Vì sao AI tạo ảnh đã giỏi đánh vần hơn xưa?
Từ những mô hình tạo ảnh với khả năng hiển thị chữ cơ bản, hay bị lỗi sai chính tả, các mô hình hiện nay đã cải thiện rất nhiều vấn đề này nhờ vào sự thay đổi của cơ chế tokenizer và text encoder.
.jpg)
Cộng đồng công nghệ những năm gần đây chứng kiến sự phát triển vượt trội và vô cùng nhanh chóng của các mô hình tạo ảnh. Từ những tấm ảnh rất dễ bị lỗi, không quá phức tạp với độ phân giải thấp, giờ đây các mô hình đã có thể tạo ra các hình ảnh tốt hơn, phức tạp hơn với độ phân giải tốt, phục vụ cho nhiều ứng dụng.
Một trong những điểm được cải thiện rất nhiều trong những năm vừa qua là hình ảnh do AI tạo ra dần dần ít sai lỗi chính tả hơn. Chính xác là các model đã có khả năng text rendering (hiển thị chữ trong ảnh) tốt hơn. Những cải thiện này đến từ sự thay đổi của cơ chế tokenizer và text encoder, sẽ được giải thích cụ thể trong bài viết này.

Prompt: Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says "Stable Diffusion 3" made out of colorful energy - SD3
1. Cơ chế tokenizer và năng lực đánh vần
Cũng như cái tên text-to-image, các model hiện nay có thể chia làm hai phần khác nhau: phần xử lý text và phần tạo ảnh.
Trước hết, chúng ta cần biết cách xử lý text của các model hiện nay là đều thông qua một hệ thống tokenization riêng. Tokenizer có nhiều cách chuyển đổi văn bản đầu vào thành dữ diệu số để model có thể xử lý, có thể theo word level, character level hoặc sub-word level. Trong đó, sub-word level hiện là phương pháp hiệu quả nhất và tất cả các model phổ biến đều áp dụng.
Nói một cách đơn giản, các model không xử lý văn bản đầu vào dựa theo các từ (vd: elephants) hay ký tự (vd: e, l, e, p, h, a, n, t, s) mà chia nhỏ các từ theo tổ hợp như ví dụ đơn giản ở hình dưới. Hãy tưởng tượng tới cách chúng ta hay nhìn đuôi "ion" là danh từ, "er" để chỉ người, về cơ bản chính là như vậy.
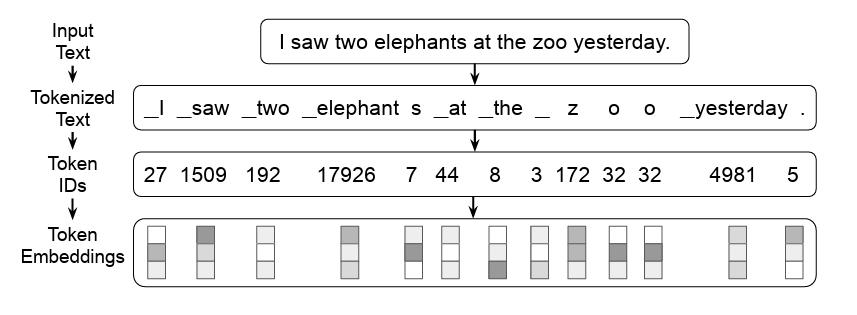
Ví dụ về tokenizer
Do sub-word level tokenizer không chia theo các ký tự, việc "đánh vần" các ký tự để hiển thị trong ảnh là một điều không đơn giản với các model này. Và khi input đã không chính xác, thì làm sao output có thể chính xác được?
Nói thêm về vấn đề này, chúng ta có thể bất ngờ trước việc các LLMs thực hiện các phép + - rất tệ, đó là bởi vì các LLMs cũng không được "nhìn" thấy các chữ số. Trường hợp này có thể liên tưởng tới việc chúng ta thực hiện phép nhân 2 số hệ thập lục phân: 1A * B7, sẽ phức tạp hơn nhiều lần dù bản chất chỉ là phép nhân 26 * 183.
Tuy rằng các model gặp nhiều khó khăn trong việc "đánh vần" nhưng khi chúng ta tăng size của model, khả năng "đánh vần" sẽ được cải thiện rất nhiều. Với những model nhỏ như CLIP (chỉ có vài chục - vài trăm triệu parameters), khả năng "đánh vần" đương nhiên là rất kém, và điều này được cải thiện với các model CLIP size lớn hơn, tới các model vài tỷ parameters như T5 thì khá tốt. Lẽ dĩ nhiên, những model lớn như GPT-4 thì chắc không cần phải kiểm tra.
2. Sự thay đổi trong text encoder của các model

Qua thời gian, các text encoder cũng dần to hơn, và đi cùng là khả năng text rendering được cải thiện rõ rệt.

Prompt: Sprouts in the shape of text 'Imagen' coming out of a fairytale book - Imagen
Vậy tại sao những model ban đầu lại sử dụng CLIP? Bởi vì những model ban đầu có kích thước rất nhỏ, và có lẽ khi đó text rendering cũng không phải là vấn đề cần chú ý. Ví dụ như đối với SD 1.5 chỉ có 860M params tổng cộng, thì rõ ràng dùng 123M param text encoder sẽ hợp lý hơn dùng những text encoder 695M hay vài tỷ param.

Như vậy, sự cải thiện về mặt text rendering trong các model hình ảnh hiện nay chủ yếu bắt nguồn từ việc các model hiện tại đã sử dụng các model text encoder tốt hơn, có khả năng "đánh vần" tốt hơn, từ đó tạo ra các hình ảnh chính xác hơn về mặt các ký tự.
Còn về phía người dùng, có lẽ chúng ta chỉ cần đọc các bài đánh giá trên mạng, xem một vài ảnh mẫu và dùng thử là có cảm nhận riêng, từ đó lựa chọn model phù hợp với nhu cầu cá nhân để sử dụng.
Tham khảo
TextDiffuser: Diffusion Models as Text Painters (arxiv.org)
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis (arxiv.org)
Stable Diffusion 3: Research Paper — Stability AI
EVA-CLIP: Improved Training Techniques for CLIP at Scale (arxiv.org)

