All about Change Data Capture and Debezium (Part 1)
In this series, Atekco introduces Change Data Capture technique, using Debezium tool to monitor the source database and identify changes, supporting data processing and data analytics effectively.
Bài viết này có phiên bản Tiếng Việt

Every operating system will have data and transactions stored in operational database. These transactions are very meaningful and important because it provides customer insights, business results, operating status of the business... To avoid affecting the operational system’s performance, transactional data will be replicated to the Data Warehouse for analysis purposes.
Traditionally, systems often use the batch-processing method to process and transfer data to the Data Warehouse once or several times a day. However, this will create latency and reduce the value of the data. With some specific businesses, the value of data will decrease over time, such as financial data, stocks, etc.
Therefore, the need for a method to migrate and replicate data continuously between databases is very urgent. Change Data Capture has emerged as a solution to continuously detect changes in the source database, thereby supporting data processing and data analytics effectively and immediately.
What is Change Data Capture?
Change Data Capture (CDC) is a technique as well as a design pattern to design a system through which we can track changes occurring in the source database.
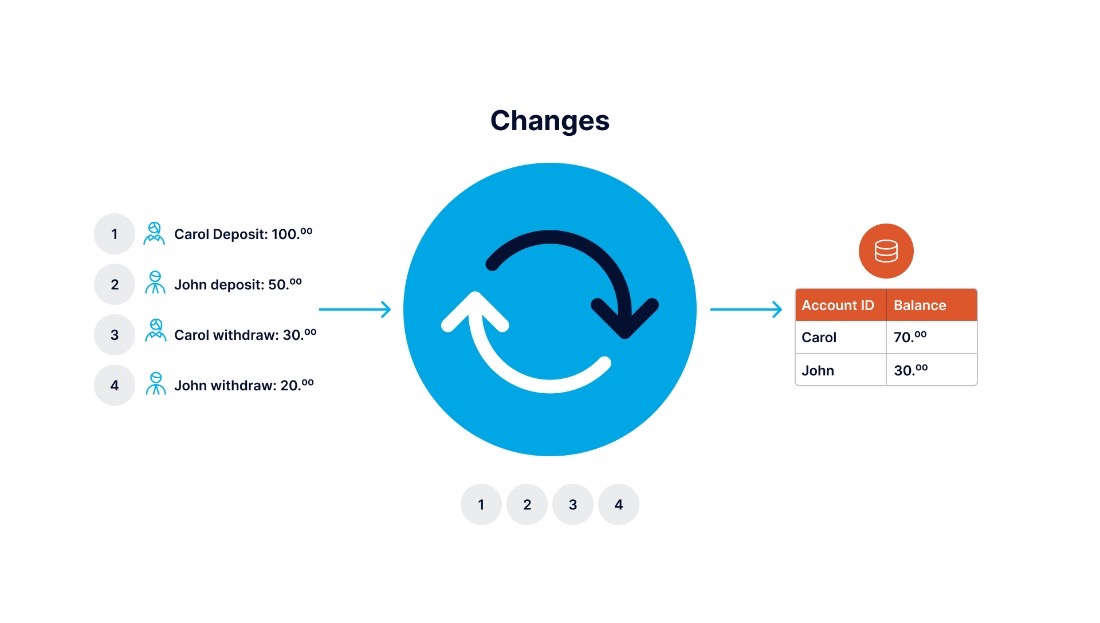
With the use of CDC, we can easily copy, replicate or migrate data between many different databases in real-time.
Thanks to CDC, the system will be able to incrementally load changes from the source database instead of bulk loads.
Advantages of CDC
Compared with traditional batch-processing, CDC offers many distinct advantages:

Debezium
Debezium is a distributed platform that converts information from your existing databases into event streams, enabling applications to detect, and immediately respond to row-level changes in the databases.
Normally, each transaction that occurs in the database is saved in the transaction log, and different databases will have different ways of recording transaction log.
Debezium will use connectors that read transaction log to detect changes that have occurred in the source database, thereby Debezium can track changes at row-level. Then, the change-events corresponding to each transaction will be created and sent to the streaming services like Kafka, AWS Kinesis, etc.
Up to now, Debezium has supported both Relational and Non-Relational Database, for example: MySQL, SQL Server, MongoDB, ...
Embedded Debezium
Normally, Debezium is operated by deploying to Kafka Connect, one or more connectors will be used to track the source database and produce change-events for each transaction in the source database. These change-events will be recorded and saved to Kafka, then the target applications can consume from Kafka.
Kafka Connect is preferred because it has the advantage of providing excellent fault tolerance and scalability, it will act as a distributed service and ensure that the registered connectors will always run stability. For example, even if one endpoint of Kafka Connect is down, remaining endpoints will automatically restart the previous connectors running on the old endpoint, thereby minimizing downtime of the system.
However, not all applications need such a high level of fault tolerance, many applications do not want to depend on external clusters like Kafka and Kafka Connect and prefer a compact architecture. So, instead of using Kafka Connect, these apps will integrate Debezium connector directly into the app. Therefore, Debezium has provided a module called debezium-api, this API allows the application to easily configure and use the Debezium connector and Debezium Engine.
Here is a sample architecture when using the Embedded Debezium instance in a Java application:
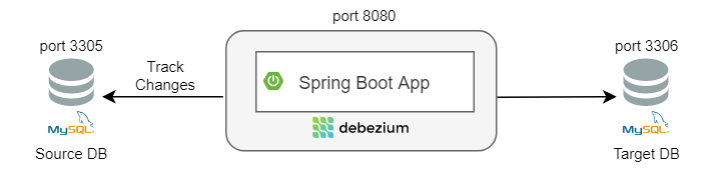
In the above architecture pattern, we have 1 source database, 1 Java Spring Boot application and 1 target database.
Inside the Java application, we will have a built-in Debezium Engine and functions to monitor and track changes in the source database (MySQL).
Then change-events that Debezium produces from the left source database can also be handled in this Java application (for example, we can extract information from change-events, then execute updates to the target database).
Below is an example about Maven dependencies:
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-api</artifactId>
<version>1.4.2.Final</version>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-embedded</artifactId>
<version>1.4.2.Final</version>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-connector-mysql</artifactId>
<version>1.4.2.Final</version>
</dependency>
Here is a sample Java code using Embedded Debezium:
// Define the configuration for the Debezium Engine with MySQL connector...
final Properties props = config.asProperties();
props.setProperty("name", "engine");
props.setProperty("offset.storage", "org.apache.kafka.connect.storage.FileOffsetBackingStore");
props.setProperty("offset.storage.file.filename", "/tmp/offsets.dat");
props.setProperty("offset.flush.interval.ms", "60000");
/* begin connector properties */
props.setProperty("database.hostname", "localhost");
props.setProperty("database.port", "3306");
props.setProperty("database.user", "mysqluser");
props.setProperty("database.password", "mysqlpw");
props.setProperty("database.server.id", "85744");
props.setProperty("database.server.name", "my-app-connector");
props.setProperty("database.history",
"io.debezium.relational.history.FileDatabaseHistory");
props.setProperty("database.history.file.filename",
"/path/to/storage/dbhistory.dat");
// Create the engine with this configuration ...
try (DebeziumEngine<ChangeEvent<String, String>> engine = DebeziumEngine.create(Json.class)
.using(props)
.notifying(record -> {
System.out.println(record);
}).build()
) {
// Run the engine asynchronously ...
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute(engine);
// Do something else or wait for a signal or an event
}
// Engine is stopped when the main code is finished
Read more details here.
Architecture with Kafka Connect
The most common architecture of a system using Debezium is the integration of Debezium with Kafka Connect.
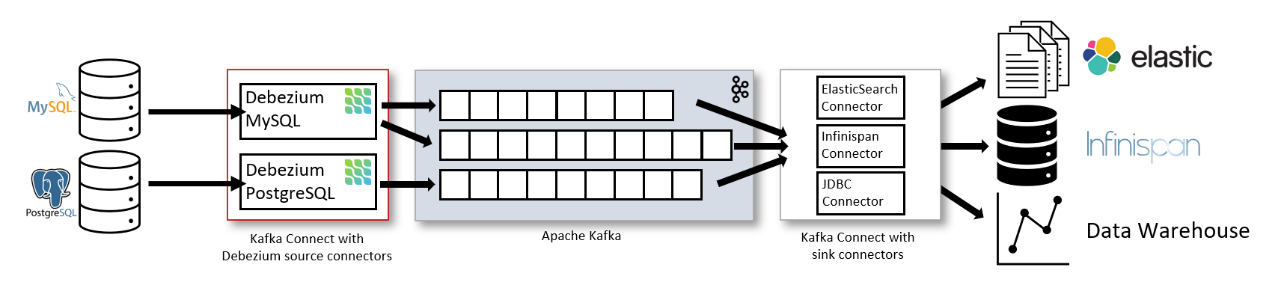
Kafka Connect is a framework that works as a separate service and runs in along with Kafka Broker, which aims to transmit data from other systems to Kafka, and vice versa.
With the above architecture, Kafka Connect manages and operates modules such as:
- Source Connector: Debezium connector that we use to monitor the source database.
- Sink Connector: Connector to transmit data from Kafka to target database
In the above sample architecture, we will have:
- 2 source databases to be monitored: MySQL DB and PostgreSQL DB
- 2 Debezium connectors correspond to 2 databases
These 2 connectors will be registered with Kafka Connect, from which Kafka Connect will manage and transfer data from Debezium to Kafka Topic.
- 2 Kafka Connect: 1 for source connector management, 1 for sink connector management.
- Kafka: Streaming Service stores and processes events received from Debezium.
- 3 sink connectors: Elastic Search connector, Infinispan connector, JDBC connector to transmit data from Kafka to external systems.
- 3 target systems: Elastic Search, Infinispan, Data Warehouse
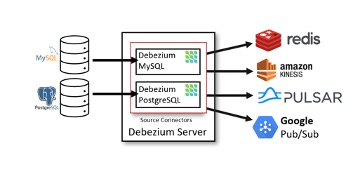
Debezium Server
Beside Kafka Connect, Debezium can also integrate with Debezium Server as an alternative to transmit events to streaming services such as: Amazon Kinesis, Google Pub/Sub, Pulsar, ...
Debezium Server is an application that supports transferring change-event from Debezium to message infrastructures. When integrating Debezium with Debezium Server, we can set up configuration via config file easily.
Click here for more details.
Performance Testing
After understanding the impact of Debezium and popular architectures of systems integrated with Debezium, we will come to a very important part, which is to evaluate the performance of this tool.
This test is performed on an Azure VM with the following configuration:

We will evaluate the performance of Debezium in two scenarios:
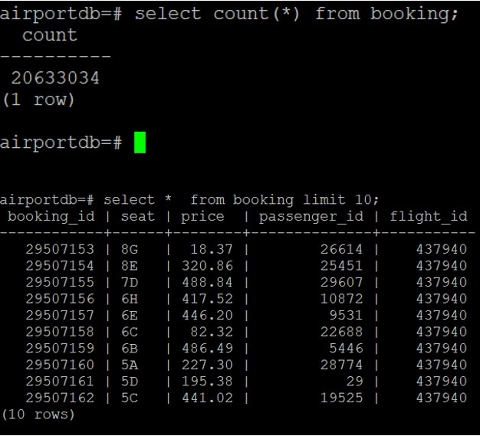
1. Case 1
Description:
- The source database side has a lot of data.
- The target database has no records yet.
- Debezium connector, after being registered with Kafka Connect, begins to perform an initial snapshot to capture all the data that the source database has.
- Then all records of this snapshot version are regarded as new records for the target database side and the corresponding change-events are created.
- Synchronization between the source database and the target database also begins.
Statistics:

2. Case 2
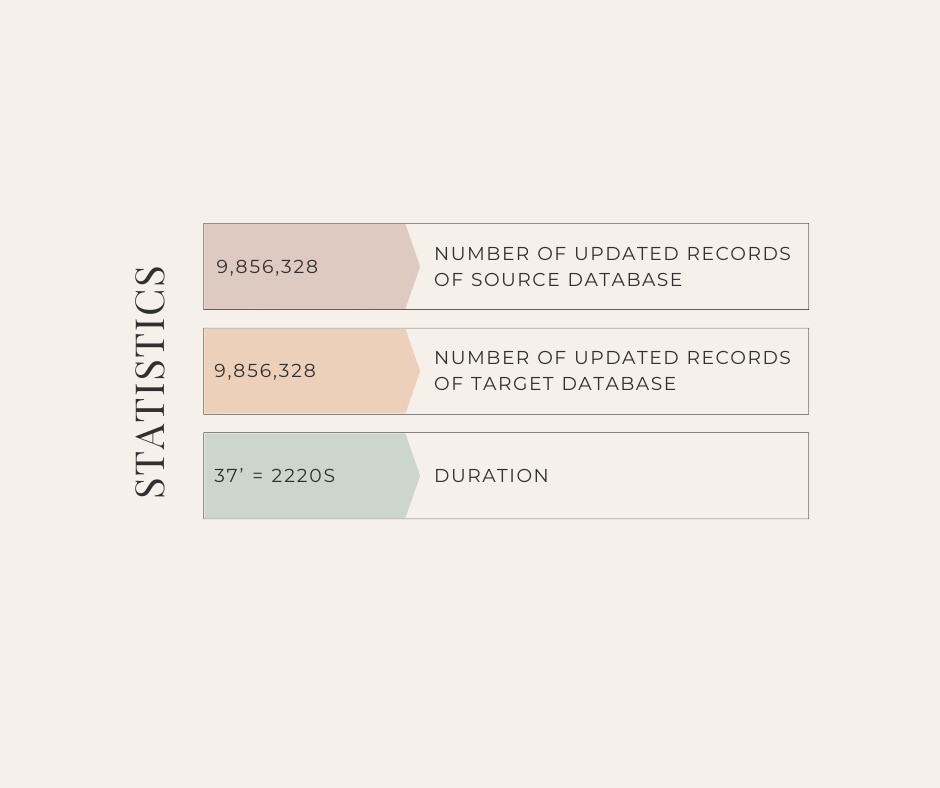
Description:
- After the two sides of the database (source and target) have the same amount of data and the data is the same, the source database side naturally generates a large amount of updates.
- There are about 10 million records updated.
- We will measure how long it takes for the source and target database data to be fully synchronized.
Statistics:


Pros and Cons
Nothing is perfect and neither is Debezium. This tool has both its own advantages and disadvantages.
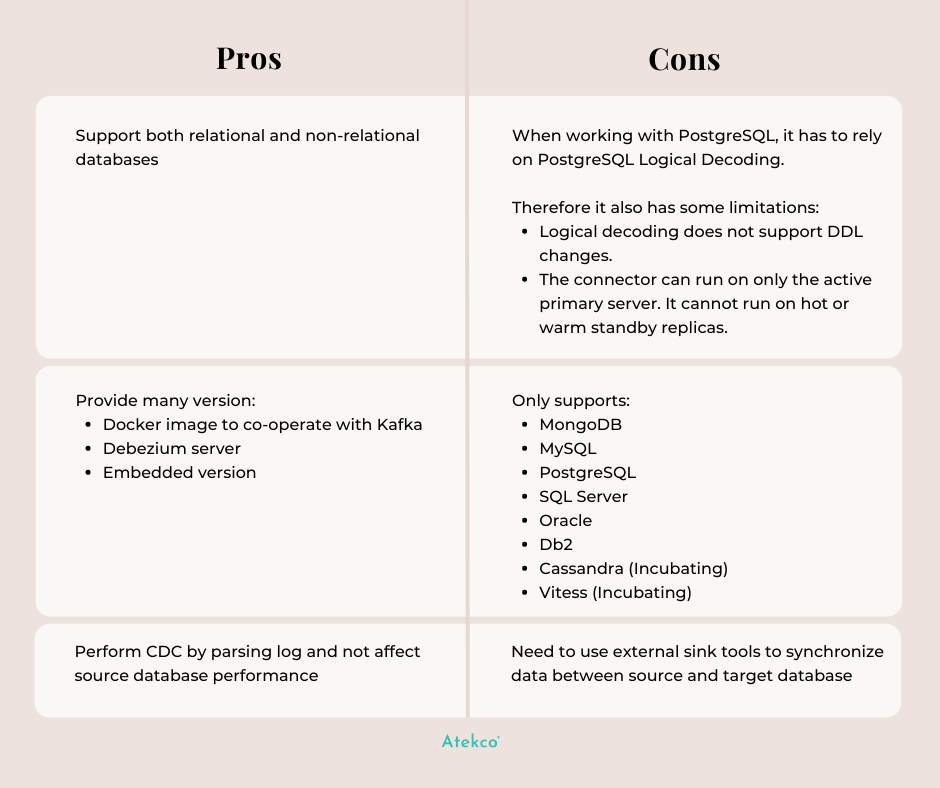
Debezium is quite light-weight which focuses on performing CDC. Last but not least, it has Apache License so it's free!
So we have ended part 1 of the series about Change Data Capture and Debezium. In the next section, we will have specific demos to understand more about how to use Debezium. Stay tuned!

