Các kiến trúc xử lý dữ liệu: Lambda, Kappa và Delta
Chúng ta hãy cùng tìm hiểu chi tiết về kiến trúc Lambda, Kappa và Delta, đồng thời trả lời câu hỏi điều gì làm cho mỗi kiến trúc trở nên đặc biệt và trong trường hợp nào nên ưu tiên một kiến trúc này hơn một kiến trúc khác.

Sự phát triển nhanh chóng của các ứng dụng xã hội, hệ thống dựa trên đám mây, Internet vạn vật và vô số đổi mới không ngừng khiến kiến trúc dữ liệu phải được tính toán kỹ càng. Xử lý dữ liệu cực kỳ quan trọng đối với mọi hệ thống, ví dụ như xử lý đơn đặt hàng trong hệ thống thương mại điện tử, xử lý dữ liệu cảm biến trong IoT, xử lý giao dịch thanh toán trong tài chính,...
Hiện nay có nhiều kiến trúc xử lý dữ liệu phổ biến, chúng ta hãy tìm hiểu chi tiết về kiến trúc Lambda và Kappa, đồng thời trả lời câu hỏi điều gì làm cho mỗi kiến trúc trở nên đặc biệt và trong những trường hợp nào nên ưu tiên một kiến trúc này hơn một kiến trúc khác. Chúng ta cũng sẽ khám phá thêm kiến trúc Delta đang được giới thiệu như là một sự thay thế cho Lambda và Kappa.
Lambda Architecture
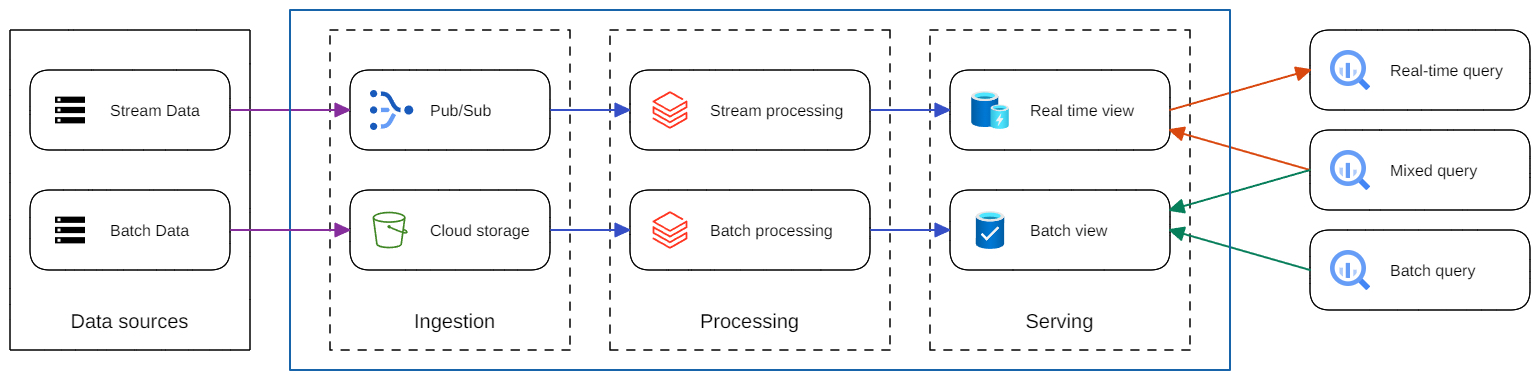
Kiến trúc Lambda là kiến trúc xử lý dữ liệu được thiết kế để xử lý lượng dữ liệu khổng lồ bằng cách tận dụng cả phương pháp xử lý hàng loạt (batch) và xử lý luồng (stream). Kiến trúc Lambda cân bằng độ trễ, thông lượng và khả năng chịu lỗi bằng cách áp dụng xử lý hàng loạt (batch) để cung cấp chế độ xem toàn diện và chính xác cho dữ liệu, đồng thời áp dụng xử lý luồng thời gian thực (stream) để cung cấp dữ liệu thời gian thực.
Hai dữ liệu batch và stream có thể được kết hợp trước khi dùng. Kiến trúc Lambda được phổ biến do sự phát triển của dữ liệu lớn, nhu cầu phân tích thời gian thực và nỗ lực giảm thiểu độ trễ của xử lý map-reduce.
Kiến trúc Lambda bao gồm ba lớp: lớp xử lý theo lô (batch), lớp xử lý tốc độ (speed) và lớp phục vụ (serving) để phản hồi các truy vấn. Các lớp xử lý lấy dữ liệu từ một bản sao của tập dữ liệu được đổ vào hệ thống.
1. Lớp xử lý dữ liệu batch
Lớp xử lý batch tính toán trước kết quả bằng cách sử dụng hệ thống xử lý phân tán có thể xử lý lượng dữ liệu rất lớn, hướng đến độ chính xác bằng cách xử lý tất cả dữ liệu. Điều này có nghĩa là ta có thể sửa bất kỳ lỗi nào bằng cách tính toán lại dựa trên tập dữ liệu hoàn chỉnh. Kết quả thường được lưu trữ trong cơ sở dữ liệu chỉ đọc, và thay thế hoàn toàn các dữ liệu tính toán trước đó.
Một số hệ thống xử lý dữ liệu batch có thể kể đến như Apache Hadoop, nổi tiếng với việc phổ biến phương pháp map-reduce. Hoặc một số dịch vụ cung cấp giải pháp tổng hợp như Snowflake, Redshift, Synapse và Big Query.
2. Lớp xử lý dữ liệu speed (hoặc còn gọi là real time)
Lớp Speed xử lý các luồng dữ liệu trong thời gian thực và không có yêu cầu sửa chữa hoặc hoàn thiện. Lớp này hy sinh thông lượng vì nó nhằm mục đích giảm thiểu độ trễ bằng cách xử lý dữ liệu trong thời gian thực. Về cơ bản, lớp tốc độ chịu trách nhiệm lấp đầy 'khoảng trống' do độ trễ của lớp batch. Dữ liệu của lớp speed có thể không chính xác hoặc đầy đủ như chế độ xem cuối cùng do lớp batch tạo ra, nhưng chúng có sẵn gần như ngay lập tức sau khi nhận được dữ liệu và có thể được thay thế khi bởi dữ liệu được xử lý do lớp batch.
Thường hay bị nhầm lẫn với micro-batch, lớp speed hoàn toàn xử lý dữ liệu theo từng dòng dữ liệu.
Các công nghệ xử lý luồng thường được sử dụng là Apache Kafka, Amazon Kinesis, Apache Storm, SQLstream, Apache Samza, Apache Spark, Azure Stream Analytics. Dữ liệu sau xử lý thường được lưu trữ trên cơ sở dữ liệu NoSQL phục vụ nhu cầu phân tích nhanh.
3. Lớp Serving
Dữ liệu được xử lý từ các lớp batch và speed được lưu trữ trong lớp serving, đáp ứng các truy vấn bằng cách trả về dữ liệu được tính toán trước hoặc dữ liệu từ kho dữ liệu (data warehouse).
Để triển khai lớp serving, ta có thể dùng các giải pháp như Apache Cassandra, Apache HBase, Azure Cosmos DB, MongoDB, VoltDB hoặc Elasticsearch cho dữ liệu của lớp Speed và Elephant DB, Apache Impala, SAP HANA hoặc Apache Hive cho dữ liệu của lớp Batch.
Để cung cấp một điểm duy nhất (end-point) để có thể để tổng hợp dữ liệu đầu ra từ cả hai lớp, ta có thể áp dụng một số giải pháp như là ảo hoá dữ liệu Dremio hoặc hệ thống truy vấn phân tán như Trino, Presto.
Một số giải pháp cơ sở dữ liệu thời gian thực cũng có thể dùng như một cơ sở dữ liệu tập trung cho cả dữ liệu batch và speed như Druid, SingleStore.
Kappa Architecture
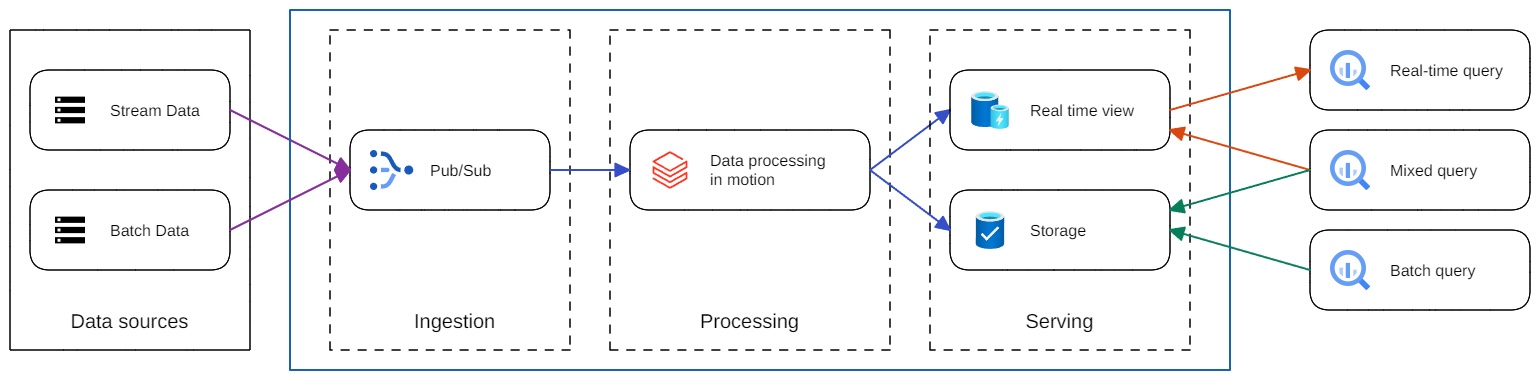
Việc sử dụng kiến trúc Lambda cho phép các kỹ sư xây dựng luồng xử lý dữ liệu luồng để phục vụ nhu cầu truy vấn dữ liệu thời gian thực. Tuy nhiên, nó cũng yêu cầu duy trì hai cơ sở mã khác nhau, một cho batch và một cho thời gian thực. Điều đó cũng gây ra khó khăn khi phải xử lý logic nghiệp vụ giữa các mã nguồn xử lý real-time và batch sao cho phù hợp.
Để khắc phục những hạn chế này, người đồng sáng lập của Apache Kafka, Jay Kreps đã đề xuất sử dụng kiến trúc Kappa cho các hệ thống xử lý luồng. Ý tưởng chính của Kreps là lưu các dữ liệu từ nguồn dữ liệu có cấu trúc vào Kafka, chẳng hạn như bảng Hive của Apache. Sau đó, chỉ cần chạy lại các xử lý luồng trên các topic Kafka này, nhờ đó mã nguồn được thống nhất giữa giữa cả luồng xử lý stream và batch.
Do thiếu kho dữ liệu hợp nhất tất cả dữ liệu tại một nơi, hệ thống xử lý stream có thể cần lưu trữ dữ liệu của nhiều năm trong hàng đợi (tức là thời gian tồn tại) để hỗ trợ các trường hợp sử dụng cần xử lý lượng lớn dữ liệu lịch sử (tương đương với lớp batch trong Lambda).
Mặc dù có rất nhiều tài liệu mô tả cách xây dựng kiến trúc Kappa, nhưng có rất ít trường hợp được trình bày về việc đã thực hiện thành công kiến trúc đó trong production.
Các công nghệ hỗ trợ kiến trúc Kappa tương đối ít, nổi tiếng nhất là Kafka Stream của chính tác giả kiến trúc Kappa. Kafka stream hỗ trợ xử lý luồng mạnh mẽ và lập trình viên có thể dùng SQL trực tiếp trên luồng một cách dễ dàng mà không phải lập trình phức tạp. KSQL cũng cung cấp đầy đủ các câu lệnh từ việc tạo các luồng xử lý, xử lý theo khung thời gian, tạo Materialize View trên luồng cũng như ghi các kết quả xử lý xuống một cơ sở dữ liệu khác.
Kafka cũng cung cấp nhiều công cụ kết nối tên là Kafka connect để giúp đổ dữ liệu từ các CSDL quan hệ vào Kafka theo thời gian thực. Ngoài ra, có thể sử dụng Debezium - một công cụ mã nguồn mở mạnh mẽ mà Atekco từng có bài rất chi tiết.
Các bạn có thể tham khảo kinh nghiệm xây dựng của đội kỹ sư Uber cũng như các điểm quan trọng khi áp dụng thiết kế Kappa.
Delta Architecture
Lambda và Kappa có thể xem là hai kiến trúc dữ liệu để xử lý lượng dữ liệu khổng lồ. Cả hai đều có điểm mạnh và điểm yếu, nhưng có thể thấy rằng trong nhiều trường hợp, Lambda là lựa chọn thiết thực hơn do có data lake để giữ hàng loạt dữ liệu ở trạng thái nghỉ.
Tuy nhiên, nhược điểm là data lake được thiết kế với tính bất biến. Nó khiến cho việc xử lý dữ liệu mỗi khi cần thay đổi phải làm lại từ đầu, làm tăng chi phí.
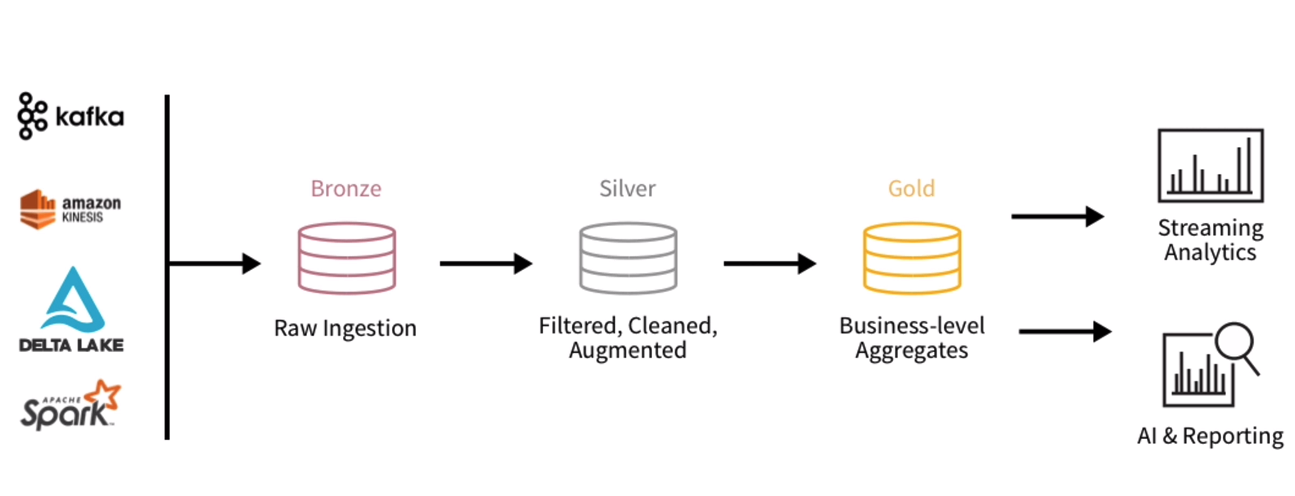
Kiến trúc Delta không còn coi data lake là bất biến. Ngược lại, dữ liệu đến được xử lý dưới dạng bản ghi “delta” (tức là sự khác biệt) chứ không phải bản ghi mới được thêm vào. Điểm quan trọng nhất là ta có thể xây dựng lại dữ liệu vận hành trên data lake chính xác như dữ liệu tại nguồn.
Trên thực tế, Delta Lake mang đến các khả năng giống như data warehouse (giao dịch ACID, DML, indexing cho dữ liệu phân tán, ..) cho data lake cũ, giúp nó hoạt động hiệu quả hơn và đáng tin cậy hơn trong quy trình xử lý dữ liệu lớn. Do đó, nó hợp nhất hai lớp một cách hiệu quả để xử lý liền mạch (nghĩa là cùng một công cụ, cùng một API và cùng một mã nguồn cho xử lý batch và real-time).
Trong kiến trúc Lambda, kiến trúc hầu như luôn bao gồm một data lake cho dữ liệu thô và một data warehouse, cộng với vùng dữ liệu tạm thời để lưu dữ liệu trước khi xử lý và sau khi xử lý (lưu trữ hay còn gọi là cold). Trong thiết lập Lakehouse, data warehouse và vùng tạm trở nên dư thừa vì tất cả các xử lý tốc độ cao đều có thể được thực hiện trong chính kho lưu trữ data lake.
Mặc dù thuật ngữ 'kiến trúc delta' ban đầu được Databricks đặt ra như một thuật ngữ marketing cho việc triển khai Delta Lake của họ, nhưng nó có liên quan đến hầu hết mọi triển khai kiến trúc dữ liệu hiện tại, thường được biết đến với tên Lakehouse. Thuật ngữ Lakehouse đầu tiên được nhắc đến trong bài trình bày của AWS tại hội nghị re:Invent 2019 và dần trở nên phổ biến. Hiện nay hầu hết các nền tảng xử lý dữ liệu lớn như Snowflake, Google Cloud BigQuery, Azure Synapse đều dùng thuật ngữ này.
Ngoài các dịch vụ đám mây còn có các công cụ mã nguồn mở để xử lý data tập trung như Spark, Flink, Trino, và framework lưu trữ hỗ trợ Lakehouse như Deltalake, Iceberg giúp ta có thể xây dựng kiến trúc Delta không phụ thuộc đám mây.
Kết
Kỷ nguyên của kiến trúc Lambda phức tạp về mặt kỹ thuật sắp kết thúc.
Những nỗ lực gần đây nhằm thống nhất các luồng xử lý theo batch và theo thời gian thực trong các nền tảng dữ liệu đang thu hút được sự chú ý. Kiến trúc delta, đặc biệt khi kết hợp với data warehouse liền lạc mang lại cơ hội tuyệt vời để triển khai nền tảng dữ liệu linh hoạt và có thể mở rộng cho cả trường hợp sử dụng dữ liệu lớn và nhỏ. Nó cũng giúp lập trình viên mất ít thời gian trong việc viết code để tập trung vào nghiệp vụ, giảm thời gian phát triển hệ thống và làm tăng hiệu quả của việc xây dựng cũng như bảo trì các nền tảng dữ liệu lớn và linh động.

