Giải quyết performance khi migrate từ Oracle sang MySQL
Migrate database là một công việc quan trọng và phức tạp, đòi hỏi sự chuẩn bị kỹ lưỡng và thận trọng. Bài viết này sẽ chia sẻ với các bạn những kinh nghiệm thực tế của mình khi thực hiện migrate từ Oracle lên AWS MySQL.

Một dự án migration cơ bản bao gồm:

Migrate database bao gồm migrate schema (schema, table, view, procedure, function) và dữ liệu. Bài viết này tập trung vào phần migrate schema.
Hiện nay có rất nhiều công cụ để hỗ trợ việc migrate. Ví dụ khi cần migrate lên AWS, có thể sử dụng công cụ AWS Schema Conversion Tool (AWS SCT). AWS SCT có thể hỗ trợ tự động chuyển đổi, đồng thời cảnh bảo các chỗ không thể tự động để ta có thể xử lý thủ công.
Câu hỏi đặt ra là khi tool đã hỗ trợ nhiều như thế thì còn lại gì cho Dev? Dưới đây là một vài kinh nghiệm bản thân mình đã rút ra và phần lớn đều liên quan đến vấn đề về hiệu năng. Trừ tình huống may mắn hoặc dữ liệu quá bé, thì phần lớn dự án chuyển đổi từ Oracle sang MySQL, nhất là các dự án mà logic nghiệp vụ xử lý đặt hết trong store procs thì nhất định sẽ gặp vấn đề performance.
1. Parallel Processing
Oracle hỗ trợ việc chia một task lớn thành nhiều phần nhỏ để xử lý song song. Do đó, Oracle cải thiện đáng kể hiệu suất xử lý các câu query phức tạp trong hệ thống OLAP.
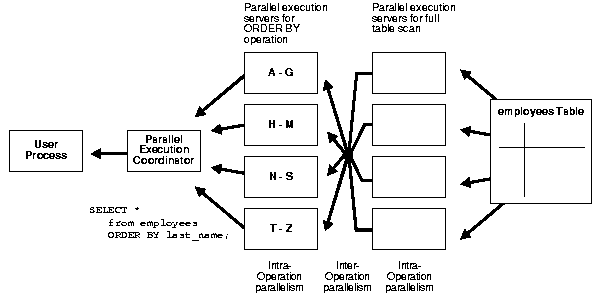
Oracle hỗ trợ parallel process bằng keyword hint parallel.
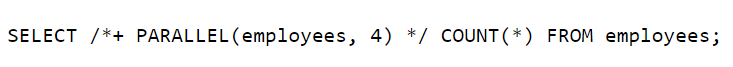
MySQL không hỗ trợ parallel processing, khi migrate thì chúng ta cần chia câu query phức tạp thành nhiều câu query, trả kết quả về tầng ứng dụng để xử lý. Ở phiên bản 8.0, MySQL bắt đầu hỗ trợ parallel processing ở một vài trường hợp hạn chế.
Một điểm đáng tiền của Oracle so với MySQL là optimizer của Oracle có nhiều thuật toán tối ưu hơn của MySQL. Trong việc join bảng, Oracle hỗ trợ 3 thuật toán là nested loop, hash join và sort-merge join. MySQL chỉ hỗ trợ nested loop, và gần đây là hash join (từ bản 8.0). Do đó, MySQL thường có performace kém trong những câu query phức tạp, bao gồm nhiều bảng hoặc các bảng lớn có nhiều dữ liệu.
Vậy chúng ta cần xác định "câu query phức tạp" để có thay đổi hợp lý khi migrate lên MySQL. Chúng ta sẽ xác định thông qua các chỉ số như logical reads, physical reads, thời gian chạy. Các thông số này có thể dễ dàng thu thập thông qua quá trình vận hành. Một "câu query phức tạp" là câu query có hơn 100 triệu logical và physical read hoặc thời gian xử lý hơn 5 giây.
Trường hợp gặp vấn đề "câu query phức tạp" khi chỉ query trong một bảng lớn, nhiều khả năng là do indexing kém hoặc do nghiệp vụ phức tạp. Chúng ta có thể thực hiện câu query ở read-only node cũng như là tối ưu lại index.
Trường hợp gặp vấn đề, chúng ta xử lý tương tự với parallel processing, tách câu query đó thành nhiều câu query đơn giản hơn rồi đưa lên tầng application để xử lý.
2. Số lượng parameter trong IN
Mặc dù MySQL không có giới hạn về số lượng parameter, MySQL optimizer sử dụng binary search để tối ưu in(...), nói cách khác là số lượng parameter càng nhiều thì performace càng thấp. Để xác định câu query có nhiều parameter, chúng ta có thể monitor trong SQL log, hoặc scan trong source code. Số lượng parameter chỉ nên dưới 100.
Để giảm số lượng parameter, ta có thay đổi câu query thành join table, hoặc chuyển thành store procedure rồi call từ application.
Oracle:select * from t where id in(id1,id2…..id1000);
MySQL:select * from t where id in(id1,id2…..id1000);
Cùng một câu query nhưng hiệu năng khi chạy ở hai hệ thống có sự khác biệt lớn.
3. Subquery
MySQL (đặc biệt là các version thấp) có thể gặp vấn đề hiệu suất khi xử lý subquery liên quan đến bảng lớn do optimizer chỉ hỗ trợ nested loop. Ở dự án trước, sau khi migrate từ Oracle lên MySQL 5.6, những câu query có nhiều subquery đã ngốn rất nhiều CPU hơn khi chạy trên Oracle cho nên mình đã phải viết lại các subquery này để phục hồi lại hệ thống.

Những phiên bản mới hơn của MySQL đã hạn chế điều này.
4. Materialized views (MV)
Với nhu cầu tổng hợp, báo cáo một lượng lớn data, các View thông thường sẽ không hiệu quả. Oracle hỗ trợ materialized views (hay còn gọi là snapshot), để lưu trữ vật lý kết quả của query vào trong view, cũng như là tối ưu về performance và bảo mật. MV của Oracle hỗ trợ rất mạnh cơ chế refresh MV để đảm bảo hiệu suất của hệ thống.
MySQL không hỗ trợ MV, nếu nhu cầu dự án cần thiết, chúng ta sẽ tự tạo các table vật lý để làm MV, thiết lập định nghĩa và cơ chế để refresh các table này. Do đó, việc refresh các MV này như thế nào cần được cân nhắc kỹ lưỡng vì sẽ ảnh hưởng rất lớn đến hiệu suất của cả hệ thống dữ liệu.
Để refresh MV, cách dễ nhất là sử dụng trigger để update MV mỗi khi có sự thay đổi của bảng chính. Dự án cũ của mình đã làm theo cách này và gây ra việc lock rất nhiều bảng khi lượng data càng ngày càng nhiều, ảnh hưởng rất lớn đến performance của dự án. Một cách phổ biến hơn là sử dụng store procedure để update MV định kì theo thời gian, ví dụ một giờ hoặc một ngày. Nếu được, việc cân nhắc kiến trúc và đưa phần xử lý nghiệp vụ lên mức application cũng là một phương án nên làm.
5. Functional Index
Functional Index cũng giống như các index thông thường, được đánh trên kết quả của hàm thay vì giá trị ban đầu của cột. Việc xử lý trước các function rồi đánh index sẽ tối ưu performance của câu query.
MySQL 5.6 không hỗ trợ Functional Index, khi migrate thì chúng ta cần viết lại câu query thành việc có thể sử dụng index.

Từ bản 5.7, MySQL hỗ trợ đánh index trên các Generated Columns, tuy nhiên vẫn còn nhiều hạn chế. Kể từ bản 8.0 thì MySQL đã hỗ trợ đầy đủ Functional Index.
Kết luận
Việc lựa chọn database mang tính chiến lược và lệ thuộc vào điều kiện của doanh nghiệp. Nếu bạn cần một hệ thống cơ sở dữ liệu ở quy mô doanh nghiệp lớn (enterprise) với độ tin cậy, tính ổn định cao và hiệu năng mạnh mẽ thì Oracle là lựa chọn tốt cho bạn. Tuy nhiên, nếu bạn cần một cơ sở dữ liệu gọn nhẹ, dễ sử dụng, không mất nhiều phí bản quyền thì MySQL vẫn là một lựa chọn thích hợp nếu thiết kế hợp lý.
Bài toán migrate vẫn sẽ còn phổ biến và đừng tin là tự nhiên mọi thứ vẫn tốt, chi phí rẻ hơn mà hiệu năng vẫn ngon. Cần dev chú ý và giải quyết các vấn đề chứ không là ăn hành đấy !

