- 1. Giai đoạn tiền đề (2015 - 2019): Sự phân mảnh theo framework và vấn đề tương thích
- 2. Giai đoạn bùng nổ & lượng tử hóa mô hình (2020 - 2022): Thu nhỏ mô hình, đưa AI về máy cá nhân
- 3. Giai đoạn chuẩn hóa (2023 - 2024): Định dạng GGUF thống nhất cho kỷ nguyên Local AI
- 4. Giai đoạn AI thích ứng (2024 trở đi): Định dạng LLM thích ứng theo thiết bị và môi trường
Chặng đường tiến hóa của định dạng mô hình LLM
Điểm lại hành trình 'lột xác' của định dạng mô hình LLM với các bước ngoặt công nghệ, đưa AI đến gần với người dùng ở khắp mọi nơi và trên mọi thiết bị.

Chỉ trong một thập kỉ, các mô hình ngôn ngữ lớn (LLM) đã phát triển vượt bậc, từ những mô hình gắn liền với framework đến các mô hình chạy trên cả siêu máy chủ lẫn laptop cá nhân. Đằng sau mỗi bước tiến là một chặng đường của sự đổi mới.
Việc các mô hình LLM được tạo ra, lưu trữ, chia sẻ và triển khai hiệu quả phụ thuộc rất lớn vào định dạng mà chúng được đóng gói. Nhiều thách thức đối với định dạng mô hình như việc không tương thích giữa các framework, hay kích thước mô hình quá lớn chỉ có thể chạy trên nền ảo hóa, đến yêu cầu tối ưu hóa để chạy tại chỗ (on-device), trên CPU, GPU và cả thiết bị di động. Chính những thách thức đó đã thúc đẩy các định dạng mới ra đời, cùng với các công nghệ quantization, tối ưu hóa xử lý tải mô hình và tiêu chuẩn hóa metadata.
Bài viết này sẽ điểm lại quá trình tiến hóa của định dạng mô hình LLM với 4 giai đoạn chính, từng bước đưa AI sinh ngữ cảnh đến gần hơn với từng người dùng.
Ở mỗi giai đoạn là một kỹ thuật đặc trưng, từ đó dẫn đến một đột phá công nghệ tương ứng. Định dạng mô hình mới ra đời như một 'cú hích' vượt qua những giới hạn cũ, nhưng đồng thời lại đặt ra những yêu cầu mới cho giai đoạn tiếp theo.
1. Giai đoạn tiền đề (2015 - 2019): Sự phân mảnh theo framework và vấn đề tương thích
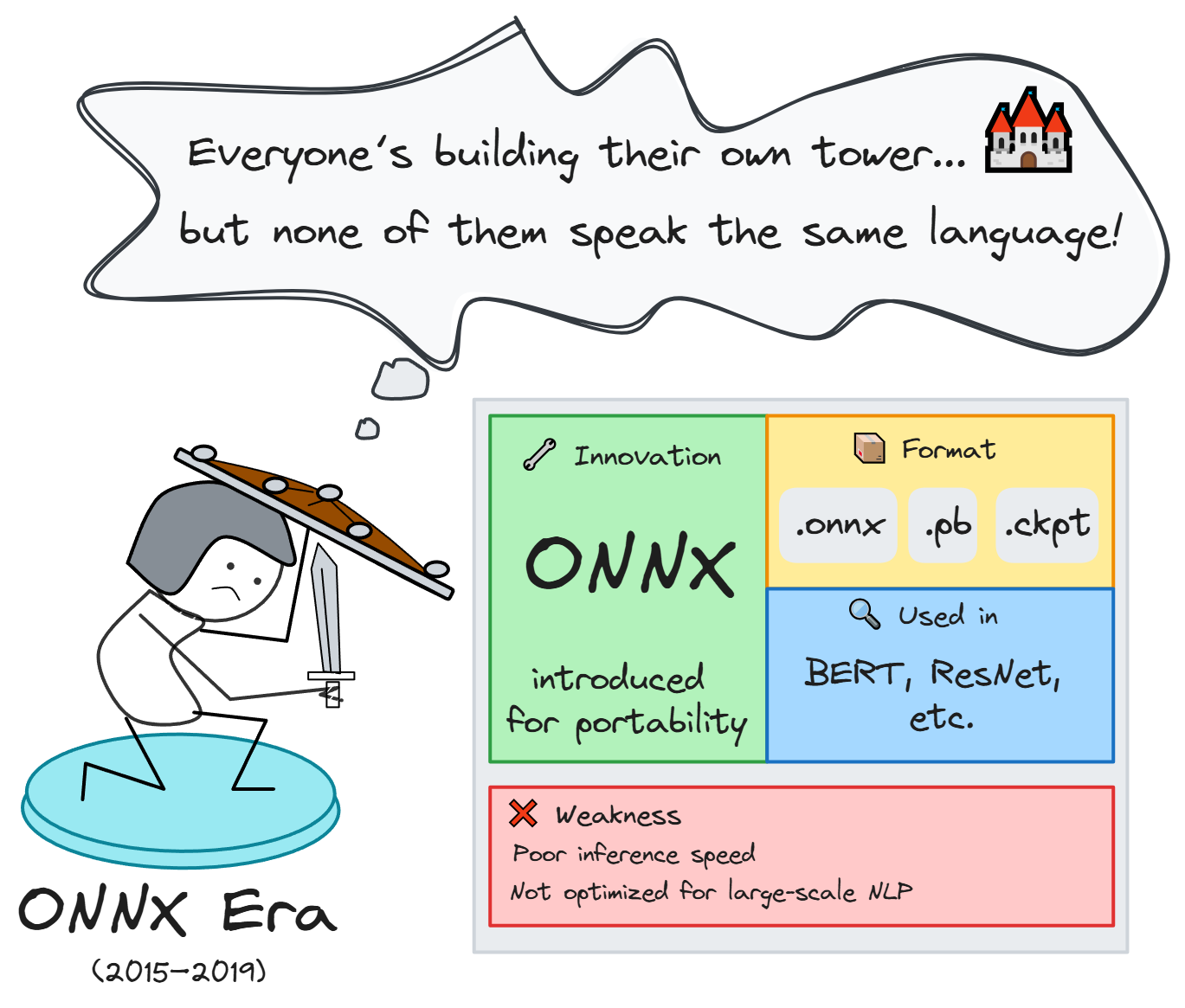
Từ năm 2015 đến 2019, các mô hình học sâu (Deep Learning) bắt đầu được ứng dụng rộng rãi trong nhiều lĩnh vực như thị giác máy tính, xử lý ngôn ngữ tự nhiên và nhận dạng giọng nói. Tuy nhiên, đây là giai đoạn mà hệ sinh thái mô hình vẫn chịu sự phân mảnh sâu sắc bởi sự gắn kết chặt chẽ giữa mô hình và framework huấn luyện tương ứng.
Các vấn đề cốt lõi trong giai đoạn này gồm:
- Thiếu chuẩn định dạng chung cho việc lưu trữ và triển khai mô hình, dẫn đến khó khăn trong việc chuyển giao giữa các nền tảng hoặc tích hợp vào pipeline sản xuất.
- Mỗi framework sử dụng cơ chế serialization riêng: TensorFlow sử dụng
.pb,.ckpt; PyTorch dùng.pt,.bin- gây ra hiện tượng lock-in trong việc lưu trữ và runtime. - Không có chuẩn hóa cho inference engine: việc triển khai model vào production đòi hỏi viết lại logic hoặc xây dựng bridge tùy biến giữa các backend.
Sự ra đời của ONNX
Để giải quyết sự thiếu tương thích giữa các framework, ONNX (Open Neural Network Exchange) ra đời như một định dạng trung gian, cho phép chuyển đổi mô hình giữa các nền tảng khác nhau và triển khai dễ dàng với ONNX Runtime, TensorRT hoặc OpenVINO. Nhờ tính linh hoạt và khả năng tối ưu hóa inference trên nhiều loại phần cứng, ONNX nhanh chóng được tích hợp trong các hệ thống thương mại lớn như Microsoft Cognitive Services, các ứng dụng edge dùng YOLOv3, ResNet hay MobileNet, và cả inference trong trình duyệt qua WebAssembly.
Việc chuẩn hóa này đóng vai trò như một “intermediate representation”, giúp giảm đáng kể chi phí tích hợp, đặc biệt trong môi trường doanh nghiệp cần độ ổn định cao và hỗ trợ đa hệ thống.
Các mô hình tiêu biểu trong giai đoạn này:
- BERT (Google, 2018): huấn luyện ban đầu bằng TensorFlow, sau đó được chuyển đổi sang ONNX để phục vụ triển khai rộng rãi.
- ResNet, YOLOv3, MobileNet: thường được chuyển đổi sang ONNX để triển khai trên edge devices hoặc production server.
Hạn chế tồn tại
Dù ONNX tạo ra bước đệm quan trọng hướng tới mô hình độc lập framework, nhưng vẫn chưa giải quyết triệt để bài toán scale inference khi các mô hình bắt đầu phình to về tham số và tài nguyên yêu cầu. ONNX còn thiếu hỗ trợ tối ưu cho các mô hình có kiến trúc phức tạp hoặc quy mô lớn, như hệ attention đa tầng hay mô hình phân nhánh (ví dụ MoE), khiến quá trình chuyển đổi và triển khai gặp nhiều giới hạn. Đồng thời, các mô hình NLP giai đoạn này vẫn còn giới hạn về khả năng biểu đạt ngữ nghĩa, chưa thể xử lý tác vụ ngôn ngữ phức tạp hay sinh ngữ cảnh như các LLM hiện đại.
Mặc dù các định dạng này ban đầu phục vụ cho mô hình thị giác máy tính hoặc nhận diện giọng nói, chúng cũng là bước đệm dẫn tới sự phát triển định dạng cho LLM sau này.
2. Giai đoạn bùng nổ & lượng tử hóa mô hình (2020 - 2022): Thu nhỏ mô hình, đưa AI về máy cá nhân
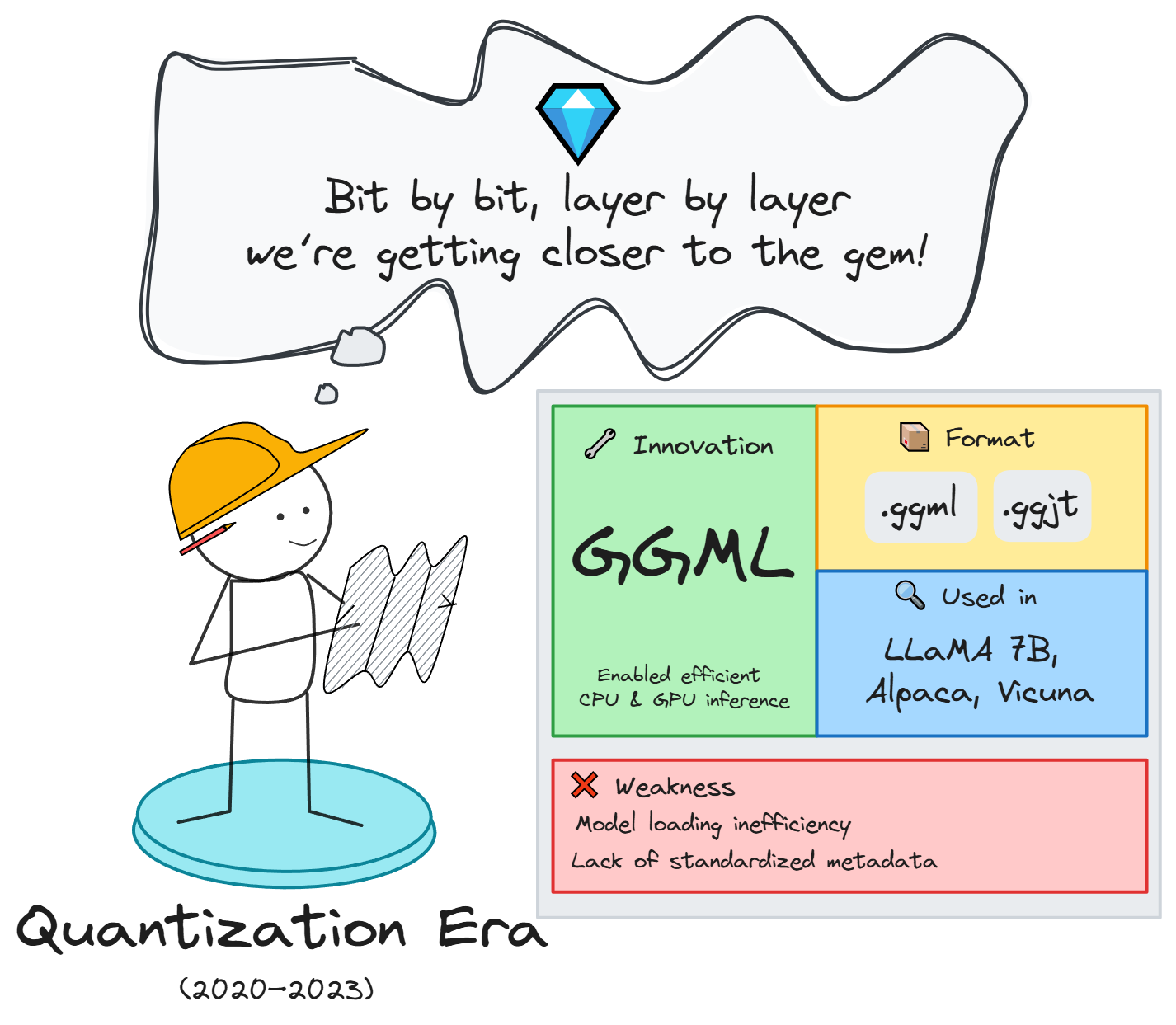
Từ năm 2020, các mô hình ngôn ngữ lớn bắt đầu bùng nổ với sự ra đời của các kiến trúc có hàng chục, thậm chí hàng trăm tỷ tham số như GPT-3 (OpenAI), T5 (Google), hay RoBERTa (Meta). Các mô hình này cho thấy khả năng sinh ngữ cảnh vượt trội, xử lý tốt nhiều tác vụ NLP mà không cần huấn luyện lại (zero-shot, few-shot), tạo ra bước nhảy lớn về hiệu quả và ứng dụng.
Bước ngoặt công nghệ: ChatGPT và làn sóng mã nguồn mở
Cột mốc quan trọng vào cuối năm 2022 là sự ra mắt của ChatGPT, chatbot thương mại đầu tiên xây dựng trên nền GPT-3.5, cung cấp trải nghiệm hội thoại tự nhiên thông qua trình duyệt web. Dù không phải là một cải tiến mô hình về mặt kiến trúc, ChatGPT đã tạo làn sóng lớn khi:
- Tái định nghĩa cách người dùng tương tác với AI, chuyển từ lập trình API sang đối thoại trực tiếp.
- Đơn giản hóa giao diện người dùng, khiến AI trở nên thân thiện và dễ tiếp cận hơn bao giờ hết.
- Tạo ra nhu cầu bùng nổ LLM 'dễ dùng', thúc đẩy xu hướng phổ cập AI.
Song song đó, cộng đồng mã nguồn mở cũng khởi động các nỗ lực xây dựng mô hình thay thế là những phiên bản LLM nhẹ hơn như GPT-J, GPT-Neo, GPT-NeoX.
Tuy nhiên, điểm nghẽn lớn nhất là kích thước mô hình quá khổ, đòi hỏi phần cứng đắt đỏ và chỉ có thể inference hiệu quả trên cloud, dẫn đến chi phí cao, độ trễ lớn và lo ngại về quyền riêng tư.
Để giải quyết điều này, cộng đồng mã nguồn mở đã nhanh chóng đẩy mạnh các kỹ thuật quantization nhằm giảm độ chính xác số học của trọng số để thu nhỏ kích thước mà vẫn giữ được chất lượng đầu ra. Với các công cụ như llama.cpp, mô hình LLaMA có thể được lượng tử hóa xuống 4-bit hoặc 8-bit, chạy trực tiếp trên CPU hoặc laptop mà không cần GPU.
Model Quantization
Model Quantization là kỹ thuật nén mô hình bằng cách giảm độ chính xác số học của trọng số (weights) từ 32-bit float (FP32) xuống 16-bit, 8-bit, 4-bit, thậm chí 2-bit.
Mục tiêu là giữ chất lượng đầu ra gần như nguyên vẹn, trong khi giảm kích thước mô hình và giảm tải bộ nhớ khi inference. Ví dụ đơn giản:
Nếu mô hình gốc dùng 32-bit để lưu 1 trọng số, chuyển sang 4-bit tức là giảm kích thước xuống 1/8 lần – thay vì cần 30GB VRAM, bạn chỉ cần ~4GB RAM.
Đột phá cộng đồng: llama.cpp, GGML và các định dạng quantization đầu tiên
Khi Meta công bố LLaMA vào tháng 3/2023 (dưới dạng checkpoint nghiên cứu, không có API), dự án llama.cpp nhanh chóng ra đời, kết hợp với thư viện GGML để cung cấp nền tảng kỹ thuật cho các định dạng quantization như .ggml.q4_0, .ggml.q8_0.
Đây là cột mốc đột phá vì mô hình LLaMA chạy trực tiếp trên CPU, hỗ trợ quantization tốc độ cao và tối ưu bộ nhớ. Đồng thời nó cũng tương thích với các dự án như koboldcpp, Open WebUI, text-generation-webui.
Điều này mở đường cho việc chạy LLM ngay trên máy cá nhân, thúc đẩy phong trào 'bring-your-own-LLM'.
3. Giai đoạn chuẩn hóa (2023 - 2024): Định dạng GGUF thống nhất cho kỷ nguyên Local AI
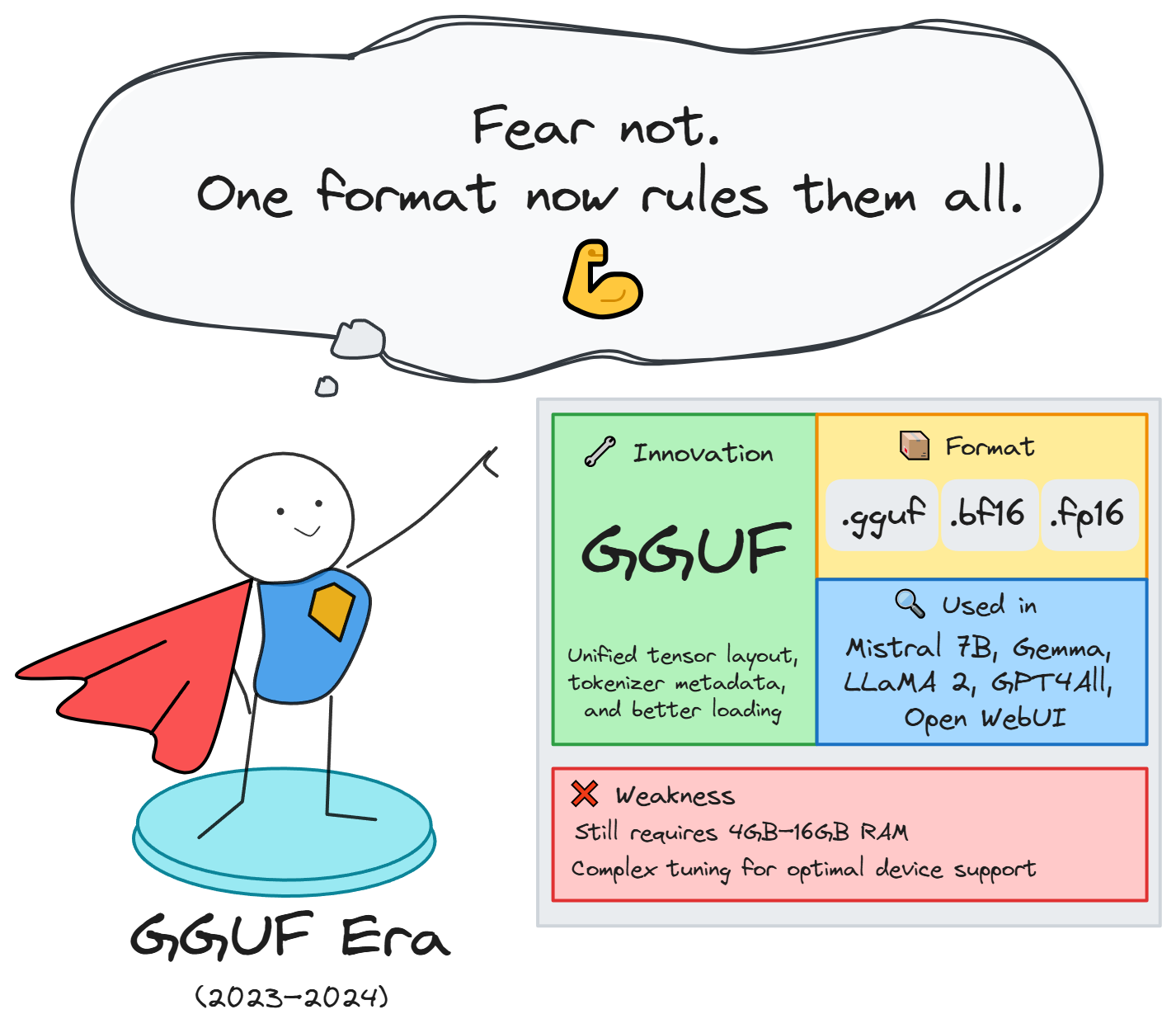
Sau làn sóng model quantization, cộng đồng nhanh chóng nhận ra một điểm nghẽn mới, đó là thiếu tiêu chuẩn định dạng thống nhất. Các định dạng như .ggml, .ggjt tuy hỗ trợ quantization hiệu quả nhưng lại không tích hợp metadata quan trọng như tokenizer, hyperparameter, cấu trúc kiến trúc khiến việc triển khai mô hình yêu cầu thao tác thủ công và dễ lỗi.
Đây chính là thời điểm định dạng GGUF (Ggerganov’s General Unified Format) được cộng đồng llama.cpp đề xuất để giải quyết triệt để bài toán đóng gói mô hình và tối ưu hóa inference đa nền tảng.
Triết lý của GGUF
GGUF ra đời với triết lý:
Tất cả những gì cần để chạy mô hình phải nằm trong một file duy nhất.
Trước khi GGUF xuất hiện, mỗi mô hình thường cần:
- Một file trọng số (
.ggml,.bin, hoặc.pt) - Một loạt file cấu hình đi kèm:
tokenizer.model,config.json,params.yaml... - Một số mô hình còn yêu cầu script riêng để khởi tạo kiến trúc (ví dụ: RoPE, ALiBi…)
Sự phân tán này khiến việc deploy mô hình không nhất quán, khó tái sử dụng, kém thân thiện với người dùng không chuyên.
GGUF là một trong những cột mốc kỹ thuật quan trọng nhất kể từ thời ONNX, giúp chuẩn hóa toàn bộ quá trình chia sẻ và chạy mô hình trong thời kỳ Local AI. Nhờ sự đơn giản, mở rộng linh hoạt và tương thích đa nền tảng, GGUF hiện đã trở thành định dạng mặc định cho cộng đồng sử dụng model quantization, đặc biệt là khi triển khai trên laptop, máy bàn hoặc thiết bị edge.
Đặc điểm kỹ thuật nổi bật
| Tính năng | Mô tả |
|---|---|
| Định dạng nhị phân có cấu trúc | Dễ truy cập, phân tích và mở rộng |
| Tích hợp metadata đầy đủ | Bao gồm: context length, vocab, tokenizer, quantization, kiến trúc attention, prompt format |
| Hỗ trợ model quantization | Tương thích với .Q2_K, .Q4_K_M, .FP16, .BF16... |
| Đa nền tảng inference | Dùng tốt với llama.cpp, KoboldCPP, LM Studio, Open WebUI, text-generation-webui |
| Dễ chia sẻ, dễ deploy | Chỉ cần một file .gguf, không cần bất kỳ file kèm theo nào |
Ứng dụng thực tiễn
- LM Studio: IDE chạy LLM trên macOS/Windows, hỗ trợ kéo thả file
.gguf, chọn mô hình và chạy ngay trên CPU/GPU. - Open WebUI: frontend trực quan cho inference mô hình GGUF, được cộng đồng sử dụng thay cho GPT API.
- KoboldCPP: một trong những backend inference nhanh nhất cho GGUF, dùng nhiều trong ứng dụng roleplay, game AI.
- Hugging Face Spaces: hỗ trợ hiển thị mô hình
.gguftrên nền web, tải quantized model chỉ với một dòng lệnh.
Mô hình tiêu biểu chạy GGUF
- Mistral 7B/Mixtral: tốc độ cao, có thể dễ dàng quantization, dùng phổ biến trong local app
- Phi-2, Gemma, TinyLLaMA: từ Microsoft, Google, cộng đồng mã nguồn mở
- LLaMA 2, GPT4All, OpenHermes: nhiều bản fine-tune đa nhiệm, hỗ trợ tốt trong edge inference
Tuy nhiên, GGUF vẫn yêu cầu tải toàn bộ mô hình vào RAM, chưa hỗ trợ streaming weights.Một số tính năng inference nâng cao (Mixture-of-Experts, RAG tích hợp) vẫn đang được cộng đồng tích hợp dần. Ngoài ra, với GPU chuyên dụng, định dạng như TensorRT engine vẫn có lợi thế hiệu suất cao hơn trong môi trường cloud.
4. Giai đoạn AI thích ứng (2024 trở đi): Định dạng LLM thích ứng theo thiết bị và môi trường
Sau khi định dạng GGUF mở đường cho việc chạy LLM trên máy cá nhân, cộng đồng AI tiếp tục đối mặt với bài toán mở rộng: Làm sao để chạy AI ở khắp nơi mà vẫn đảm bảo hiệu năng real-time, chi phí thấp và năng lượng tối ưu?
Giải pháp không còn chỉ nằm ở việc nén mô hình mà đòi hỏi cả sự tiến hóa trong định dạng, hạ tầng phần cứng và cơ chế triển khai (deployment runtime).
Định dạng mô hình thế hệ mới - thích ứng theo ngữ cảnh & phần cứng
| Định dạng mới | Mục tiêu | Mô tả ngắn |
|---|---|---|
.gguf+stream | Streaming inference | Mở rộng GGUF để chỉ nạp một phần trọng số vào RAM khi cần, giảm TTFB, tối ưu thiết bị yếu |
.q2k (2-bit quantization) | Siêu nén | Định dạng thử nghiệm lưu mô hình 7B chỉ ~1.5GB; yêu cầu kỹ thuật inference đặc biệt |
.npu | Tối ưu NPU | Gói nhị phân chuyên biệt, giúp mô hình inference trực tiếp trên chip AI (Apple Neural Engine, Qualcomm AI, Intel AI Boost) |
safetensors-next | Bảo mật & hiệu suất | Tiếp nối safetensors, hỗ trợ chunked loading, ký số nội dung (digital signature), và chia tensor thành block để tối ưu truyền tải |
| ONNX v2 | Hạ tầng công nghiệp | Cải tiến graph transformer, hỗ trợ sparse tensor, cấu trúc MoE, INT4/INT2; hướng tới inference trên server lớn và cloud |
Kỹ thuật quantization và triển khai tối ưu đi kèm
| Kỹ thuật | Mục tiêu | Điểm nổi bật |
|---|---|---|
| 2-bit/3-bit Quantization | Tối đa hóa độ nén | Duy trì ~95% chất lượng FP16, giảm dung lượng xuống mức sub-2GB |
| AWQ (Activation-aware Quantization) | Giảm lỗi quantization | Dựa theo phân bố kích hoạt thay vì chỉ theo ma trận trọng số → kết quả ổn định hơn |
| MoE v2 (Mixture-of-Experts Router) | Scale lớn, chi phí thấp | Chỉ kích hoạt 1 phần 'expert' cho mỗi token → inference nhanh, tiết kiệm RAM |
| Streaming Weights | Inference theo nhu cầu | Trọng số tải theo dòng, có thể host mô hình lớn trên ổ cứng nhưng chỉ dùng phần cần thiết |
| Edge Transformers | Tối ưu phần cứng giới hạn | Các kiến trúc nhỏ gọn như TinyLLaMA, MobileViT-LLM chạy tốt trên ARM, RISC-V, hoặc Microcontroller (MCU) |
Hệ sinh thái mở rộng theo chiều ngang
- Apple CoreML +
.npu: Apple mở rộngcoremltoolsđể import.ggufhoặc.onnxvà biên dịch sang định dạng chạy trên Apple Neural Engine. - Qualcomm + Edge AI SDK: tích hợp hỗ trợ định dạng
.npuhoặc ONNX INT4 để chạy trực tiếp trên chip Snapdragon AI. - Federated LoRA (n-device fine-tuning): cập nhật mô hình phân tán trên nhiều thiết bị (người dùng tự fine-tune trên điện thoại).
Triển khai thông minh theo ngữ cảnh
Sự kết hợp giữa .gguf+stream và RAG 2.0 (streaming retrieval) tạo nên mô hình inference nhẹ với khả năng 'gọi kiến thức khi cần':
Mô hình được cài đặt local nhưng chỉ xử lý ngữ cảnh hiện tại - phần kiến thức bổ sung bên ngoài (retrieval layer) được gọi theo yêu cầu → giảm tải mô hình chính, tăng khả năng mở rộng.
Kỷ nguyên mới của định dạng mô hình LLM không còn đặt mục tiêu xây dựng một định dạng phổ quát cho mọi trường hợp, mà đã hướng đến khả năng thích ứng tối đa với từng hoàn cảnh sử dụng, từ loại thiết bị, giới hạn phần cứng, cho đến mô hình triển khai cụ thể. Các định dạng hiện đại không chỉ cần nhẹ, nhanh mà còn phải thông minh trong cách nạp dữ liệu, tổ chức metadata và hỗ trợ phân tán.
Sự tiến hóa của định dạng mô hình là một vòng tuần hoàn giữa nhu cầu thực tiễn và đổi mới kỹ thuật, mở ra không gian triển khai AI ngày càng rộng, là chìa khóa để AI thực sự phổ cập theo cách thông minh hơn, gần gũi hơn và có mặt ở khắp mọi nơi.

