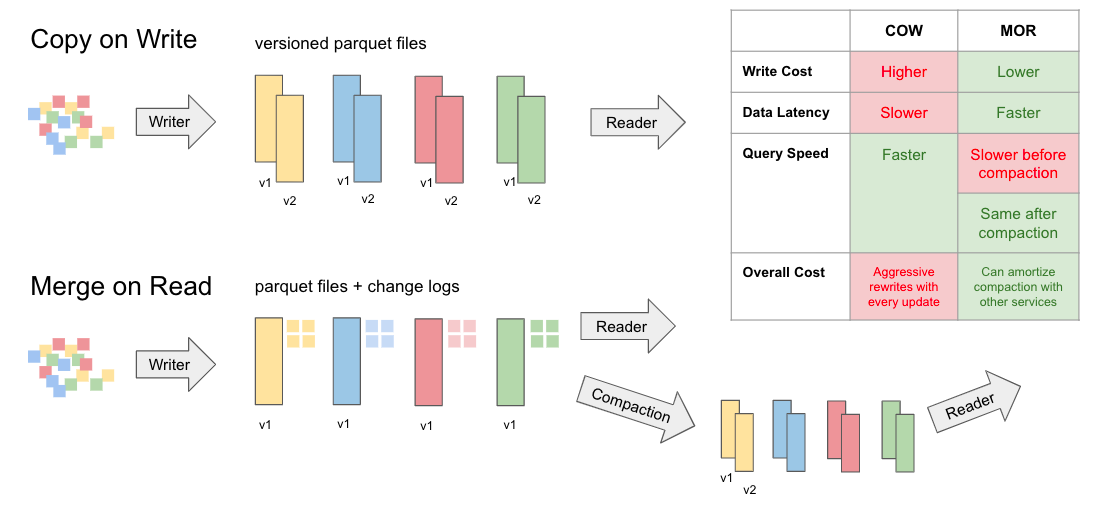
CoW MoR. Nguồn: onehouse.ai
Do đó, đối với khối lượng công việc streaming cần gần như là thời gian thực, Hudi có thể sử dụng các định dạng theo hàng hiệu quả hơn, trong khi đối với khối lượng công việc batch, Hudi sử dụng định dạng theo cột có thể vector hóa, và có thể hợp nhất liền mạch giữa hai định dạng này khi cần. Nhiều người dùng chuyển sang Apache Hudi vì đây là giải pháp duy nhất có khả năng này, cho phép đạt được hiệu suất ghi tốt và độ trễ đường dữ liệu thấp.
Phân vùng dữ liệu (Partitioning)
Một tính năng thường được nhấn mạnh trong dự án data lakehouse Apache Iceberg là phân vùng ẩn (hidden partitioning). Ý tưởng cơ bản là khi dữ liệu bắt đầu quá lớn hoặc khi không đạt được hiệu suất cần thiết từ cách phân vùng hiện tại, thì nó cho phép ta cập nhật phân vùng cho dữ liệu mới mà không cần ghi lại dữ liệu của mình. Iceberg xử lý công việc phân vùng dữ liệu cho các hàng trong bảng, tránh những sai sót và tính toán thủ công. Iceberg tự động loại bỏ các phân vùng không cần thiết khi đọc dữ liệu. Người dùng không cần biết cách phân vùng bảng và thêm các bộ lọc bổ sung vào truy vấn của họ. Bố cục phân vùng của Iceberg có thể thay đổi theo nhu cầu.
Khi đó dữ liệu cũ sẽ được giữ lại trong lược đồ phân vùng cũ và chỉ dữ liệu mới được phân vùng theo cách phân vùng mới. Tuy nhiên, một bảng được phân vùng theo nhiều cách sẽ đẩy độ phức tạp sang cho người dùng và không thể đảm bảo hiệu suất nhất quán nếu người dùng không biết hoặc đơn giản là không tính đến.
Apache Hudi áp dụng một cách tiếp cận khác để giải quyết vấn đề phân vùng dữ liệu với phương pháp clustering (chia cụm). Ta có thể chọn chiến lược phân vùng chi tiết (coarse-grained partition) hoặc thậm chí để dữ liệu không được phân vùng và sử dụng fine-grained clustering mà không cần phân vùng dữ liệu. Với Apache Hudi, cụm có thể được chạy đồng bộ hoặc không đồng bộ và có thể phát triển mà không cần ghi lại bất kỳ dữ liệu nào. Cách tiếp cận này tương đương với chiến lược phân vùng vi mô (micro-partitioning) và cụm được sử dụng bởi Snowflake.
Lập chỉ mục (Indexing)
Lập chỉ mục (Indexing) là một nhu cầu thiết yếu cho cơ sở dữ liệu và data warehouse, nhưng lại thiếu trong các data lake. Trong các phiên bản phát hành gần đây, Apache Hudi đã tạo ra một hệ thống phụ lập chỉ mục hiệu suất cao đầu tiên thuộc loại này cho data lakehouse, được gọi là Hudi multi-modal index. Apache Hudi cung cấp cơ chế lập chỉ mục không đồng bộ cho phép xây dựng và thay đổi chỉ mục mà không ảnh hưởng đến độ trễ khi ghi. Cơ chế lập chỉ mục này có thể mở rộng và linh hoạt để hỗ trợ bất kỳ kỹ thuật lập chỉ mục phổ biến nào, chẳng hạn như Bloom, bảng băm, bitmap, R-tree, v.v. Các chỉ mục này được lưu trữ trong bảng metadata Hudi, được lưu trữ bên cạnh dữ liệu. Metadata được ghi ở các định dạng tệp được lập chỉ mục và tối ưu hóa, giúp cải thiện hiệu suất tìm kiếm theo điểm dữ liệu tăng từ 10 đến 100 lần so với các định dạng tệp chung của Delta hoặc Iceberg. Kết quả từ các thử nghiệm cho thấy hệ thống lập chỉ mục mới này mang lại hiệu suất truy vấn tổng thể nhanh hơn từ 10 đến 30 lần.
Databricks và Iceberg hỗ trợ có dạng lập chỉ mục cụm Z-order (Z-order clustered indexing) và chỉ mục Bloom filter. Định dạng file Delta sử dụng là Parquet, đây là định dạng tệp nén theo cột do đó nó đã rất hiệu quả trong việc chỉ lấy các cột cần thiết và sử dụng lập chỉ mục Z-order có khả năng sàng lọc qua dữ liệu petabyte chỉ trong vài giây. Cả lập chỉ mục Z-order và Bloom filter đều làm giảm đáng kể lượng dữ liệu cần quét để trả lời các truy vấn có tính chọn lọc cao đối với các bảng Delta lớn, giúp cải thiện thời gian chạy và tiết kiệm chi phí. Ta nên sử dụng Z-order trên Khóa chính và khóa ngoại thường dùng và sử dụng thêm chỉ mục Bloom filter nếu cần.
Thay đổi schema
Schema evolution (thay đổi lược đồ) là việc thay đổi cấu trúc cơ sở dữ liệu mà vẫn giữ nguyên dữ liệu hiện có và chức năng hệ thống phần mềm. Nói một cách đơn giản, nó là quá trình thay đổi cấu trúc của một cơ sở dữ liệu mà không làm mất dữ liệu hoặc phá vỡ ứng dụng đang sử dụng nó. Schema evolution rất quan trọng vì các ứng dụng phần mềm thường xuyên thay đổi theo thời gian. Khi nhu cầu của người dùng thay đổi, các nhà phát triển cần phải thêm các tính năng mới, sửa lỗi và điều chỉnh cấu trúc dữ liệu để đáp ứng những nhu cầu đó. Nếu không có schema evolution, việc thay đổi cấu trúc cơ sở dữ liệu có thể dẫn đến mất dữ liệu, lỗi ứng dụng và các vấn đề khác.
Iceberg hỗ trợ việc thay đổi cấu trúc bảng (table evolution) ngay trên bảng đang có (in-place). Bạn có thể thay đổi cấu trúc bảng giống như thao tác trên bảng SQL - ngay cả với các cấu trúc lồng nhau (nested structures) - hoặc thay đổi cách phân vùng (partition layout) khi dung lượng dữ liệu thay đổi. Việc thay đổi schema với Iceberg không cần các thao tác tốn tài nguyên như ghi lại lại dữ liệu bảng (rewriting table data) hoặc di chuyển sang một bảng mới (migrating to a new table).
Với Delta Lake, lập trình viên có thể dễ dàng thay đổi schema để thêm các cột mới bị từ chối trước đó do không khớp schema bằng cách thêm .option('mergeSchema', 'true') vào lệnh Spark .write hoặc .writeStream. Ngoài ra, ta có thể đặt tùy chọn này cho toàn bộ phiên Spark bằng cách thêm spark.databricks.delta.schema.autoMerge = True vào cấu hình Spark. Bằng cách thêm tuỳ chọn mergeSchema trong truy vấn, bất kỳ cột nào có trong DataFrame nhưng không có trong bảng sẽ tự động được thêm vào cuối schema như một phần của việc ghi. Các trường lồng nhau cũng có thể được thêm vào và các trường này sẽ được thêm vào cuối các cột struct tương ứng.
Người làm kỹ sư dữ liệu và khoa học dữ liệu có thể sử dụng tùy chọn này để thêm các cột mới (đó có thể là một số liệu theo dõi mới hoặc một cột chứa số liệu bán hàng của tháng này) vào các bảng mà không làm hỏng các mô hình hiện có dựa trên các cột cũ. Ta cũng có thể yêu cầu schema và dữ liệu được ghi đè bằng cách thêm .option("overwriteSchema", "true"). Ví dụ: trong trường hợp cột "Foo" ban đầu là kiểu dữ liệu số nguyên và schema mới sẽ là kiểu dữ liệu chuỗi, thì tất cả các tệp Parquet (dữ liệu) sẽ cần được ghi lại.
Với bản phát hành Spark 3.0 sắp tới, đặc tả DDL (sử dụng ALTER TABLE) sẽ được hỗ trợ đầy đủ, cho phép người dùng thực hiện các hành động sau trên lược đồ bảng:
- Thêm cột
- Thay đổi chú thích cột
- Thiết lập các thuộc tính bảng xác định hành vi của bảng, chẳng hạn như đặt thời gian lưu giữ nhật ký giao dịch (retention log).
Với Hudi thì vấn đề hơi phức tạp một chút. Với tình huống có schema evolution khi ghi dữ liệu, Hudi hỗ trợ schema tương thích ngược ngay lập tức, chẳng hạn như thêm một trường cho phép null hoặc nâng cấp kiểu dữ liệu của một trường. Hơn nữa, schema đã phát triển có thể truy vấn được trên các công cụ hiệu suất cao như Presto và Spark SQL mà không cần thêm chi phí cho việc dịch ID cột hoặc điều hòa kiểu dữ liệu. Bảng sau tóm tắt các thay đổi schema tương thích với các kiểu bảng Hudi khác nhau. Schema đầu vào sẽ tự động được thêm các cột thiếu với giá trị null từ schema bảng. Đối với việc này, chúng ta cần kích hoạt cấu hình hoodie.write.set.null.for.missing.columns nếu không quy trình sẽ bị lỗi.
Thông thường có những tình huống mong muốn có khả năng phát triển schema linh hoạt hơn. Ví dụ:
- Có thể thêm, xóa, sửa đổi và di chuyển các cột (bao gồm các cột lồng nhau).
- Đổi tên các cột (bao gồm các cột lồng nhau).
- Thêm, xóa hoặc thực hiện các phép toán trên các cột lồng nhau thuộc kiểu Mảng.
Hudi hỗ trợ thử nghiệm cho phép các tình huống phát triển schema không tương thích ngược khi ghi dữ liệu đồng thời giải quyết chúng trong quá trình đọc. Để bật tính năng này, cần đặt hoodie.schema.on.read.enable=true trên cấu hình writer (Datasource) hoặc thuộc tính bảng (SQL).
Tốc độ
Có nhiều bài kiểm tra tốc độ ba hệ thống lưu trữ lakehouse, tập trung vào ba lĩnh vực chính: hiệu suất đầu cuối, hiệu suất ingest dữ liệu và hiệu suất truy cập siêu dữ liệu khác nhau trong quá trình truy vấn. Bạn có thể tham khảo tại đây. https://github.com/lhbench/lhbench.
Về thời gian tải (bulk load), Delta Lake và Iceberg mất khoảng thời gian tương đương nhau, nhưng Hudi chậm hơn gần 10 lần. Điều này là do Hudi được tối ưu hóa cho các cập nhật theo khóa (upsert), không phải cho việc nhập dữ liệu hàng loạt, và thực hiện các tiền xử lý tốn kém trong quá trình tải dữ liệu, bao gồm kiểm tra tính duy nhất của khóa và phân phối lại khóa.
Về tốc độ truy vấn tổng thể, Delta Lake chạy nhanh hơn 1,4 lần so với Hudi và nhanh hơn 1,7 lần so với Iceberg. Hiệu suất khác biệt giữa ba hệ thống lưu trữ lakehouse chủ yếu bởi thời gian đọc dữ liệu, điều này không có gì ngạc nhiên vì engine và query plan đều giống nhau. Delta Lake vượt trội so với Hudi vì Hudi có kích cỡ file nhỏ hơn. Ví dụ, một phân vùng dữ liệu được lưu trữ trong một file 128 MB trong Delta Lake nhưng lại dàn trải thành 22 file 8,3 MB trong Hudi. Điều này làm giảm hiệu quả của nén cột và tăng chi phí xử lý cho việc quét bảng lớn.
Khi so sánh Delta Lake và Iceberg, chúng ta thấy rằng cả hai đều đọc cùng một lượng byte, nhưng Iceberg sử dụng trình đọc Parquet tùy chỉnh được xây dựng trong Spark, chậm hơn đáng kể so với trình đọc Spark mặc định được sử dụng bởi Delta Lake và Hudi. Iceberg hỗ trợ xóa và đổi tên các cột trong bảng yêu cầu các chức năng tùy chỉnh không có sẵn trong trình đọc Parquet tích hợp của Apache Spark.
Kết quả của một bài kiểm tra cũng cho thấy rằng việc hợp nhất trong Hudi MoR nhanh hơn 1,3 lần so với Hudi CoW nhưng đổi lại tốc độ truy vấn sau khi hợp nhất chậm hơn 3,2 lần. Đề bài là ghi bộ dữ liệu gốc TPC-DS 100 GB, chạy 5 truy vấn mẫu (Q3, Q9, Q34, Q42 và Q59), chạy tổng cộng 10 lần làm mới (mỗi lần cho 3% của bộ dữ liệu gốc) bằng cách sử dụng hoạt động MERGE INTO để cập nhật. Sau đó, chạy lại 5 truy vấn mẫu trên các bảng đã cập nhật. Cả Hudi CoW và MoR đều có hiệu suất ghi kém trong lần tải ban đầu do cần thêm tiền xử lý để phân phối dữ liệu theo khóa và cân bằng lại kích thước tệp ghi.
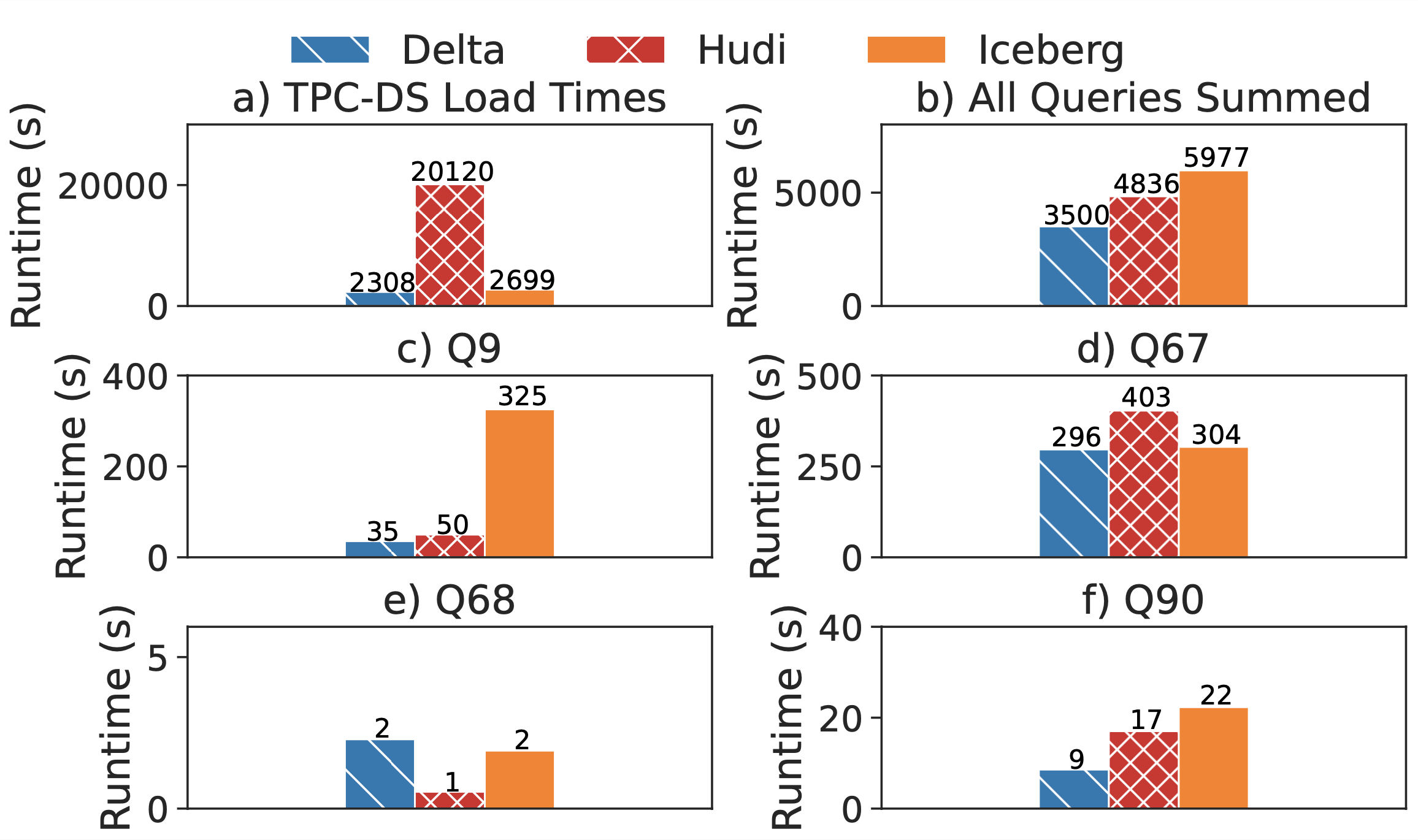
So sánh tốc độ ghi toàn bộ và query dữ liệu
Hiệu suất của Delta Lake trong việc ghi lượng lớn dữ liệu và đọc đều rất tốt, mặc dù chỉ sử dụng CoW, do kết hợp tạo ra ít file hơn, quét nhanh hơn và lệnh MERGE được tối ưu hóa hơn. Các lần hợp nhất trong Iceberg phiên bản 0.14.0 với MoR nhanh hơn 1,4 lần so với CoW. Hiệu suất truy vấn sau khi hợp nhất vẫn tương tự nhau giữa các chế độ bảng.
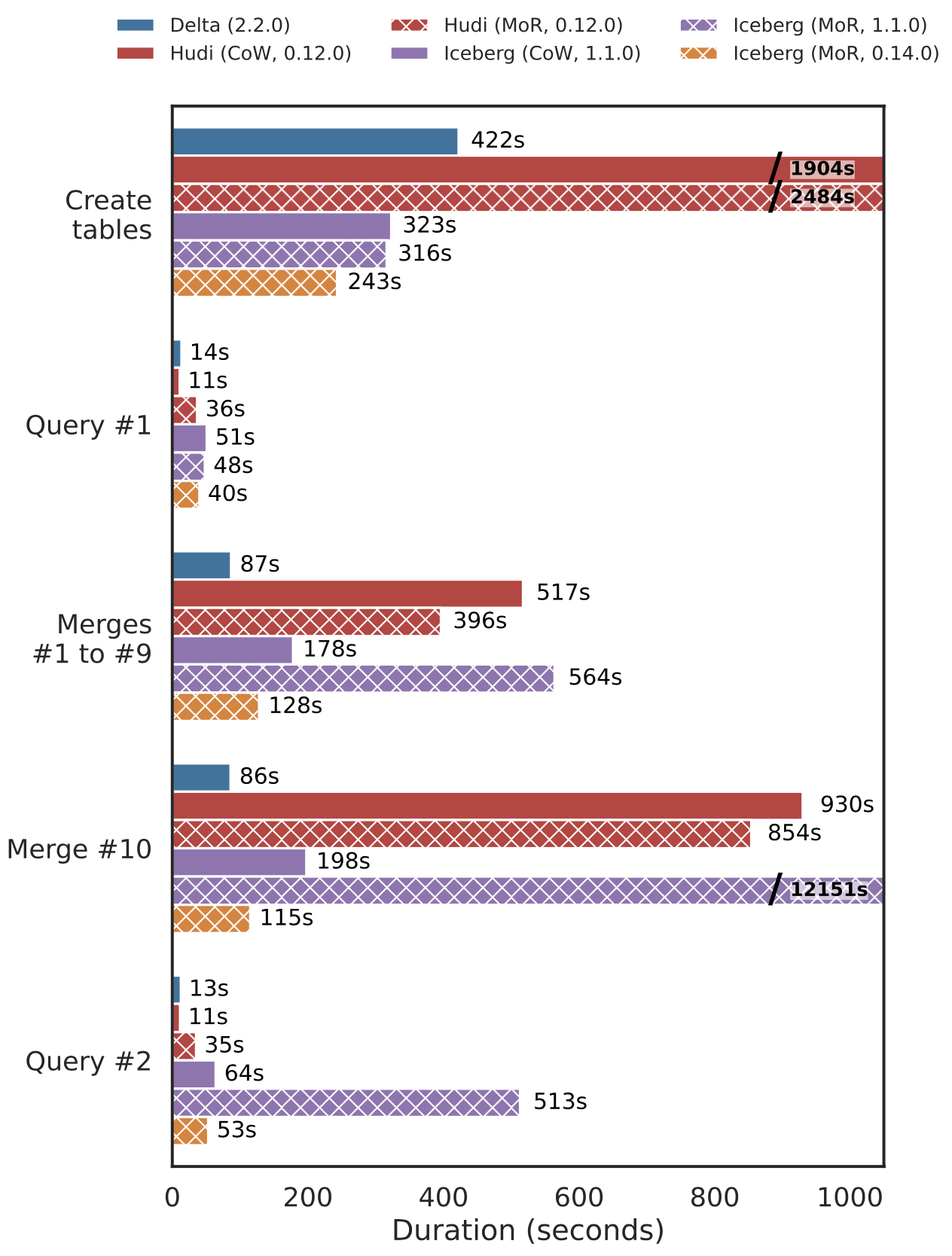
So sánh hiệu suất ghi tăng dần và query liên tục
Lời kết
Thiết kế của các hệ thống lakehouse liên quan đến những đánh đổi quan trọng xung quanh việc điều phối transaction, lưu trữ metadata ảnh hưởng đáng kể đến hiệu suất.
Apache Hudi có lợi thế về kỹ thuật khi ta có nhu cầu công việc đa dạng, vượt ra ngoài việc chỉ chèn thêm dữ liệu. Khi bắt đầu phải xử lý nhiều bản cập nhật hoặc cố gắng giảm độ trễ đầu cuối của pipeline của mình, Apache Hudi là lựa chọn hàng đầu về hiệu suất và tính năng, khả năng linh động cực cao.
Delta Lake nhìn chung lại rất cân bằng giữa hiệu suất và tính năng, đồng thời lại có hệ sinh thái rất tốt và được các nhà cung cấp dịch vụ cloud hỗ trợ, vì thế nó trở nên cực kỳ phổ biến và có lượng khách hàng lớn. Điểm mà nhiều người không thích Delta Lake đó là mã nguồn mở, Delta Lake được Databricks phát triển chính và Delta Engine lại có bản quyền.
Iceberg, ngược lại, hoàn toàn độc lập về mặt quản trị và không bị ràng buộc với bất kỳ công cụ hoặc nền tảng cụ thể nào. Tất cả các ứng dụng đều có quyền truy cập và xử lý bình đẳng, không phụ thuộc hoặc bị ràng buộc vào bất kỳ công cụ cụ thể nào, cho phép linh hoạt để tùy chỉnh data lake theo nhu cầu. Hoàn toàn không phụ thuộc vào hệ thống lưu trữ, không phụ thuộc vào hệ thống file, cho phép linh hoạt khi lựa chọn hệ thống lưu trữ. 100% mã nguồn mở và được quản trị độc lập.
Vì thế, khi lựa chọn, ta cần cân nhắc cẩn thận nhu cầu để có thể đưa ra giải pháp phù hợp nhất.
Tham khảo
Analyzing and Comparing Lakehouse Storage Systems
Hudi, Iceberg and Delta Lake: Data Lake Table Formats Compared
Open Table Formats for Efficient Data Processing: Delta Lake vs Iceberg vs Hudi
Apache Hudi vs Delta Lake vs Apache Iceberg - Data Lakehouse Feature Comparison

