WebLLM: Sử dụng LLM trực tiếp ngay trên trình duyệt
Việc trải nghiệm mô hình ngôn ngữ lớn (LLM) trực tiếp trên trình duyệt mà không cần phải sử dụng LLM server đã trở nên khả thi với WebLLM nhờ vào sự hỗ trợ mạnh mẽ của các trình duyệt hiện nay.

Với các tính năng tuyệt vời như tra cứu, tóm tắt hay sáng tạo nội dung, LLM (Large Language Model) đang dần trở thành một phần không thể thiếu trong cuộc sống của chúng ta. Tuy nhiên, việc vận hành LLM tiêu tốn rất nhiều tài nguyên của máy, khiến chi phí cho việc sử dụng thông qua API trở nên đắt đỏ. Bên cạnh đó, việc sử dụng LLM API đem lại sự lo ngại về tính bảo mật cho người dùng khi xử lý các thông tin quan trọng. Việc tự host và sử dụng LLM trên máy cá nhân cũng tương đối phức tạp với người dùng không làm trong lĩnh vực phần mềm.
WebLLM là một công cụ tiềm năng để giải quyết các vấn đề trên khi có thể đẩy tải về phía người dùng, đồng thời đảm bảo tính bảo mật khi việc xử lý tài liệu diễn ra hoàn toàn trên trình duyệt. Việc phát triển ứng dụng web cũng khá đơn giản khi WebLLM có cách hiện thực đơn giản, hỗ trợ sẵn nhiều loại LLMs và cho phép ta sử dụng custom model.
Trong bài viết này, chúng ta sẽ cùng tìm hiểu về cách thức vận hành, ưu điểm, hạn chế và các lưu ý khi sử dụng WebLLM.
Các thuộc tính của WebLLM
Chạy hoàn toàn trên trình duyệt
Đúng với tên gọi của nó, WebLLM được thực thi hoàn toàn bằng trên trình duyệt mà không cần sự hỗ trợ của server. Để có thể chạy hoàn toàn trên trình duyệt mà vẫn đảm bảo được vấn đề hiệu suất, WebLLM đã khai thác sức mạnh của WebAssembly cho việc thực thi LLM trong ứng dụng web. Bên cạnh đó, phần engine để thực thi LLM được chạy hoàn toàn trên WebGPU - một API cho phép ta sử dụng GPU của máy để tính toán, giúp hiệu năng thực thi LLM trên môi trường trình duyệt không khác gì thực thi trực tiếp trên local.
Chúng ta có thể trải nghiệm WebLLM thông qua chat demo trong trang chủ WebLLM.
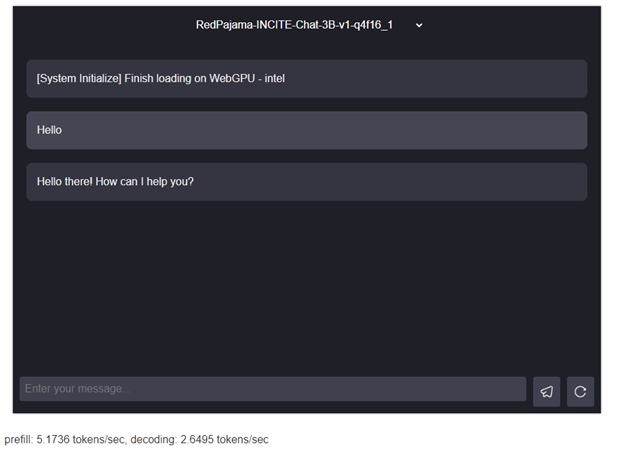
Tương thích hoàn toàn với OpenAI
WebLLM được thiết kế để tương thích hoàn hoàn với API của OpenAI, giúp chúng ta có thể sử dụng nhiều loại model và tận dụng được hầu hết các tính năng như streaming, json-mode, function-calling hay seeding. WebLLM cũng dựng sẵn nhiều project mẫu để chúng ta có thể tham khảo, từ các tác vụ đơn giản cho tới phức tạp như phần chat demo ở trang chính. Hỗ trợ sẵn nhiều loại model
WebLLM đã xây dựng sẵn các bộ thư viện để sử dụng nhiều loại open-source model như Llama, Gemma, Mistral hay Phi, với nhiều lượng tham số khác nhau để chúng ta có thể sử dụng ngay mà không cần phải xây dựng từ đầu.
Sau đây là một số model được tích hợp sẵn, model với hậu tố ‘1k’ ở cuối sẽ giới hạn tối đa 1024 tokens, giúp giảm lượng VRAM cần thiết để thực thi model.
| Model | Parameters | VRAM Required |
|---|---|---|
| Llama-3-70B | 70B | ~31GB |
| Llama-3-8B | 8B | ~6.1GB |
| Llama-3-8B -1k | 8B | ~5.2GB |
| Llama-2-7B | 7B | ~6.7GB |
| Llama-2-7B-1k | 7B | ~4.6GB |
| Mistral-7B | 7B | ~6GB |
| RedPajama-3B | 3B | ~2.9GB |
| Gemma-2B | 2B | ~1.5GB |
| Phi2 | 2.7B | ~11GB |
| Phi1.5 | 1.3B | ~5.8GB |
Nguồn: Github
Cho phép sử dụng custom model
Ngoài số lượng lớn model đã được WebLLM tích hợp sẵn, WebLLM cũng hỗ trợ cho chúng ta xây dựng và sử dụng custom model để có thể tối ưu model theo tính năng cần thiết.
Nhà phát triển có thể chuyển đổi một model sang hỗ trợ WebLLM tận dụng các thư viện đã được dựng sẵn của WebLLM. Trong trường hợp model không tương thích, WebLLM cũng hỗ trợ viết bộ thư viện riêng cho custom model. Để tìm hiểu sâu hơn, ta có thể xem tại đây.
Dễ dàng tiếp cận và sử dụng
Với việc xây dựng sẵn bộ engine để thực thi LLM hỗ trợ chạy trực tiếp hay trên web worker, việc tích hợp và sử dụng model trở nên cực kì đơn giản khi ta chỉ cần truyền thông số về model và bộ thư viện thực thi tương ứng với nó.
Ngoài ra, từ phiên bản 124 của Chrome, service worker đã hỗ trợ WebGPU, giúp việc chạy và sử dụng LLM trên Chrome extension trở nên khả thi.
Hạn chế và lưu ý khi sử dụng WebLLM
Yêu cầu cấu hình máy tốt
Việc chạy model trên máy cá nhân cần một lượng lớn tài nguyên của máy để vận hành. Nếu chạy một model đòi hỏi cấu hình máy quá lớn sẽ gây ra tình trạng trả kết quả chậm, giật lag và thậm chí treo máy. Sau đây là bảng so sánh khi sử dụng các loại model khác nhau trong cùng một máy, ta có thể thấy số lượng token mỗi giây giảm mạnh khi sử dụng model quá lớn.
Một lưu ý khác là WebGPU sẽ sử dụng GPU mặc định của trình duyệt, nên đối với máy có nhiều GPU, ta phải lựa chọn chính xác GPU mạnh mẽ hơn để thực thi. Như ta thấy trong hình dưới thì WebGPU mặc định sử dụng GPU có sẵn của máy thay vì GPU rời với cấu hình cao hơn, dẫn đến độ trễ không đáng có.
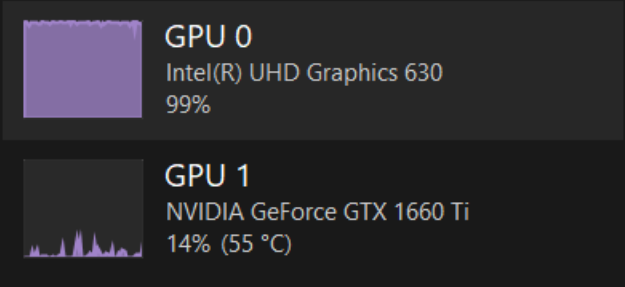
Chrome đang sử dụng GPU mặc định thay vì GPU cấu hình cao hơn
Chọn model phù hợp với cấu hình
Do ta chỉ có thể đo đạc thông số của GPU process trên trình duyệt mà không thể nắm được cấu hình GPU của máy, việc lựa chọn model phù hợp với cấu hình là vấn đề rất khó khăn khi phải lựa chọn độ trễ cho phép và độ chính xác của model. Việc tải hết các model để đo lượng token là một vấn đề bất khả thi và đem lại trải nghiệm rất tệ đối với người dùng.
Một trong những cách để kiểm tra performance của WebGPU là sử dụng phương pháp render nhiều lần thẻ canvas bằng WebGPU để có được thông số FPS, từ đó tiến hành thử nghiệm và lựa chọn model phù hợp với cấu hình. Đọc thêm về cách đo hiệu năng cho WebGPU.
Ngoài ra, để có thể tối ưu độ chính xác mà không làm tăng độ trễ, chúng ta có thể tạo ra các model gọn nhẹ và được train cho mục đích chuyên biệt thay vì dùng các model lớn.
| Model | Parameters | Prefill (tokens/sec) | Decoding (tokens/sec) |
|---|---|---|---|
| Llama-3-8B-1k | 8B | 17.3079 | 7.5919 |
| Llama-3-8B | 8B | 15.0707 | 0.8259 |
| Llama-2-7b-1k | 7B | 13.5834 | 8.606 |
| Llama-2-7b | 7B | 12.085 | 0.4528 |
| Mistral-7b | 7B | 10.7386 | 12.4129 |
| RedPajama-INCITE-Chat-3B | 3B | 26.8007 | 20.9872 |
Trong trường hợp này, GPU được sử dụng là NVIDIA GeForce 1660 Ti – 6GB VRAM
Yêu cầu các phiên bản mới của trình duyệt
WebGPU mới được phát hành trong bản 113 của Chrome và Edge, vẫn còn đang trong giai đoạn thử nghiệm ở Safari và FireFox, WebLLM hiện vẫn đang khá kén người dùng, đội ngũ phát triển cần phải cân nhắc khi triển khai cho tập khách hàng của mình.

Nguồn: Caniuse
Kết luận
WebLLM ra đời đã đem lại lợi ích rất lớn khi giải quyết được vấn đề scaling và tăng độ an toàn tin cậy khi sử dụng LLM ở phía người dùng. Mặc dù vẫn còn một vài hạn chế như thời gian chạy lần đầu khá lâu tùy thuộc tốc độ mạng (model được lưu offline trên lưu trữ của trình duyệt) và yêu cầu cấu hình máy cao để có trải nghiệm tốt nhất, WebLLM vẫn là một hướng đi tiềm năng khi mà phần cứng ngày càng phát triển.

