Data Best Practices (Phần 3): Kiểm tra và chuẩn hoá dữ liệu
Data Validation đóng vai trò quan trọng trong hệ thống xử lý dữ liệu. Trong bài viết này, chúng ta sẽ khám phá tầm quan trọng của việc kiểm tra chất lượng dữ liệu, các bước để thực hiện, các chỉ số được sử dụng để đánh giá, các best practice và các công cụ phổ biến giúp hiện thực hóa Data Validation.

Đọc thêm Series Data Best Practices:
Phần 1: Thiết kế kiến trúc và các công cụ
Phần 2: Xây dựng các luồng xử lý dữ liệu
Phần 3: Kiểm tra và chuẩn hóa dữ liệu
Phần Cuối: Điều phối và tự động hoá luồng dữ liệu
Bước 3: Kiểm tra và chuẩn hóa dữ liệu
1. Giới thiệu
Trong thời đại của dữ liệu lớn (big data) và xu hướng đưa ra quyết định dựa trên dữ liệu (data-driven decision-making), chất lượng dữ liệu (data quality) đóng vai trò trọng yếu. Data validation, một phần quan trọng của việc đảm bảo chất lượng dữ liệu, là quá trình đánh giá dữ liệu được thu thập, xử lý và phân tích dữ liệu để kiểm tra tính chính xác, đầy đủ, nhất quán. Việc đảm bảo dữ liệu đã đáp ứng tiêu chí và tuân thủ quy tắc giúp các hệ thống duy trì bộ dữ liệu chất lượng cao và đáng tin cậy cho các quá trình đưa ra quyết định. Triển khai quy trình kiểm tra chất lượng dữ liệu cũng giúp giảm chi phí liên quan đến các tình huống phát sinh do dữ liệu chất lượng kém, ước tính khoảng trên 3 nghìn tỷ USD mỗi năm chỉ riêng ở Hoa Kỳ.
2. Ứng dụng Data Validation vào giai đoạn nào ?
Data Validation có thể áp dụng vào nhiều giai đoạn trong data pipeline để đảm bảo chất lượng và độ chính xác trong suốt quy trình xử lý. Dưới đây là các bước quan trọng có thể áp dụng kiểm tra dữ liệu:
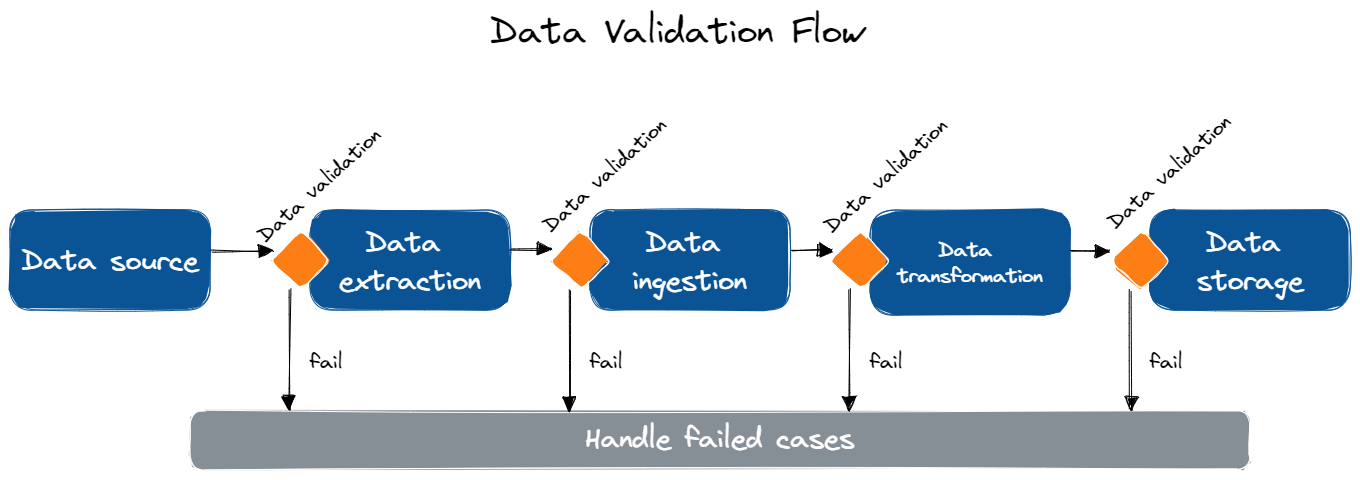
| Bước | Ứng dụng |
|---|---|
| Data Extraction (Xuất dữ liệu) | Kiểm tra dữ liệu tại nguồn dữ liệu trong quá trình xuất để đảm bảo dữ liệu hoàn chỉnh, chính xác, định dạng chuẩn. Điều này giúp phát hiện sớm các vấn đề trong data pipeline trước khi ảnh hưởng xấu đến giai đoạn tiếp theo. |
| Data Ingestion (Nhập dữ liệu) | Kiểm tra dữ liệu sau khi nhập vào hệ thống xử lý để phát hiện các vấn đề có thể xảy ra trong quá trình truyền tải, giúp đảm bảo dữ liệu đã nhập đáp ứng tiêu chuẩn chất lượng. |
| Data Transformation (Chuyển đổi dữ liệu) | Kiểm tra dữ liệu sau mỗi bước chuyển đổi để đảm bảo đã thực thi đúng và không gây lỗi hay thiếu nhất quán. Đặc biệt trong các pipeline mà dữ liệu cần làm sạch (clean), làm phong phú (enrich), xóa trùng lặp (deduplicate),... và các yếu tố khác có khả năng ảnh hưởng đến chất lượng dữ liệu. |
| Data Storage (Lưu trữ dữ liệu) | Kiểm tra dữ liệu sau khi đã lưu trữ để đảm bảo sự chính xác và tuân thủ các tiêu chuẩn đặt ra, có thể liên quan đến việc kiểm tra tính toàn vẹn dữ liệu, tính nhất quán và độ chính xác của dữ liệu trong kho lưu trữ. |
Áp dụng Data Validation trong các quá trình xử lý của data pipeline giúp xác định sớm vấn đề liên quan đến dữ liệu ở mỗi giai đoạn của quy trình, đảm bảo kết quả cuối cùng là đáng tin cậy và chính xác để sử dụng cho quá trình ra quyết định hay phân tích chuyên sâu.
3. Những chỉ số đo lường của Data Validation
Một số chỉ số đo lường phổ biến được sử dụng trong Data Validation để đánh giá chất lượng dữ liệu là:
- Completeness (tính đầy đủ)
- Tỷ lệ record có đầy đủ dữ liệu
- Tỷ lệ data field có đầy đủ dữ liệu
- Số lượng giá trị dữ liệu bị thiếu
- Số lượng giá trị dữ liệu bị thiếu trung bình trên mỗi record
- Uniqueness (tính duy nhất)
- Số lượng record trùng lặp
- Tỷ lệ record trùng lặp
- Số lượng record duy nhất
- Tỷ lệ record duy nhất
- Consistency (tính nhất quán)
- So sánh giá trị dữ liệu
- Nhất quán về loại dữ liệu
- Nhất quán về định dạng dữ liệu
- Nhất quán về phạm vi dữ liệu
- Timeliness (tính kịp thời)
- Data age (ví dụ: thời gian tồn tại trung bình của dữ liệu trong một tập dữ liệu)
- Data freshness (ví dụ: tỷ lệ dữ liệu có thời gian tạo dưới 24 giờ)
- Data lag (ví dụ: độ trễ trung bình cho một tập dữ liệu)
- Validity (tính hợp lệ)
- Tỷ lệ giá trị dữ liệu nằm trong khoảng dự kiến
- Tỷ lệ giá trị dữ liệu nhất quán với các giá trị dữ liệu khác
- Tỷ lệ giá trị dữ liệu chính xác
4. Best practices
Data Validation Strategy (Phương pháp xác thực dữ liệu):
- Xử lý "bad data" chính xác: Xác định phương pháp xử lý dữ liệu không đạt yêu cầu từ những giai đoạn đầu
- Định nghĩa các bài kiểm tra hồi quy của pipeline và theo dõi kết quả metrics
- Áp dụng cả unit test và integration test cho data pipeline
- Kiểm tra hạ tầng độc lập với data pipeline
- Tạo test case cho compliance
Test Automation and Monitoring (Kiểm thử Tự động hóa và Giám sát):
- Sử dụng các công cụ automated data profiler để tạo các test case thay vì tạo từ đầu
Ví dụ như Great Expectations cung cấp tính năng automated data profiling để thống kê và tự động tạo expectation dự trên kết quả phân tích dữ liệu. Những công cụ khác cung cấp tính năng này như: Talend, IBM InfoSphere Information Analyzer, RapidMiner...
- Kiểm tra dữ liệu ở mỗi giai đoạn trong pipeline và tự động hóa việc này
- Tạo cơ chế tự động hóa cập nhật test database để tránh việc trở nên lỗi thời
- Sử dụng các công cụ để giám sát data drift
Decoupling and Modularity (Tính tách rời và mô-đun):
- Tránh ràng buộc (tighly couple) giữa code kiểm tra dữ liệu và code kiểm tra data pipeline.
- Tạo phương thức cho phép kiểm tra dữ liệu trong các trường hợp cụ thể.
- Cài đặt schema test trong mỗi nguồn dữ liệu trước khi thực hiện nhập dữ liệu vào pipeline.
- Log kết quả failed để xác định dữ liệu "broken", "corrupted" hay cần điều chỉnh lại test.
Infrastructure and Resource Management (Quản lý hạ tầng và tài nguyên):
- Tránh thực thi các pipeline tốn nhiều tài nguyên trên dữ liệu kém chất lượng.
- Tích hợp các chỉ số đo lường của bước xác thực và đảm chất lượng dữ liệu vào công cụ điều phối (orchestration).
Sử dụng chỉ số đo lường từ Data Validation trong các công cụ Data Orchestration mang đến nhiều lợi ích như giúp đưa ra quyết định chính xác, tăng chất lượng dữ liệu và sử dụng tài nguyên hiệu quả. Thêm vào đó, Data Validation còn giúp đảm bảo tính nhất quán của dữ liệu, tránh rủi ra và đảm bảo compliance.
- Bài test thành công không có nghĩa tất cả đều tốt - cũng có thể hệ thống chưa cài đặt đủ bài test.
5. Những công cụ hữu ích cho Data Validation
Dưới đây là 5 công cụ đáng chú ý để hiện thực hóa Data Validation:
- Great Expectations: Thư viện mã nguồn mở Python giúp tự động kiểm tra chất lượng dữ liệu thông qua khả năng định nghĩa và thực thi các bài test trên nhiều nguồn dữ liệu khác nhau. Các bạn có thể tìm hiểu thêm về Great Expectations tại đây.
- Deequ: Thư viện mã nguồn mở được phát triển bởi Amazon để kiểm tra chất lượng dữ liệu trong các tập dữ liệu lớn bằng cách sử dụng Apache Spark, thích hợp cho các hệ thống big data.
- Talend Data Quality: Nền tảng quản lí dữ liệu toàn diện cung cấp khả năng kiểm tra chất lượng dữ liệu trên nhiều nguồn và nền tảng dữ liệu khác nhau.
- Informatica Data Quality: Giải pháp quản lí dữ liệu mạnh mẽ và có khả năng mở rộng, cung cấp các tính năng hiện đại về kiểm tra chất lượng dữ liệu, phù hợp với các doanh nghiệp với nhu cầu lớn về xử lý dữ liệu.
- Trifacta: Công cụ hỗ trợ xử lý dữ liệu với giao diện thân thiện giúp kiểm tra và đảm bảo tính chính xác, độ tin cậy của dữ liệu trước khi phân tích.
Data Validation rất cần thiết cho mọi hệ thống xử lý dữ liệu, đây là bước đảm bảo chất lượng và độ chính xác của dữ liệu cho quá trình phân tích và đưa ra quyết định. Triển khai kiểm tra dữ liệu là điều nên làm trong các giai đoạn khác nhau của quy trình và ta cần áp dụng những chỉ số đo lường phù hợp cũng như các best practice để cải thiện hiệu suất và độ tin cậy của hệ thống xử lý dữ liệu. Bên cạnh đó, việc nắm bắt và sử dụng hiệu quả các công cụ hiện đại cũng giúp ta tối ưu hóa quá trình Data Validation.

