- Microsoft Fabric là gì?
- Các định giá
- Trải nghiệm Lakehouse với Microsoft Fabric
- Tích hợp dữ liệu bằng Data Factory với Dataflows trong Microsoft Fabric
- Sử dụng Apache Spark trong Microsoft Fabric
- Thiết kế và xây dựng kho dữ liệu với Microsoft Fabric
- Xử lý dữ liệu thời gian thực với Microsoft Fabric
- Kết luận
Trải nghiệm Microsoft Fabric với bản dùng thử
Microsoft Fabric là một giải pháp phân tích hoàn chỉnh vừa được ra mắt gần đây. Bài viết sau đây sẽ khai thác những trải nghiệm ban đầu khi sử dụng bản dùng thử của dịch vụ này cùng một vài nhận định về lý do khiến nó gây sốt cộng đồng công nghệ trong thời gian qua.
This post is also available in English
.jpg)
Microsoft Fabric là gì?
Microsoft Fabric (gọi tắt là Fabric hay MF) là một giải pháp phân tích hoàn chỉnh với đầy đủ dịch vụ bao gồm di chuyển dữ liệu, data lake, xử lý dữ liệu, tích hợp dữ liệu, khoa học dữ liệu, phân tích thời gian thực và trí tuệ doanh nghiệp (business intelligence), tất cả đều được hỗ trợ bởi một nền tảng dùng chung được bảo mật mạnh mẽ, kiểm soát và tuân thủ tiêu chuẩn. Fabric tích hợp các công nghệ như Azure Data Factory, Azure Synapse Analytics và Power BI vào một sản phẩm duy nhất. Dịch vụ này cung cấp tất cả các công cụ cần thiết cho lập trình viên để trích xuất thông tin chuyên sâu từ dữ liệu và trình bày dữ liệu đó cho người dùng.
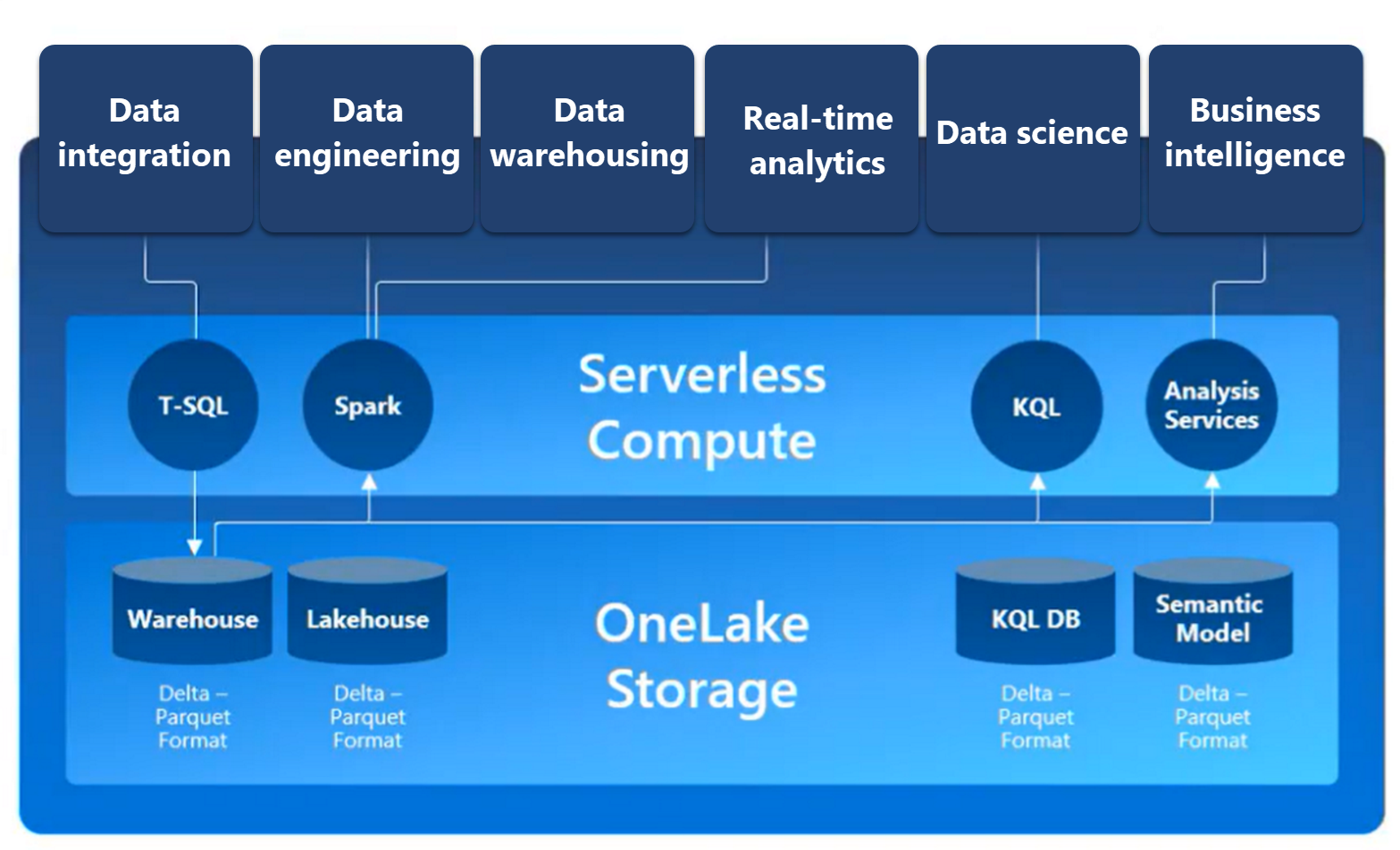
Fabric cung cấp giải pháp phân tích dữ liệu toàn diện bằng cách hợp nhất tất cả những dịch vụ sau đây trên một nền tảng duy nhất.
- Synapse Data Engineering: Sử dụng Spark dùng để chuyển đổi dữ liệu ở quy mô lớn.
- Synapse Data Warehouse: Kho dữ liệu SQL mạnh mẽ và khả năng mở rộng cao.
- Synapse Data Science: Hỗ trợ Azure Machine Learning và Spark để đào tạo và triển khai model AI.
- Synapse Real-Time Analytics: Hỗ trợ phân tích thời gian thực để truy vấn và phân tích khối lượng lớn dữ liệu trong thời gian thực.
- Data Factory: Sử dụng Azure Data Factory kết hợp Power Query để di chuyển và chuyển đổi dữ liệu.
- Power BI: Cung cấp một bộ công cụ để trực quan hóa dữ liệu và tạo báo cáo với Power BI ngay trong Fabric.
Các định giá
Microsoft Fabric là một dịch vụ trong phân khúc Office 365, không phải là dịch vụ trong Azure. Nói sơ lược, Office 365 cung cấp các dịch vụ Office, bao gồm các dịch vụ như Word, Excel, Powerpoint, v.v. còn Azure Cloud cung cấp cơ sở hạ tầng, công cụ và dịch vụ để nhà phát triển tạo và quản lý ứng dụng, dùng bao nhiêu thanh toán bấy nhiêu.
Microsoft Fabric hoạt động trên hai loại SKU, mỗi SKU phục vụ một nhu cầu tính toán khác nhau, được đo bằng khả năng tính toán (Capacity Unit - CU) của nó.
- SKU Microsoft 365: phải là gói đăng ký có PowerBI, vì Microsoft Fabric được kích hoạt trên gói đăng ký Power BI.
- Azure SKU: Microsoft Fabric phải được liên kết với Azure để tùy chỉnh các thông số như loại tính toán, dung lượng, v.v. Để biết thêm thông tin, bạn có thể tham khảo tại đây.
Trải nghiệm Lakehouse với Microsoft Fabric
OneLake cho phép kết hợp dữ liệu được lưu trữ trên các vùng và đám mây khác nhau thành một vùng dữ liệu duy nhất mà không cần di chuyển hoặc sao chép dữ liệu. Tương tự như cách các ứng dụng Office được kết nối sẵn để sử dụng OneDrive, tất cả các xử lý trong Fabric đều được cấu hình sẵn để hoạt động với OneLake. Kho dữ liệu, xử lý dữ liệu (Lakehouses và Notebooks), tích hợp dữ liệu (pipeline và data flows), phân tích thời gian thực và Power BI của Fabric đều sử dụng OneLake làm nguồn dữ liệu gốc mà không cần bất kỳ cấu hình bổ sung nào.
OneLake được xây dựng dựa trên Azure Data Lake Storage (ADLS) và hỗ trợ dữ liệu ở nhiều định dạng, bao gồm Delta Parquet, CSV, JSON, Excel, v.v.
OneLake của Fabric được quản lý tập trung và có thể dễ dàng cộng tác. Dữ liệu được bảo mật và quản lý tập trung, trong khi người dùng dữ liệu vẫn có thể dễ dàng truy cập. Việc quản lý Fabric được tập trung tại Admin Center.
Nền tảng của Microsoft Fabric là Lakehouse. Lakehouse được xây dựng trên lớp lưu trữ có thể mở rộng là OneLake, đồng thời sử dụng Apache Spark và SQL để xử lý dữ liệu lớn. Lakehouse là một nền tảng thống nhất kết hợp giữa:
- Khả năng lưu trữ linh hoạt và có thể mở rộng của data lake
- Khả năng truy vấn và phân tích dữ liệu của data warehouse
Trong Microsoft Fabric, Lakehouse cung cấp hệ thống lưu trữ có khả năng mở rộng cao với OneLake (được xây dựng trên Azure Data Lake Store Gen2) với metastore cho các đối tượng quan hệ như bảng và views dựa trên định dạng Delta Lake. Ta có thể định nghĩa một lược đồ (schema) trong Delta Lake và cho phép mọi người truy vấn bằng SQL.
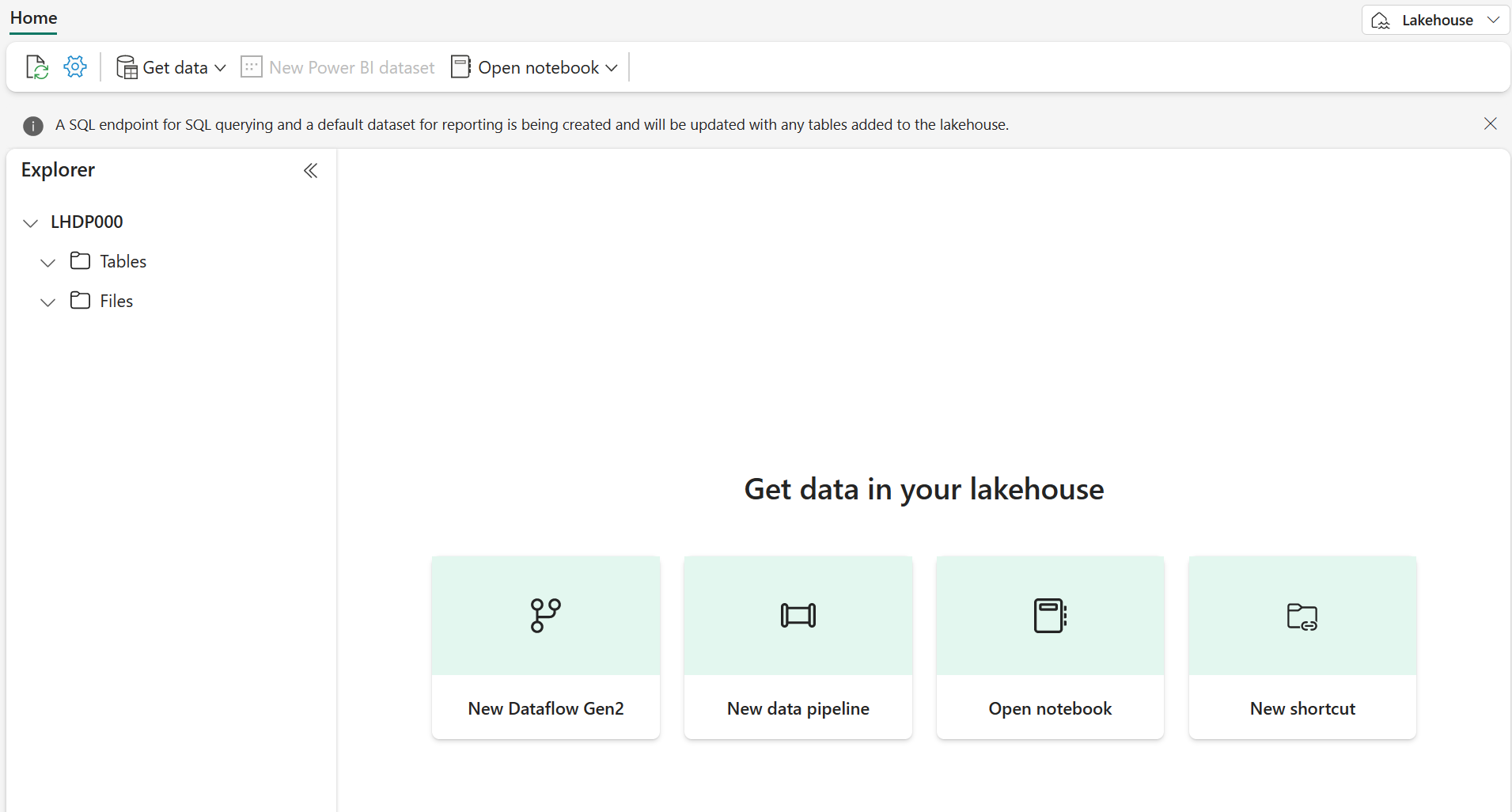
Các bảng trong Microsoft Fabric Lakehouse được dựa trên định dạng lưu trữ Delta Lake. Delta Lake là lớp lưu trữ (storage layer) mã nguồn mở dành cho Spark, cho phép lưu trữ luồng (stream) và lô (batch) dữ liệu thành dạng dữ liệu quan hệ. Bằng cách sử dụng Delta Lake, ta có thể triển khai kiến trúc lakehouse để hỗ trợ thao tác dữ liệu với SQL trong Spark và hỗ trợ transaction cũng như quản lý theo schema. Kết quả ta có được một kho lưu trữ dữ liệu cho mục đích phân tích sở hữu nhiều ưu điểm của hệ thống cơ sở dữ liệu quan hệ kết hợp với tính linh hoạt của việc lưu trữ dạng file.
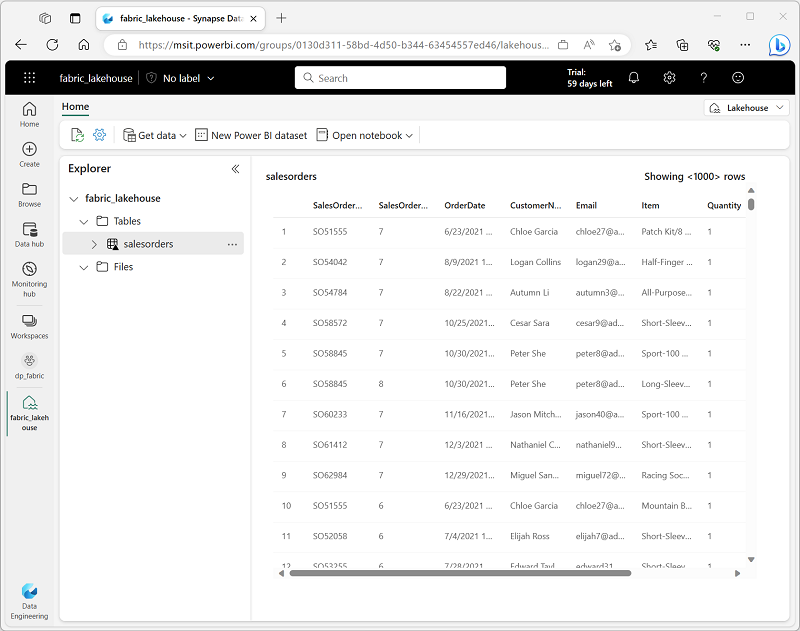
Tích hợp dữ liệu bằng Data Factory với Dataflows trong Microsoft Fabric
Data Factory được tích hợp sẵn trong Microsoft Fabric, mang đến khả năng tạo pipeline trong đó bao gồm cả việc tích hợp và chuyển đổi (transform). Data Factory cung cấp Dataflows (Gen2) để tích hợp dữ liệu nhiều bước và chuyển đổi dữ liệu bằng Power Query Online.
Trải nghiệm Data Factory trên Microsoft Fabric cũng phần nào tương tự như trên Azure Data Factory (ADF). Người dùng đã từng sử dụng Azure Data Factory thì sẽ nhanh chóng làm quen với những việc như tạo linked services, activities, trigger và monitors.
Tuy nhiên, Data Factory trên Microsoft Fabric do mới được phát triển gần đây nên cũng có những điểm khác biệt nhất định so với trên Azure Data Factory như sau:
- Chưa tích hợp với git, người dùng phải tự quản lý phiên bản source code. Do đó, tôi nghĩ nó chỉ phù hợp với những dự án cá nhân hoặc với team rất nhỏ.
- Về phần quản lý resource trong workspace: Tất cả các resource (pipeline, dataflow, dataset, v.v) đều để chung trong một folder là workspace, sẽ rất khó quản lý resource khi dự án lớn dần.
- Về việc chuyển đổi dữ liệu, Azure Data Factory hỗ trợ các luồng ánh xạ dữ liệu được tích hợp sẵn (built-in native mapping data flows) và sắp xếp dữ liệu với Power Query (Data Wrangling with Power Query). Ngoài ra, Azure Data Factory còn hỗ trợ các chuyển đổi thủ công như HDInsight Hive, Spark, Store Procedures, Spark Notebook, v.v. Còn Data Factory trong Microsoft Fabric chỉ hỗ trợ duy nhất 1 công cụ đó là Power Query.
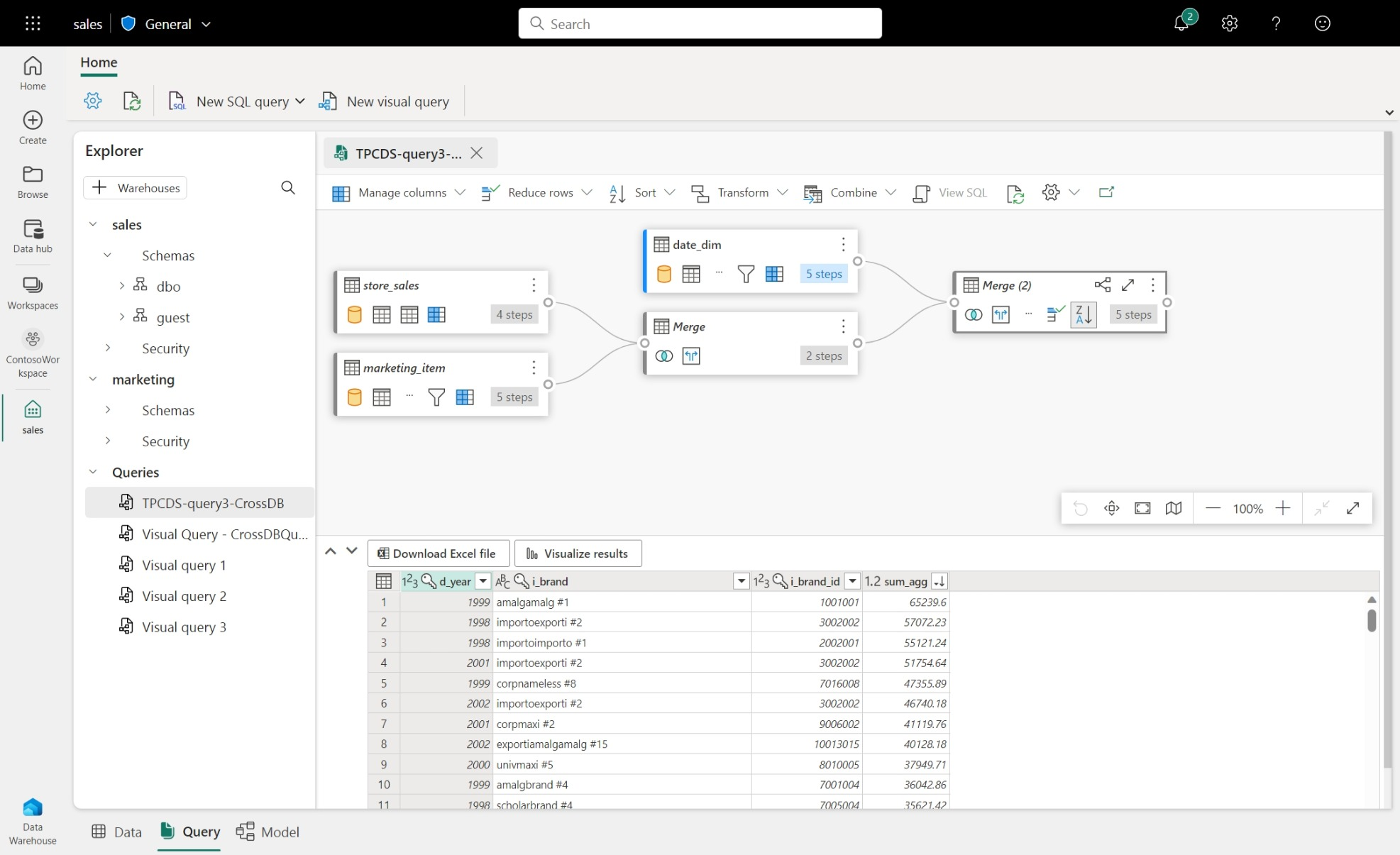
- Chưa hỗ trợ nhiều connector để tích hợp với các hệ thống khác. Đặc biệt là sink connector hiện nay chỉ hỗ trợ vào OneLake và 1 số dịch vụ của Azure.

Một điểm mình rất thích ở đây là Pipeline được khởi động rất nhanh, hầu như không tốn thời gian để khởi động Integration Runtimes (bên Azure Data Factory mất khoảng hơn 1 phút để làm việc này).
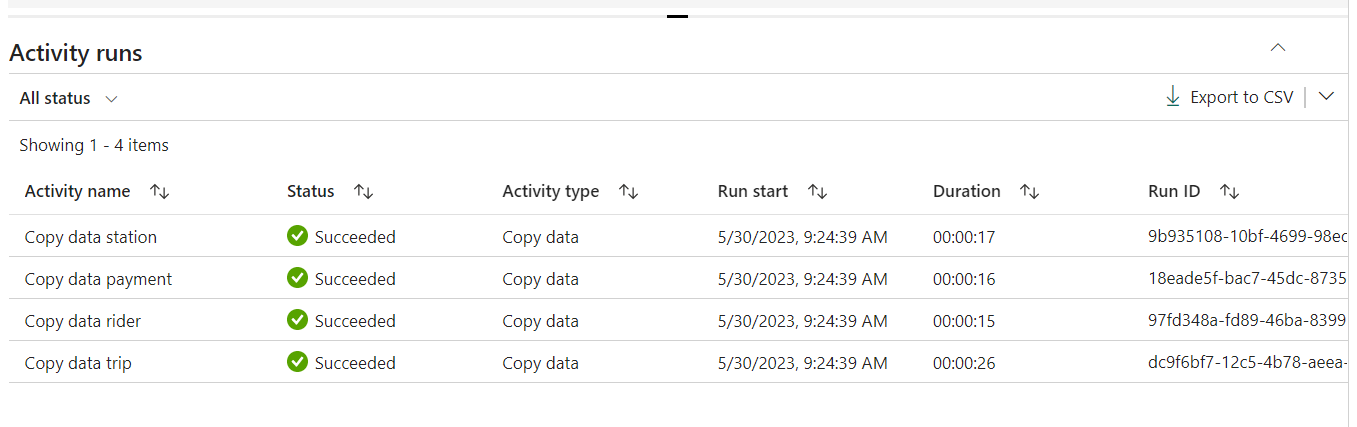
Sử dụng Apache Spark trong Microsoft Fabric
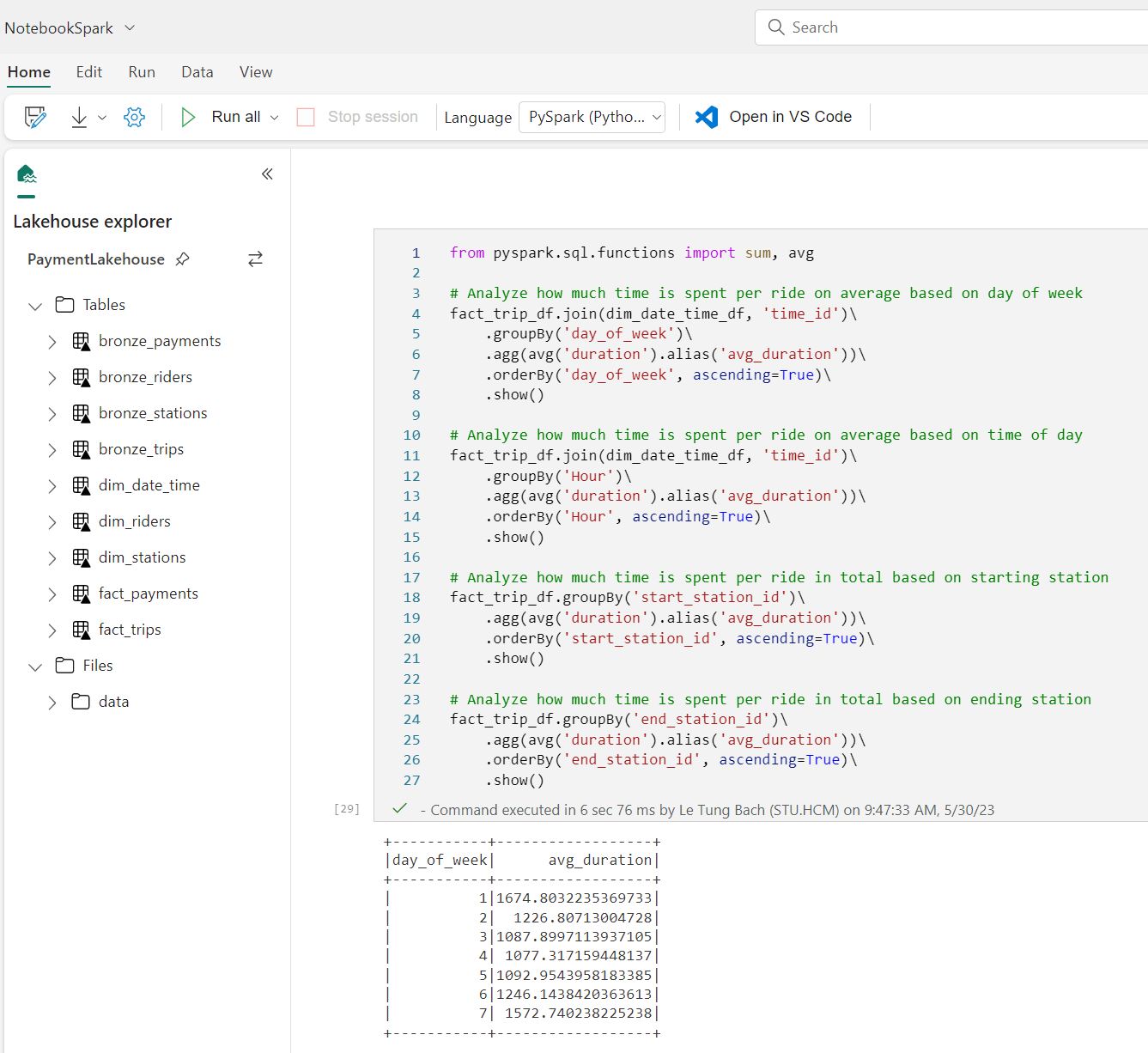
Apache Spark là công nghệ cốt lõi của việc phân tích và xử lý dữ liệu lớn. Microsoft Fabric Hỗ trợ Spark cluster cho phép các Data Engineer phân tích và xử lý dữ liệu trong Lakehouse ở quy mô lớn.
Trải nghiệm sử dụng Spark Notebook trên Microsoft Fabric hầu như tương tự với Azure Synapse. Các tính năng cơ bản như tương tác với Lakehouse, nhắc lệnh, code mẫu (sniplet) vẫn được giữ nguyên.
Để chạy Notebook trên Microsoft Fabric, việc duy nhất cần làm là bấm nút run, và thế là code chạy, ko cần provision, chỉ việc viết code. Nếu như bên Synapse thì cluster cần thời gian khá lâu để khởi động thì bên Microsoft Fabric chỉ tốn khoảng vài giây (Trường hợp của mình đã khởi động trong khoảng 9s, một con số thực sự ấn tượng nếu so với khoảng 2-3 phút bên Azure Synapse).
Khái niệm infra hay cluster hầu như được ẩn với người dùng, chúng ta chỉ cần tập trung vào code. Tôi rất thích điểm này.
Thiết kế và xây dựng kho dữ liệu với Microsoft Fabric
Fabric hỗ trợ 2 phương pháp xây dựng kho dữ liệu: SQL Endpoint của Lakehouse và Data Warehouse. Thông qua SQL Endpoint của Lakehouse, người dùng có thể dùng SQL để định nghĩa và truy vấn dữ liệu, tuy nhiên ta không thể dùng để thao tác dữ liệu. Data Warehouse hỗ trợ các truy vấn giao dịch, DDL và DML.
Data Warehouse cung cấp các công cụ tích hợp dữ liệu cho phép người dùng nhập dữ liệu một cách linh hoạt bằng công cụ giao diện hoặc viết code. Người dùng có thể xây dựng pipeline, data flows, dùng lệnh truy vấn cơ sở dữ liệu liên kết hoặc đơn giản là dùng lệnh copy. Fabric giúp mọi việc trở nên dễ dàng hơn bằng cách cho phép người dùng phân tích dữ liệu trong bất kỳ lakehouse, sử dụng Synapse Spark, Azure Databricks hoặc bất kỳ công cụ xử lý dữ liệu nào. Dữ liệu có thể được lưu trữ trong Azure Data Lake Storage hoặc Amazon S3.
Chúng ta cũng có thể tạo shortcut đến dữ liệu mà không cần phải sao chép dữ liệu đó và thực hiện trực tiếp các phân tích trên dữ liệu được chia sẻ. Sau khi kết nối với dữ liệu được chia sẻ, ta có thể truy vấn dữ liệu bằng T-SQL, hoặc có thể join dữ liệu từ các bảng được liên kết với các bảng hiện có trong data warehouse.
Ta có thể truy vấn dữ liệu bằng nhiều công cụ, bao gồm Visual Query Editor và SQL Query Editor có sẵn trong Microsoft Fabric. Theo trải nghiệm của tôi,Visual Query Editor vẫn đang ở giai đoạn đầu và chưa đủ tốt để có thể sử dụng làm công cụ truy vấn chính.
Xử lý dữ liệu thời gian thực với Microsoft Fabric
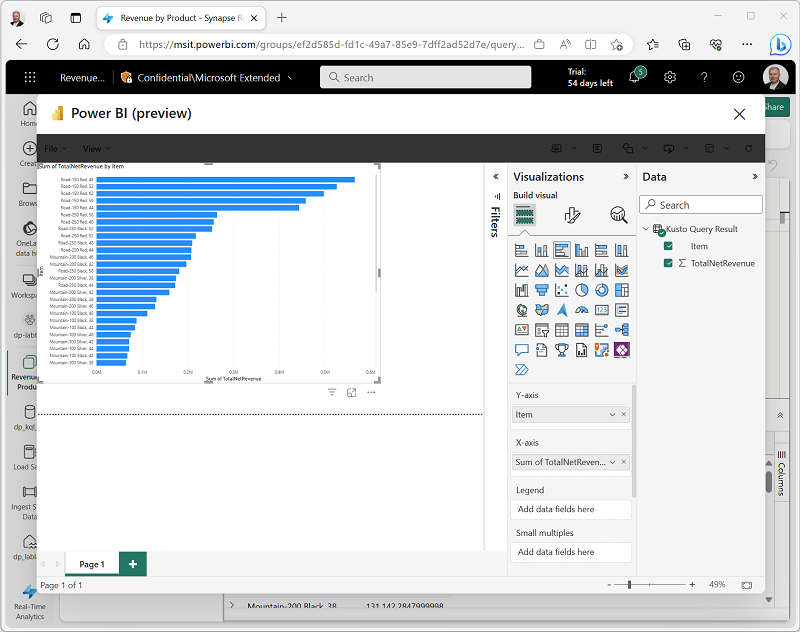
Phân tích các luồng dữ liệu thời gian thực là một tính năng quan trọng đối với bất kỳ giải pháp phân tích dữ liệu hiện đại nào. Với Fabric, ta có thể sử dụng các khả năng Phân tích theo thời gian thực để nhập, truy vấn và xử lý các luồng dữ liệu. Microsoft Fabric hỗ trợ KQL database (Kusto database) để lưu trữ dữ liệu thời gian thực, sau đó ta có thể sử dụng KQL Query để truy vấn, xem và thao tác kết quả truy vấn trên dữ liệu từ Data Explorer. Tính năng Eventstream cho phép ta tích hợp dữ liệu thời gian thực từ nhiều loại nguồn, bao gồm Event Hub và ứng dụng. Khi ta đã thiết lập dữ liệu nguồn, ta có thể lưu dữ liệu thời gian thực tới nhiều nơi như Lakehouse, KQL database hoặc ứng dụng.
Tạo bảng biểu (dashboard) với dữ liệu thời gian thực từ KQL database là rất dễ dàng, ta chỉ cần tạo KQL Query Set và chọn Build Power Bi Report, Fabric sẽ tự động tạo Power BI với Kusto Query Result là dữ liệu nguồn.
Kết luận
Dù Fabric vẫn đang còn trong giai đoạn dùng thử nhưng đây hứa hẹn sẽ là một công cụ mạnh mẽ giúp đơn giản hóa quá trình xây dựng giải pháp dữ liệu. Nó cho phép người dùng thiết kế, xây dựng và triển khai các data pipeline một cách dễ dàng và nhanh chóng. Với Fabric, ta cũng không phải lo lắng về việc quản lý infrastructure hay phải quan tâm việc kết hợp các dịch vụ khác nhau từ nhiều nhà cung cấp. Thay vào đó, ta có thể tập trung vào việc phân tích thông tin chuyên sâu từ dữ liệu của mình.
Chỉ cần vài giây đăng ký để sử dụng dịch vụ, người dùng sẽ có thể khai thác giá trị thực sự từ dữ liệu trong vòng vài phút. Fabric cũng cung cấp công cụ quản trị và quản lý tập trung, nhờ đó ta có thể dành nhiều thời gian hơn vào việc đảm bảo chất lượng dữ liệu, bảo mật và tuân thủ.
Tuy nhiên, bản thân tôi cũng có chút lo ngại về chi phí sử dụng Fabric. Các giải pháp SaaS có thể tốn kém về lâu dài, đặc biệt nếu người dùng có một lượng lớn dữ liệu hoặc nhu cầu phân tích phức tạp. Tôi không chắc Fabric sẽ tính phí như thế nào hay liệu nó có toàn năng hơn những dịch vụ tương tự khi đặt lên bàn cân so sánh hay không. Nhưng điều chắn chắn là cộng đồng công nghệ vẫn sẽ cần thêm thời gian để có thể hiểu rõ về chi phí sử dụng Fabric trước khi quyết định áp dụng.

