Data Landscape và xu hướng giải pháp dữ liệu năm 2023
Bài viết này sẽ gợi ý ba xu hướng giải pháp dữ liệu đáng chú ý liên quan đến Unified Data Platform, DataOps và Data Mesh.
This post is also available in English

2020 khi bắt đầu cùng đội ngũ xây dựng bức tranh năng lực liên quan đến data platform, tôi đã thấy choáng ngợp trước sự đa dạng và có quá nhiều lựa chọn từ build đến buy đối với các components trong kiến trúc xử lý dữ liệu của doanh nghiệp. Công nghệ ngày nay cho phép xử lý những bài toán dữ liệu lớn mà cách đây 15, 20 năm vẫn còn là chủ đề nghiên cứu trong phòng lab. Thế nhưng dòng tiền đổ vào các start up công nghệ cũng làm cho bức tranh này phân mảnh và tạo ra hội chứng FOMO trong giới làm dữ liệu.

Dù có thể hy vọng rằng tương lai sẽ làm cho các công nghệ này thật sự dễ dàng integrate với nhau hay hợp nhất trong các platform một cách tiêu chuẩn, nhưng giờ đây chúng ta vẫn tạm phải chấp nhận tính đa dạng và đưa ra sự lựa chọn phù hợp trong quá trình xây dựng data platform cũng như năng lực dữ liệu của đội ngũ kĩ sư. Từ mã nguồn mở đến các platform đắt tiền hay các sản phẩm neat, mỗi giải pháp đều có một thế mạnh riêng và vẫn có tập kĩ sư trung thành riêng. Tiêu chí quan trọng của việc xây dựng hệ thống dữ liệu vẫn là gắn liền với kết quả kinh doanh của chính doanh nghiệp, còn công nghệ sẽ là yếu tố thứ hai để cân nhắc.
Không lạ gì trong giới làm công nghệ khi mỗi năm lại có một từ khóa mới để bán hàng, nếu như trước đây data streaming là hot key word thì nay là DataOps, Data Mesh và thậm chí là Data Fabric. Để lựa chọn công nghệ phù hợp bài toán, cần có sự tiếp cận khách quan với đầy đủ thông tin đánh giá theo một framework bao gồm:
- Strategy: Chiến lược kinh doanh và chiến lược dữ liệu
- Technology: Hiệu quả công nghệ, khả năng tích hợp và tính phổ dụng
- People: Hạnh phúc mà dữ liệu đem lại
Tùy vào việc bạn đang muốn bắt đầu xây dựng từ components nào, bài viết gợi ý một số xu hướng đáng chú ý mà bạn có thể bắt đầu từ bức tranh trên:
Unified Data Platform - "Tham vọng" tạo nền tảng hợp nhất
Một nền tảng dữ liệu thống nhất có nhiều lợi ích. Một trong những lợi ích đó là giảm chi phí phát triển cho việc thu thập dữ liệu. Nó cũng giúp tăng tốc độ phát triển các ứng dụng trên nền tảng và có khả năng mở rộng tốt. Ngoài ra, một hệ thống thống nhất còn giúp giảm chi phí vốn (Capex), linh hoạt trong việc nâng cấp và hạ cấp, giúp phân tích dữ liệu và hỗ trợ ra quyết định tốt hơn để thúc đẩy sự tăng trưởng và lợi nhuận kinh doanh.
Vì thế, việc triển khai hệ thống phức tạp với rất nhiều công cụ đã dần được thay thế bằng xu hướng tạo một nền tảng hợp nhất cung cấp nhiều tính năng. Khả năng tích hợp với nhiều công cụ khác nhau cũng là một yêu cầu cần thiết của việc triển khai vào các hệ thống sẵn có.
Các nền tảng dữ liệu thống nhất cho phép lập chỉ mục và tích hợp dữ liệu quan trọng, chuẩn bị và làm sạch dữ liệu nhanh chóng ở quy mô lớn mà không có giới hạn. Ngoài ra, nó cho phép đào tạo liên tục và triển khai các mô hình máy học cho các ứng dụng trí tuệ nhân tạo.
Một số nền tảng tiêu biểu là Unified Data Analytics Platform của Databricks giúp các tổ chức tăng tốc đổi mới bằng cách hợp nhất khoa học dữ liệu với kỹ thuật và nghiệp vụ, hoặc Google Cloud’s Unified Analytics Data Platform cho phép người dùng truy cập dữ liệu nằm trong kho dữ liệu mà không ảnh hưởng đến hiệu suất của các công việc khác khi truy cập kho dữ liệu đó. Một công cụ đi đầu trong xu hướng này là Azure Synapse Analytics được giới thiệu với khả năng tùy chỉnh và mô hình triển khai linh hoạt cùng giao diện tương tác mang "tham vọng" về một giải pháp hợp nhất cho bài toán xử lý dữ liệu lớn.

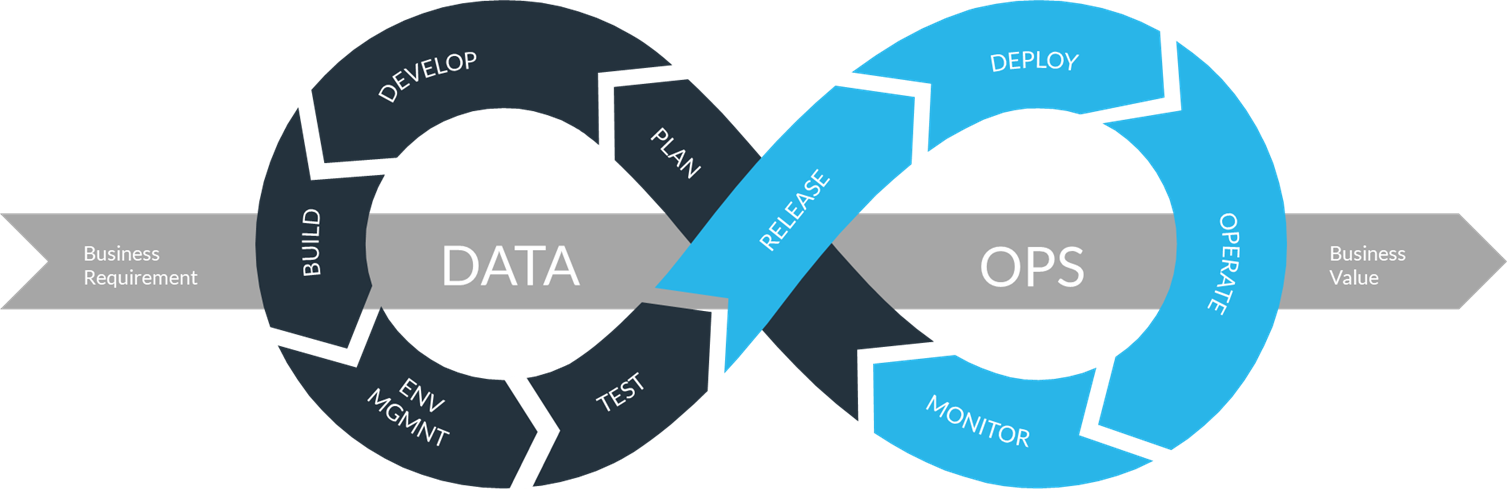
DataOps - Thiết kế quy trình và tự động hóa cho phân tích dữ liệu
Trong quá trình phát triển và mở rộng quy mô của doanh nghiệp, hệ thống dữ liệu sẽ đối mặt với một số thử thách nhất định:
- Sử dụng nhiều công cụ khác nhau trong các quá trình xử lý dữ liệu dẫn đến quá tải công nghệ
- Đội dữ liệu có các chuyên gia thuộc nhiều lĩnh vực, mỗi vai trò có yêu cầu và nhu cầu khác nhau đối với hệ thống và dữ liệu
- Sự bùng nổ về độ lớn cũng như độ phức tạp của dữ liệu theo giời gian
Các thử thách này chính là tiền đề cho DataOps.
DataOps đề cập đến các phương pháp mang lại lợi ích nhất định cho hệ thống dữ liệu như: tốc độ, sự linh hoạt, đảm bảo chất lượng, tuân thủ các quy định về bảo vệ dữ liệu,... nhằm giúp các stakeholder như người IT vận hành hệ thống, chuyên gia phân tích dữ liệu, kỹ sư dữ liệu,... có thể dễ dàng giao tiếp với nhau.
Một số ví dụ về DataOps như: Tự động kiểm tra dữ liệu nhập vào hệ thống và sau mỗi bước transformation, thông báo đến đội dữ liệu trong trường hợp có lỗi xảy ra, tự động hóa việc vận hành hệ thống và có khả năng tùy chỉnh theo từng trường hợp, những thao tác thay đổi hệ thống đều có thể version control,...
Một số công cụ hỗ trợ cho xu hướng DataOps có thể kể đến như Great Expections - công cụ hỗ trợ đặt các "kì vọng" (expectations) để kiểm tra chất lượng dữ liệu, lakeFS - công cụ version control cho data lakes, cho phép khả năng "chạy lại" các experiments cũ trong quá trình phát triển.
Các "đồ hãng" hiện đại cũng cho phép thực hiện DataOps, như Azure Data Factory đơn giản hóa xây dựng pipeline bằng giao diện trực quan, tích hợp GitHub / Azure DevOps để lưu trữ artifacts và version control,...
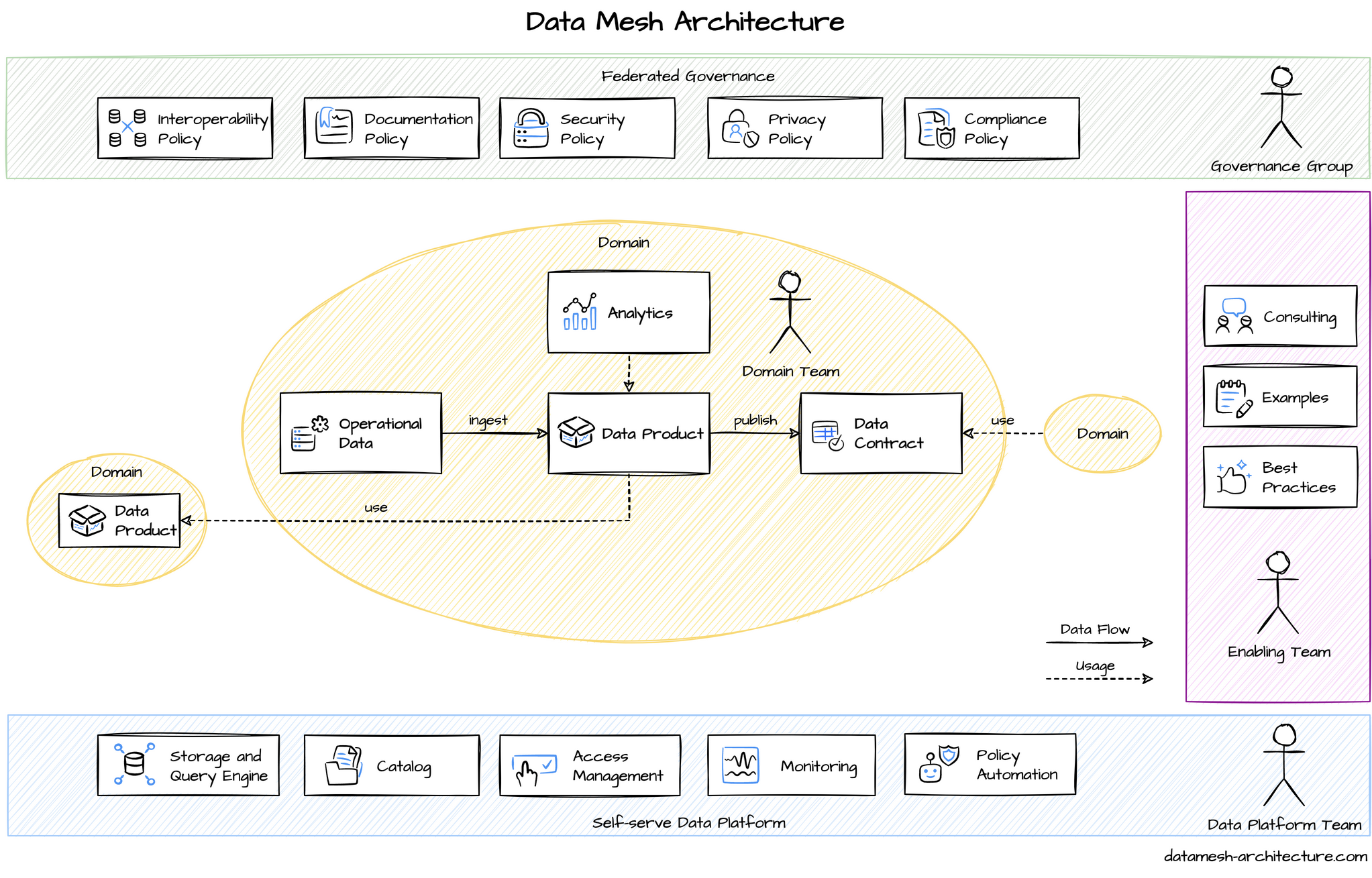
Data Mesh - Mô hình kiến trúc phân tán xử lý dữ liệu
Để có thể khai thác giá trị, dữ liệu thô luôn cần qua các giai đoạn như sắp xếp, sàng lọc, tiền xử lý,... Khi quy mô hệ thống mở rộng, dữ liệu được lấy từ nhiều nguồn hơn, cần biến đổi bằng nhiều cách khác nhau, chuyên biệt hơn. Việc này đòi hỏi đội ngũ cần có kiến thức về rất nhiều domain của dữ liệu, phải nhanh chóng đáp ứng được những thay đổi, tùy chỉnh trong hệ thống xử lý, cũng như đánh giá được giá trị của dữ liệu để cung cấp.
Để đáp ứng được nhu cầu này, mô hình Data Mesh ra đời. Trong Data Mesh, domain ownership - những người sở hữu và hiểu rất rõ về dữ liệu của mình - sẽ là những người có trách nhiệm phân tích, xử lý và cung cấp dữ liệu cho hệ thống. Việc xây dựng, thực thi, duy trì cũng như khai thác dữ liệu sẽ được thực hiện bằng những tính năng và công cụ trên một nền tảng. Việc chuẩn hóa dữ liệu để tuân thủ các quy tắc và quy định sẽ được thực hiện bởi nhóm quản trị.
Ứng dụng Data Mesh trong doanh nghiệp mang lại những lợi ích cho hệ thống dữ liệu như: tăng giá trị khai thác từ dữ liệu, tăng tính linh hoạt, tăng tỉ lệ hiệu quả trên chi phí, tăng cường bảo mật và sự tuân thủ.
Những công cụ để phục vụ việc xây dựng Data Mesh: Azure Synapse Analytics, Google Cloud BigQuery, AWS Lake Formation - AWS Data Exchanges - AWS Glue, dbt and Snowflake, Databricks...
Nguồn ảnh: Mattturck

