Offline PDF Compression với WebAssembly
Bài viết này chia sẻ trải nghiệm cá nhân khi xây dựng tính năng PDF compression viết bằng Python chạy ngay trên trình duyệt với WebAssembly.

PDF compression (nén PDF) là một tính năng phổ biến và có rất nhiều công cụ để hỗ trợ chuyển đổi. Tuy nhiên, phần lớn các công cụ hiện nay đều được xử lý thông qua hệ thống ở phía sau, dẫn đến việc tốn kém chi phí và gây ra sự lo ngại về tính bảo mật từ phía người dùng. Vì thế, việc thực thi PDF compression ngay trên máy của người dùng là một nhu cầu tất yếu khi có thể giải quyết cả hai vấn đề trên.
Có rất ít thư viện mã nguồn mở để xử lý PDF trên trình duyệt, điển hình như pdfjs và pdf-lib. Tuy nhiên, các thư viện này đều chỉ phục vụ mục đích hiển thị và thực thi các tác vụ đơn giản trên PDF nên việc thực thi PDF compression rất khó khăn và phức tạp do phải tự xử lý từng object và cập nhật chúng vào lại PDF.
Ngược lại, ngôn ngữ backend có rất nhiều thư viện hỗ trợ PDF compression ở nhiều ngôn ngữ khác nhau cho chúng ta lựa chọn, điển hình là pypdf được viết bằng Python. Cùng với sự hỗ trợ của Pyodide – một trình biên dịch và thực thi Python được xây dựng dưới dạng WebAssembly, việc sử dụng thư viện này cho tác vụ PDF compression ngay trên trình duyệt là hoàn toàn khả thi.
Trong bài viết này, hãy cùng nhau xây dựng một trang web đơn giản như dưới đây để thực thi tác vụ PDF compression, đồng thời phân tích những điểm mạnh và hạn chế của phương pháp này nhé.

Hình ảnh trang web sau khi hoàn thiện
Thực thi PDF Compression trên trình duyệt
Phần giao diện sẽ được xây dựng dưới dạng trang web thuần và dùng Tailwind CSS cho phần trình bày. Ta sẽ khởi tạo file index.html với nội dung như bên dưới. Phần script để chạy Pyodide sẽ được tải từ CDN.
<!DOCTYPE html>
<html>
<head>
<title>PDF Compression Demo</title>
<script src="https://cdn.tailwindcss.com"></script>
<script src="https://cdn.jsdelivr.net/pyodide/v0.26.4/full/pyodide.js"></script>
</head>
<body>
<div class="container mx-auto p-4 flex flex-col max-w-[500px]">
<div class="flex"><span class="text-2xl font-bold">PDF Compression</span></div>
<!-- File input -->
<div class="flex items-center justify-center w-full mt-4">
<label for="dropzone-file" class="flex flex-col items-center justify-center w-full h-64 border-2 border-gray-300 border-dashed rounded-lg cursor-pointer bg-gray-50">
<div class="flex flex-col items-center justify-center pt-5 pb-6">
<p class="mb-2 text-sm text-gray-500"><span class="font-semibold">Click to add PDF</span></p>
</div>
<input id="dropzone-file" type="file" accept="application/pdf" class="hidden" />
</label>
</div>
<!-- Compress -->
<div id="file-info" class="hidden flex flex-col w-full mt-4 gap-2">
<div class="text-lg">
<div><span class="font-semibold pr-2">File name:</span><span id="file-info-name">ABC</span></div>
<div><span class="font-semibold pr-2">File size:</span><span id="file-info-size"></span><span id="file-info-output-size"></span></div>
</div>
<div class="flex items-center justify-center">
<button id="compress-btn" type="button" class="w-32 text-white bg-blue-700 hover:bg-blue-800 focus:ring-2 focus:ring-blue-300 font-medium rounded-lg text-sm px-5 py-2.5 me-2">Compress</button>
<button
id="compress-btn-loading" disabled type="button" class="hidden flex items-center justify-center w-32 py-2.5 px-5 text-sm font-medium text-gray-900 bg-white rounded-lg border border-gray-200 hover:bg-gray-100 hover:text-blue-700 focus:z-10 inline-flex items-center">
Loading...
</button>
<button id="compress-btn-download" type="button" class="hidden w-32 text-white bg-green-500 hover:bg-green-600 focus:ring-2 focus:ring-green-200 font-medium rounded-lg text-sm px-5 py-2.5 me-2">
Save
</button>
</div>
</div>
</div>
</body>
<script src="/util.js"></script>
<script src="/index.js"></script>
<script>initEvents()</script>
</html>
Sau đó, ta tiến hành tạo logic cho việc lấy file PDF từ HTML input như sau:
...
const initEvents = (_) => {
// Tạo sự kiện để lấy file từ input field
elementDict.fileInput.addEventListener("change", async (event) => {
const file = event.target.files[0];
if (file) {
// Đọc file và lưu dưới dạng buffer
const objURL = window.URL.createObjectURL(file);
pdfContent = await fetch(objURL).then((res) => res.arrayBuffer());
}
elementDict.fileInput.value = "";
});
};
...
Tiếp theo, ta sẽ khởi tạo Pyodide instance thông qua hàm loadPyodide() và sau đó là tải và nạp các thư viện cần thiết thông qua micropip. Hai thư viện cần thiết là pypdf và pillow - thư viện mà pypdf cần để xử lý hình ảnh trong PDF. Cả hai đều có sẵn trong danh sách thư viện hỗ trợ nên chúng ta chỉ việc import và sử dụng bằng các dòng lệnh sau:
// Khởi tạo Pyodide instance
pyodide = await loadPyodide();
// Load micropip package, mặc định sẽ lấy từ bộ thư viện có sẵn qua CDN
// Nếu muốn sử dụng thư viện riêng, ta có thể truyền vào đường link tới file wheel thay vì tên package
await pyodide.loadPackage("micropip");
// Sau đó, ta dùng micropip để tải các thư viện cần thiết
await pyodide.runPythonAsync(`
import micropip
await micropip.install('pillow')
await micropip.install('pypdf')
#... others imports
`);
};
Sau khi đã khởi tạo Pyodide instance với các thư viện cần thiết, ta tiến hành nạp file PDF vào và lấy phần kết quả ra từ Pyodide instance.
// Chuyển đổi PDF content thành biến trong Python qua hàm toPy()
// Sau đó đưa vào trong Pyodide instance qua hàm globals.set()
const pdfBytesPython = pyodide.toPy(pdfContent);
pyodide.globals.set("pdf_in", pdfBytesPython);
// Tiếp theo là phần xử lý PDF compression
await pyodide.runPythonAsync(`
# Xử lý tác vụ PDF compression với "pdf_in" là file đầu vào
....
# Sau khi xử lý, ta khởi tạo biến "pdf_out" để có thể truy xuất từ phía JavaScript
pdf_out = response_bytes_stream.getvalue()
`);
// Tiến hành lấy PDF đầu ra thông qua hàm globals.get(...).toJS()
compressedPdfContent = pyodide.globals.get("pdf_out").toJs();
// Sau đó, ta có thể tải về dưới dạng download file với compressedPdfContent là file content
downloadPDF(compressedPdfContent, fileName);
Tiếp theo là phần logic để thực thi PDF compression bằng pypdf với các tác vụ: Loại bỏ các thành phần trùng lặp, giảm dung lượng ảnh và nén nội dung file. Chi tiết cách làm được miêu tả rất chi tiết tại trang hướng dẫn của thư viện. Dưới đây là logic code cho PDF compression:
# Chuyển đổi pdf_in buffer thành stream để nạp vào PdfWriter của pypdf
pdf_stream = BytesIO(pdf_in)
writer = PdfWriter(pdf_stream)
# Tiếp theo, xoá các object trùng lặp hoặc dư thừa qua hàm compress_identical_objects()
writer.compress_identical_objects(remove_identicals=True, remove_orphans=True)
# Sau đó ta tiến hành xử lý từng trang để giảm dung lượng ảnh và nén content streams trong trang
for page in writer.pages:
for img in page.images:
try:
img.replace(img.image.reduce(2), quality=80, optimize=True)
except Exception as e:
print(e)
page.compress_content_streams()
# Sau khi đã xử lý, ta sẽ tạo ra pdf_out để có thế truy cập từ JavaScript
response_bytes_stream = io.BytesIO()
writer.write(response_bytes_stream)
pdf_out = response_bytes_stream.getvalue()
Và đó là toàn bộ quá trình xử lý PDF compression trên trình duyệt với sự hỗ trợ của Pyodide. Kết quả cuối cùng ta được trang trình duyệt như đã đề cập ở đầu bài viết.
Ưu điểm
Việc thực thi PDF compression trên trình duyệt trở nên khả thi và đơn giản
So với việc phải tự hiện thực tính năng do thiếu các thư viện cần thiết, việc có thể tận dụng bộ thư viện pypdf để xử lý tác vụ PDF compression giúp quá trình phát triển công cụ này trở nên đơn giản và dễ dàng hơn bao giờ hết.
Dễ dàng sử dụng
Ngoài thực thi Python code, Pyodide cũng hỗ trợ rất tốt trong việc tương tác với client code khi ta có thể truyền và nhận dữ liệu từ Pyodide instance một cách dễ dàng như đã thấy trong demo. Pyodide xây dựng và hỗ trợ rất nhiều thư viện phổ biến để người dùng có thể tải và sử dụng. Ngoài ra, ta cũng có thể dùng các thư viện chưa có sẵn bằng cách nạp thư viện dưới dạng Python wheels.
Hạn chế
Quá trình tải tài nguyên cần thiết khá lâu
Tổng thời gian cần thiết để tải tài nguyên cho cả Pyodide và các thư viện đi kèm vào khoảng hơn 10 giây. Điều này có thể làm giảm trải nghiệm của người dùng ở lần chạy đầu tiên. Tuy nhiên, các lần chạy sau sẽ nhanh hơn nhờ cơ chế file caching của trình duyệt.
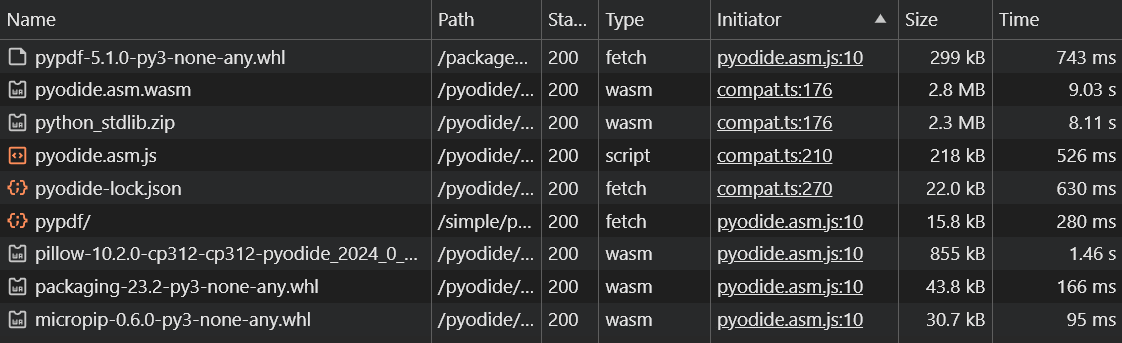
Các file tài nguyên cần tải để sử dụng
WebAssembly vẫn còn khá khó dùng
Việc quyết định sử dụng WebAssembly phụ thuộc khá nhiều vào nhu cầu cụ thể của từng dự án. Trong phần demo trên, việc thực thi code Python khá đơn giản do Pyodide đã hỗ trợ sẵn các thư viện cần thiết. Còn trong trường hợp các bộ thư viện cần thiết không có sẵn, mặc dù Pyodide có hỗ trợ nạp thư viện từ Python wheels file, nhưng file thư viện phải được xây dựng riêng cho WebAssembly runtime hoặc là thư viện thuần mà không phụ thuộc vào hệ điều hành.
Ngoài ra, việc thực thi Python code thông qua Pyodide sẽ không thể nhanh bằng việc xây dựng và chạy trực tiếp WebAssembly. Với ngôn ngữ Python, py2wasm là công cụ để chuyển đổi code sang WebAssembly, hỗ trợ cả Window và MacOS. Mặc dù việc tự xây dựng và tích hợp WebAssembly vào trình duyệt còn tương đối phức tạp, nhưng phần hiệu năng đạt được rất đáng để đầu tư.
Một lưu ý khác là hiện WebAssembly runtime hạn chế dung lượng bộ nhớ tối đa ở mức 4GB nên chúng ta cần kiểm tra kĩ để tránh việc tràn bộ nhớ khi xử lý.
Kết luận
Tóm lại, dù vẫn còn vài hạn chế, WebAssembly vẫn là một công nghệ rất tiềm năng và đáng để thử khi có thể xoá bỏ ranh giới giữa frontend và backend, giúp tăng hiệu năng xử lý, tiết kiệm chi phí và tăng độ bảo mật ở phía người dùng.

