- What is Microsoft Fabric?
- Pricing models
- Get started with lakehouses in Microsoft Fabric
- Use Data Factory pipelines to ingest Data with Dataflows in Microsoft Fabric
- Use Apache Spark in Microsoft Fabric
- Design & build data warehouses with Microsoft Fabric
- Real-Time Analytics in Microsoft Fabric
- Final thoughts
Microsoft Fabric hands-on experience with preview version
Microsoft Fabric is an all-inclusive analytics solution that was just released. The preview version of this service will be examined to discuss initial impressions in this article, along with the reasons why it has raised such a frenzied reaction among techies.
Bài viết này có phiên bản Tiếng Việt

What is Microsoft Fabric?
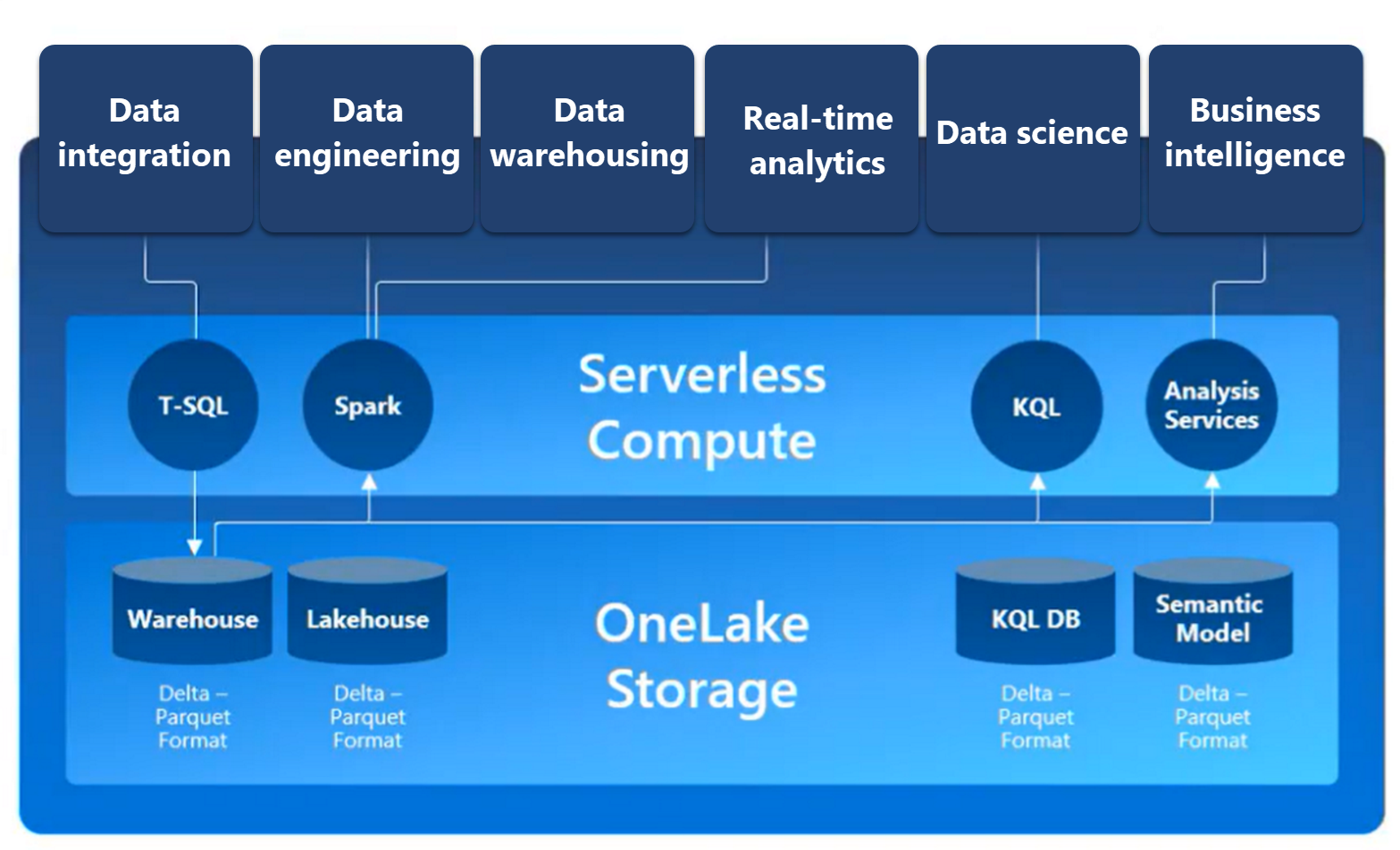
Microsoft Fabric is an end-to-end analytics solution with full-service capabilities including data movement, data lakes, data engineering, data integration, data science, real-time analytics, and business intelligence, all backed by a shared platform providing robust data security, governance, and compliance. Fabric integrates technologies like Azure Data Factory, Azure Synapse Analytics, and Power BI into a single unified product. It provides all the capabilities required for a developer to extract insights from data and present them to the business user.
Fabric provides a comprehensive data analytics solution by unifying all these experiences on a single platform.
- Synapse Data Engineering: data engineering with a Spark platform for data transformation at scale.
- Synapse Data Warehouse: data warehousing with industry-leading SQL performance and scale to support data use.
- Synapse Data Science: data science with Azure Machine Learning and Spark for model training and execution tracking in a scalable environment.
- Synapse Real-Time Analytics: real-time analytics to query and analyze large volumes of data in real-time.
- Data Factory: data integration combining Power Query with the scale of Azure Data Factory to move and transform data.
- Power BI: Fabric provides a set of tools for visualizing data and creating reports.
Pricing models
Microsoft Fabric is a service in the Office 365 segment with the prefix Microsoft, not a service in the Azure Cloud segment with the prefix Azure. To recap a bit, Office 365 provides subscription-based office services, including services such as Word, Excel, Powerpoint etc. Azure Cloud provides infrastructure, tools, and services for developers to create and manage applications, pay as you go.
Microsoft Fabric operates on two types of SKUs, each SKU provides a different amount of computing power, measured by its Capacity Unit (CU) value.
- Microsoft 365 SKUs: must be a subscription plan that has PowerBI, because Microsoft Fabric is enabled on top of Power BI subscription.
- Azure SKUs: Microsoft Fabric must be linked to Azure Subscription to customize parameters such as the size of compute, capacity etc. For more information, please refer to this article.
Get started with lakehouses in Microsoft Fabric
OneLake combines storage locations across different regions and clouds into a single logical lake, without moving or duplicating data. Similar to how Office applications are prewired to use your organizational OneDrive, all the compute workloads in Fabric are preconfigured to work with OneLake. Fabric's data warehousing, data engineering (Lakehouses and Notebooks), data integration (pipelines and dataflows), real-time analytics, and Power BI all use OneLake as their native store without needing any extra configuration.
OneLake is built on top of Azure Data Lake Storage (ADLS) and supports data in any file format, including Delta Parquet, CSV, JSON, Excel and more.
Fabric's OneLake is centrally governed and open for collaboration. Data is secured and governed in one place while remaining discoverable and accessible to users who should have access across your organization. Fabric administration is centralized in the Admin Center.
The foundation of Microsoft Fabric is a Lakehouse, which is built on top of the OneLake, a scalable storage layer and uses Apache Spark and SQL compute engine for big data processing. A Lakehouse is a unified platform that combines:
- The flexible and scalable storage of a data lake
- The ability to query and analyze data of a data warehouse
In Microsoft Fabric, a lakehouse provides highly scalable file storage in a OneLake store (built on Azure Data Lake Store Gen2) with a metastore for relational objects such as tables and views based on the open-source Delta Lake table format. We can define a schema in Delta Lake and allow people to query using SQL.
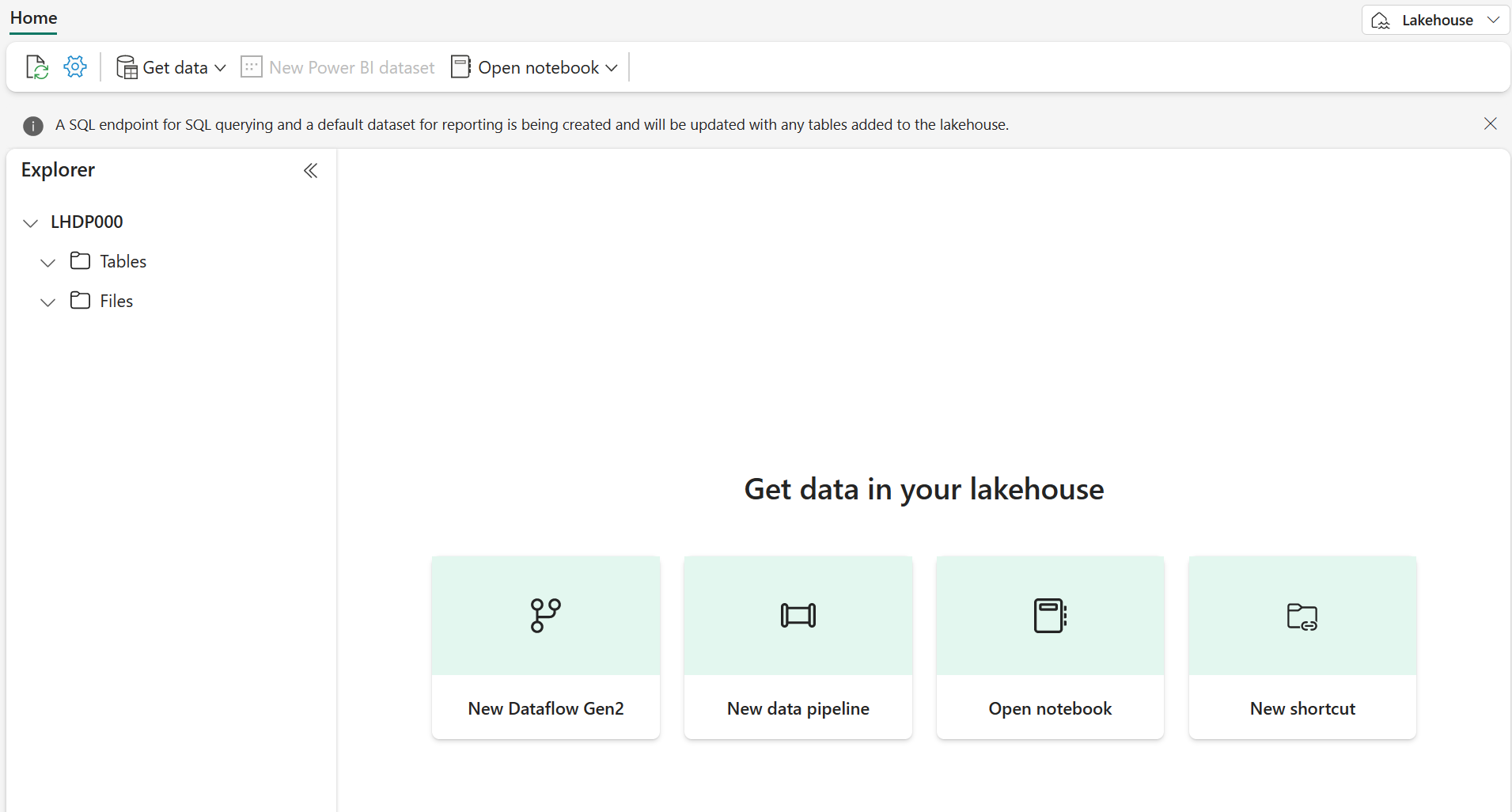
Tables in a Microsoft Fabric lakehouse are based on the Delta Lake storage format. Delta Lake is an open-source storage layer for Spark that enables relational database capabilities for batch and streaming data. By using Delta Lake, we can implement a lakehouse architecture to support SQL-based data manipulation semantics in Spark with support for transactions and schema enforcement. The result is an analytical data store that offers many of the advantages of a relational database system with the flexibility of data file storage in a data lake.
Use Data Factory pipelines to ingest Data with Dataflows in Microsoft Fabric
Microsoft Fabric includes Data Factory capabilities, including the ability to create pipelines that orchestrate data ingestion and transformation tasks. Microsoft Fabric's Data Factory offers Dataflows (Gen2) for visually creating multi-step data ingestion and transformation using Power Query Online.
Microsoft Fabric's Data Factory experience is quite similar to that on Azure Data Factory (ADF). Those who have used ADF will quickly become familiar with things like creating linked services, activities, triggers and monitors.
However, Data Factory on Microsoft Fabric is newly developed recently, so there are also some certain differences.
- Not integrated with git, users have to manage source version control by themselves. Therefore, it is only suitable for personal projects or very small teams.
- All resources (pipeline, dataflow, dataset etc.) are put together in one folder called workspace, it will be difficult to manage resources as the project grows bigger.
- ADF supports built-in native mapping data flows and data wrangling with Power Query to transform data. In addition, ADF also supports hand-code transformations such as HDInsight Hive, Spark, Store Procedures, Spark Notebook etc. On the other hand, Data Factory on Microsoft Fabric only supports one tool, which is Power Query for data transformations.
- Not yet supporting many connectors to integrate with other systems. Especially sink connector currently only supports OneLake and some Azure services.

One point I really like here is that Pipeline is started very fast, it takes almost no time to start Integration runtimes (ADF takes more than 1 minute to start)
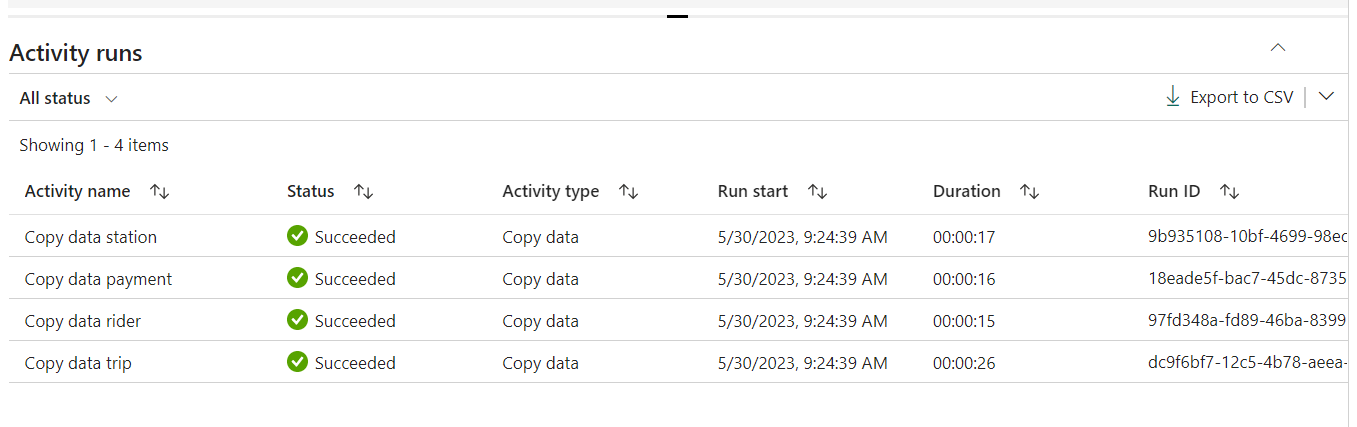
Use Apache Spark in Microsoft Fabric
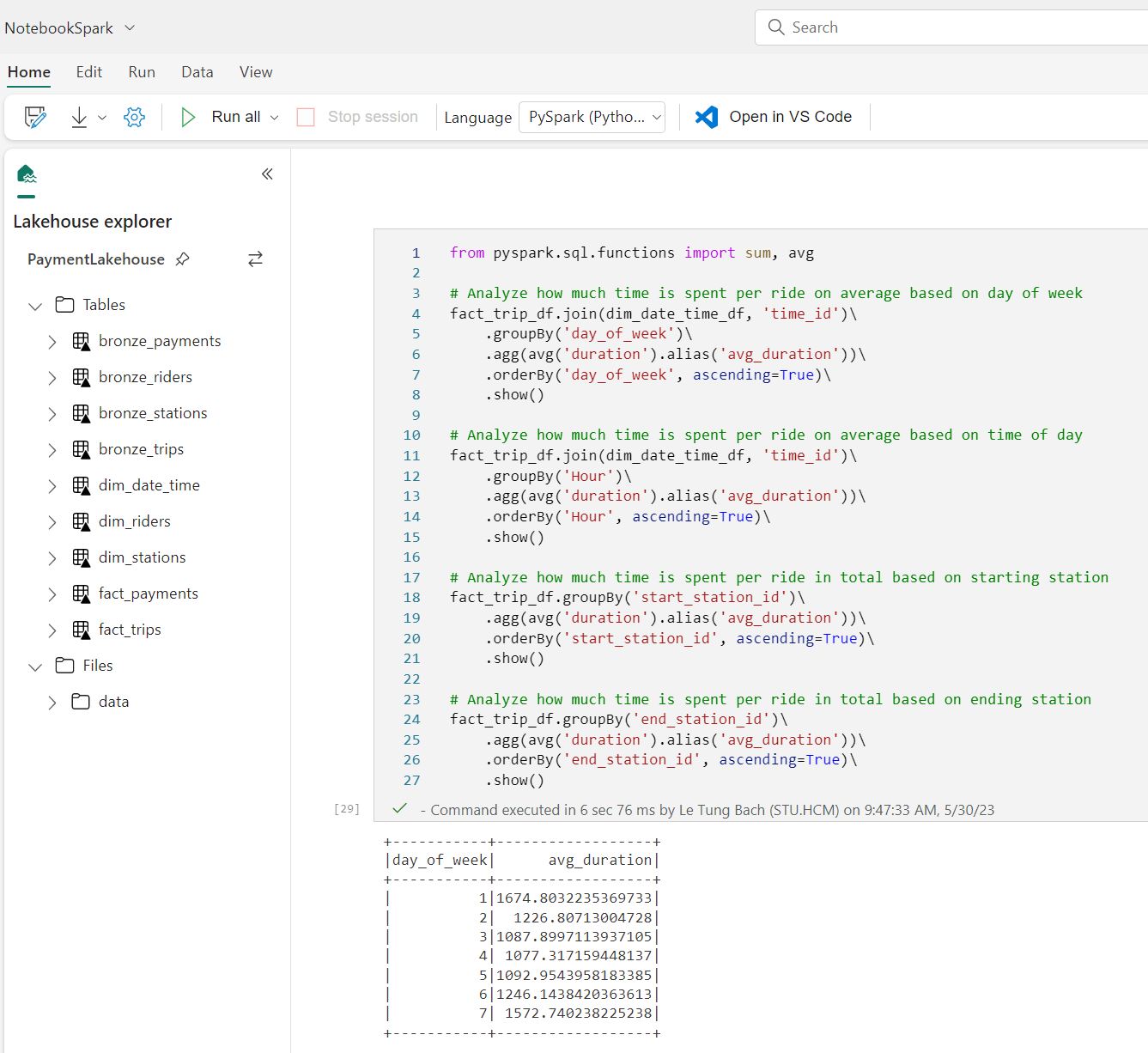
Apache Spark is a core technology for large-scale data analytics. Microsoft Fabric provides support for Spark clusters, enabling data engineers to analyze and process data in a Lakehouse at scale.
Using Spark Notebook on Microsoft Fabric is almost similar to Azure Synapse. Basic features such as interacting with lakehouse, command prompts, sniplets remain the same.
To run Notebook on Microsoft Fabric, the only thing to do is press the run button, and the code runs, no need for provision, just write the code. If on the Synapse side, the cluster needs a long time to start, on Microsoft Fabric it only takes a few seconds.
The concept of infra or cluster is almost hidden from the user, we just need to focus on the code, I really like it.
Design & build data warehouses with Microsoft Fabric
Fabric support 2 data warehousing approach: the SQL Endpoint of the Lakehouse and the Warehouse. Via the SQL Endpoint of the Lakehouse, the user has a subset of SQL commands that can define and query data objects but not manipulate the data. Data Warehouse supports transactions, DDL, and DML queries.
Warehouse in Microsoft Fabric offers built-in data ingestion tools that allow users to ingest data into warehouses using code-free or code-rich experiences. Data can be ingested into the Warehouse through Pipelines, Dataflows, cross-database querying or the COPY INTO command. Fabric makes things easier by allowing users to analyze lake data in any lakehouse, using Synapse Spark, Azure Databricks, or any other lake-centric data engineering engine. The data can be stored in Azure Data Lake Storage or Amazon S3.
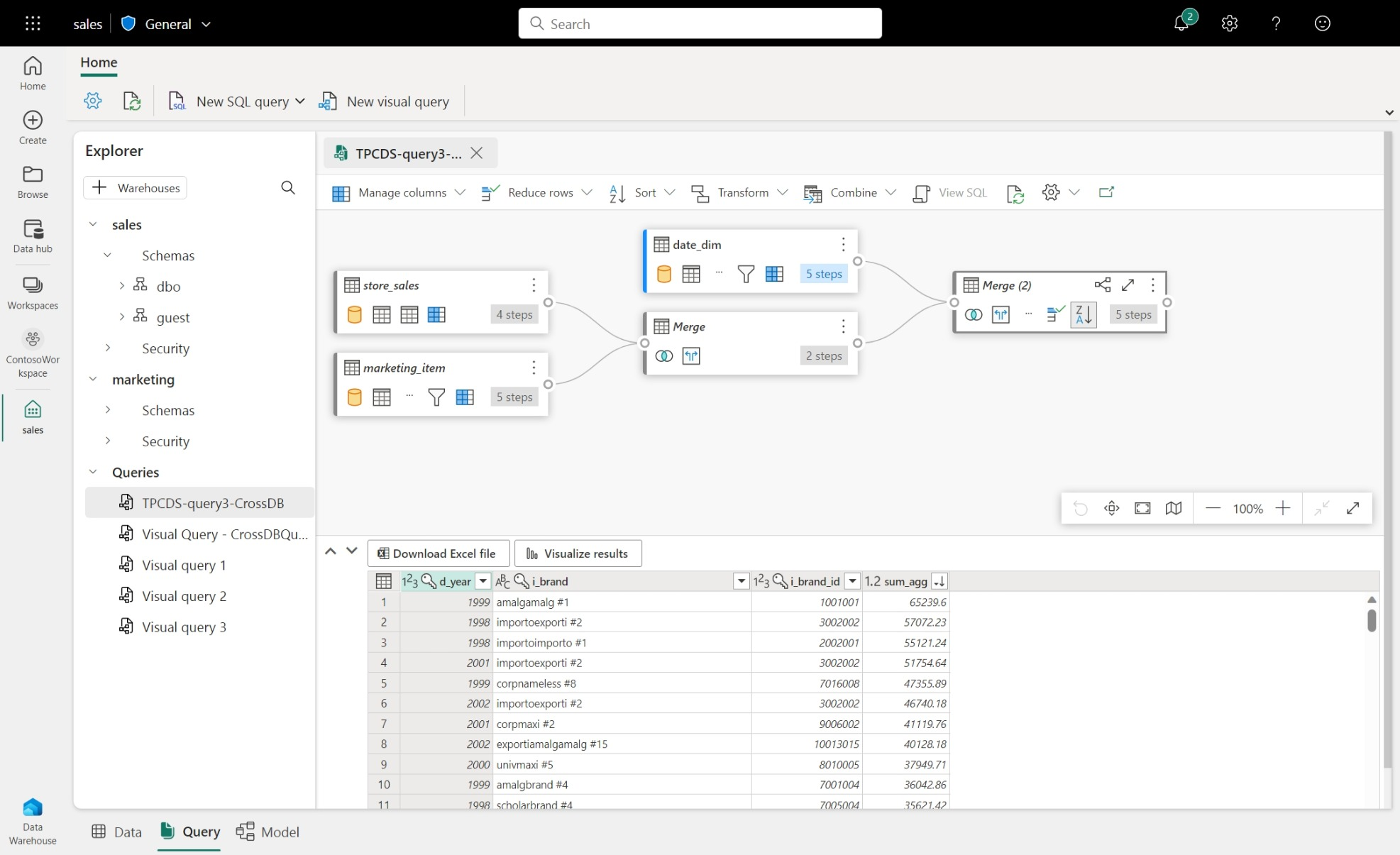
We can also create a shortcut to reference data without copying it and instantly perform customized analytics from the same shared data. After connecting to shared data, we can query data directly by using T-SQL, we can even join data from linked tables with existing tables in our data warehouse.
We can query the data with multiple tools, including the Visual Query Editor and the SQL Query Editor in the Microsoft Fabric portal. From my experience, Visual Query Editor is still in the early phase, and not good enough to be used as a main query tool.
Real-Time Analytics in Microsoft Fabric
Analysis of real-time data streams is a critical capability for any modern data analytics solution. We can use the Real-Time Analytics capabilities of Microsoft Fabric to ingest, query, and process streams of data. Microsoft Fabric support KQL database (Kusto database) to store real-time data, then we can use the KQL Queryset to run queries, view and manipulate query results on data from Data Explorer database. The Eventstream feature allows us to integrate streaming data from multiple source types, which include Event hubs and custom apps. Once we've established data sources, we can then send the streaming data to multiple destinations including a Lakehouse, KQL Database, or a custom app.
Creating a dashboard with real-time data from KQL database is very easy, we just need to create a KQL Query set and select Build Power BI Report, Fabric will create a Power BI automatically with Kusto Query Result as the data source.
Final thoughts
Even though Fabric is still in the preview phase, it’s promising to be a powerful tool that simplifies the process of creating data solutions. It allows us to design, build and deploy data pipelines with ease and speed. Using Fabric, we don't have to worry about managing the underlying infrastructure or stitching together different services from multiple vendors. Instead, we can focus on extracting insights from our data and laying the foundation for the era of AI.
We can sign up within seconds and get real business value within minutes. Fabric also provides centralized administration and governance across all experiences, so we can ensure data quality, security, and compliance.
However, I'm still concerned about the cost of using Fabric. SaaS solutions can be expensive in the long run, especially if we have a large amount of data or complex analytics needs. I'm not sure how Fabric charges for its services or how it compares to other alternatives in the market. Techies should acknowledge more about the pricing model and the return on investment of Fabric before deciding to adopt it.

