Chẩn đoán Covid-19 qua tiếng ho sử dụng ConvNet và tăng cường dữ liệu
Bằng việc áp dụng phương pháp tăng cường dữ liệu và kiến trúc ConvNet trong nghiên cứu chẩn đoán Covid-19 qua tiếng ho, điểm số AUC trong bộ blind test đạt được 87,07%. Kết quả này đã giúp chúng tôi đứng đầu bảng xếp hạng DiCOVA 2021 Challenge.

Các đặc điểm của tín hiệu âm thanh như tiếng ho, hơi thở hoặc giọng nói có thể được sử dụng để chẩn đoán Covid-19 do mang nhiều thông tin liên quan đến sức khỏe hô hấp.
Cuộc thi DiCOVA 2021 do Viện Khoa học Ấn Độ tổ chức nhằm khuyến khích các nỗ lực nghiên cứu bằng cách sử dụng một tập dữ liệu âm thanh tiếng ho của các đối tượng dương tính và âm tính Covid-19. Những thách thức trong công việc của team chúng tôi là tăng cường dữ liệu âm thanh mất cân bằng giữa các nhãn (label) với các biến đổi phù hợp, chọn một tính năng âm thanh và quyết định kiến trúc mô hình phù hợp.
Phương pháp luận của chúng tôi là tăng cường dữ liệu lớp dương tính bằng cách sử dụng các phép biến đổi khác nhau và sử dụng MFCC của dữ liệu âm thanh làm các tính năng đầu vào cho Mạng nơ-ron (CNN).
Chúng tôi đã đạt được điểm số AUC (area-under-the-curve) là 87,07% trong bộ dữ liệu blind test (tập mù), giành được vị trí đầu tiên của bảng xếp hạng DiCOVA 2021 Challenge.
Bài viết này sẽ mô tả cách sử dụng phương pháp tăng cường dữ liệu và kiến trúc ConvNet trong công trình nghiên cứu chẩn đoán Covid-19 qua tiếng ho.
1. Dữ liệu
Tập dữ liệu được sử dụng cho Track 1 của DiCOVA Challenge là tập con của cơ sở dữ liệu gốc từ dự án Coswara. Nó chứa tổng cộng 1,36 giờ ghi âm tiếng ho từ 75 đối tượng dương tính với COVID-19 và 965 đối tượng âm tính.
Các bản ghi âm tiếng ho của tập dữ liệu có các mẫu âm thanh với thời lượng dao động từ khoảng 0,79 giây đến 14,73 giây.
Ngoài ra, 233 mẫu được lưu giữ như một blind set để kiểm tra khi có kết quả thử nghiệm. Những mẫu này được cung cấp bởi ban tổ chức.
2. Tiền xử lý
Dựa vào một số kết quả nghiên cứu của các nhà khoa học dữ liệu, chúng tôi đã lựa chọn tính năng âm thanh phù hợp như sau:
Hệ số MFCC (Mel frequency cepstral coefficients) có thể trích xuất thông tin quan trọng từ phi tuyến tính và vùng tần số thấp của âm thanh. Tham khảo: “Speech recognition using mfcc” của Ittichaichareon và cộng sự.
Quang phổ mel có thể ghi lại những thay đổi nhỏ ở các vùng tần số thấp hơn. Tham khảo: “A scale for the measurement of the psychological magnitude pitch” của Stevens và cộng sự.
Âm thanh tiếng ho chứa nhiều năng lượng hơn ở tần số thấp hơn. Tham khảo: “Wavelet analysis of voluntary cough sound in patients with respiratory diseases” của Knocikova và cộng sự.
Do đó, MFCC dường như là một tính năng thích hợp để trích xuất và sử dụng từ các âm thanh tiếng ho trong tập dữ liệu.
Như đã đề cập ở phần dữ liệu, các bản ghi âm tiếng ho của tập dữ liệu có thời lượng khoảng từ 0,79 giây đến 14,73 giây. Mỗi mẫu cần có khoảng thời gian không đổi, tương đương với số lượng mẫu cố định.
Trong số 1.280 bản ghi, chúng tôi quan sát thấy bản ghi số 804, 996, 1130 có thời lượng lần lượt ít hơn 5, 6 và 7 giây. Việc chọn thời lượng phù hợp cho tất cả các bản ghi âm là rất quan trọng. Vậy nên chúng tôi chọn 154.350 mẫu, mỗi mẫu dài 7 giây khi lấy 22.050 mẫu/giây.
15 hệ số MFCC đã được chọn cho mỗi khung của mỗi mẫu vì phần cuối của chiều tần số của quang phổ có những thông tin cần thiết cho công việc của chúng tôi như formants, spectral envelope, v.v.
Các mẫu âm thanh dài 7 giây trong ma trận MFCC có kích thước 15x302.
3. Phương pháp
Tăng cường dữ liệu
Tỷ lệ mất cân bằng lớp - 1:12 (Covid dương tính:Covid âm tính khi ho).
Thư viện Audiometations được sử dụng để lấy những mẫu âm thanh tiếng ho dương tính với Covid-19.
Các phương pháp tăng cường dữ liệu từ thư viện đã được sử dụng bao gồm Time Stretch, Pitch Shift, Shift, Trim, Gain.
Tỷ lệ mất cân bằng lớp được cải thiện thành 1:3 (965 âm tính, 315 dương tính)
Mô hình
Việc huấn luyện và đánh giá được áp dụng kỹ thuật Stratified k-fold cross-validation với 5 phần (fold).
Kết quả tỷ lệ học (learning rate) là 0,0001 sử dụng thuật toán Adam optimizer.
Thực hiện chạy batch size gồm 32 mẫu để tối ưu thời gian.
Quá trình huấn luyện mất 200 lần (epoch) mỗi phần.
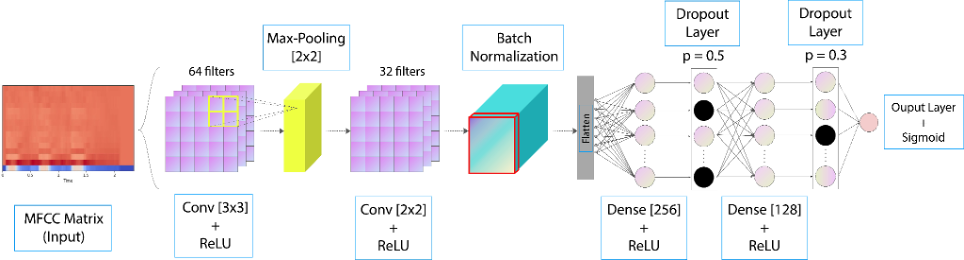
Kiến trúc ConvNet
4. Kết quả đạt được
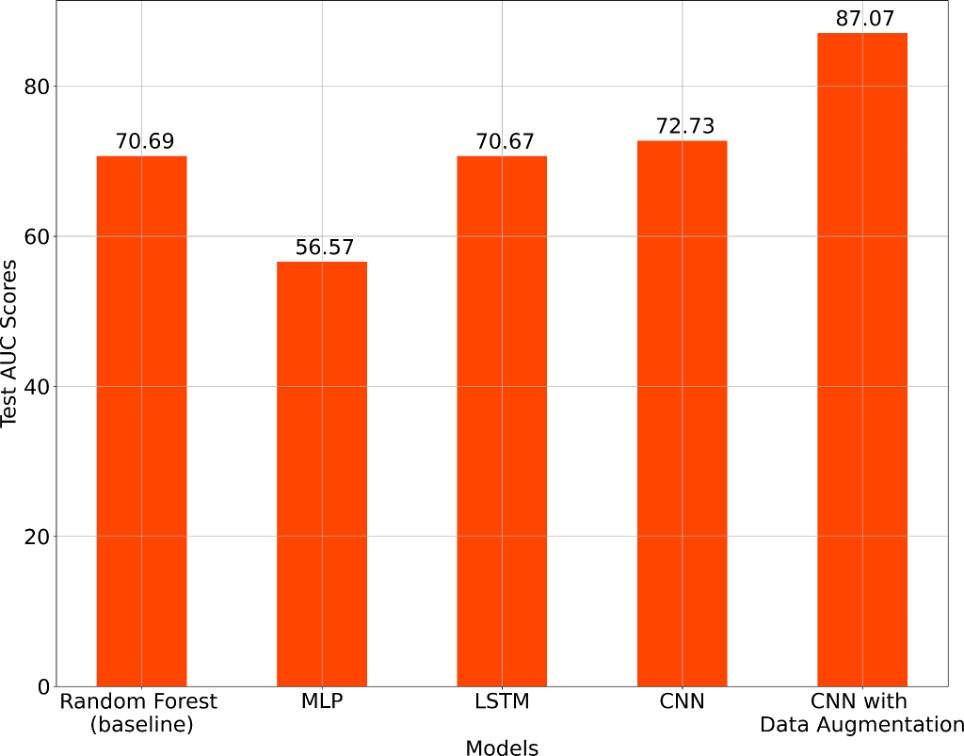
Theo kết quả, trong bốn phương pháp thì mô hình CNN có tăng cường dữ liệu cho ra hiệu suất tốt nhất đối với tiếng ho.
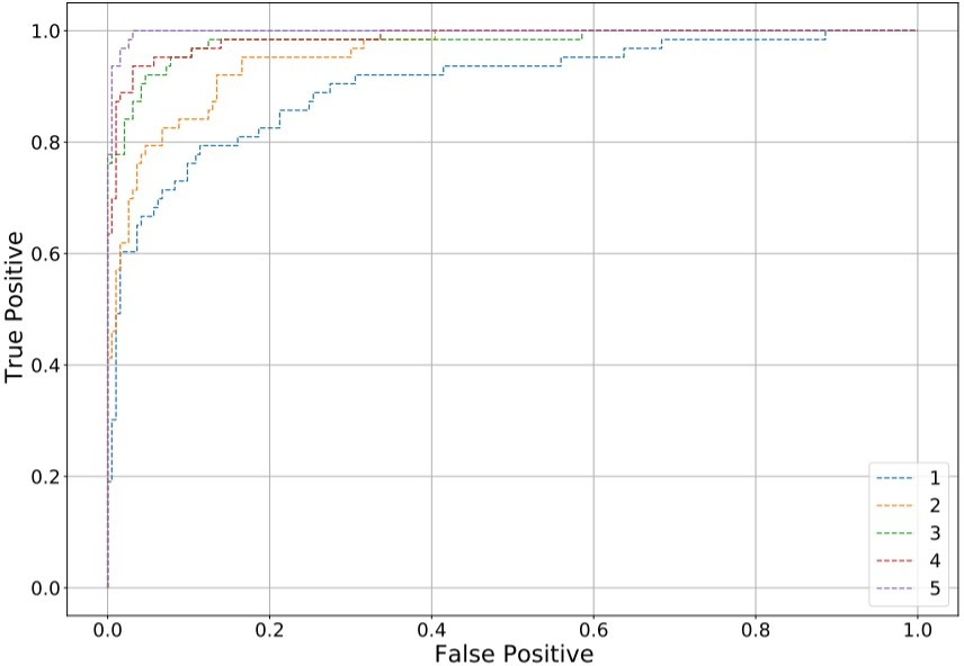
Đường cong ROC (receiver operating characteristic) từ đánh giá của mô hình qua mỗi phần
Độ chính xác xác thực được tính trung bình trong tất cả năm phần cho kết quả là 94,61% với độ lệch chuẩn là 2,62%.
Theo cách tương tự, tỷ lệ điểm ROC-AUC đạt 97,36% trong các phần.

Ma trận Confusion được đánh giá tương ứng với ngưỡng quyết định ở độ nhạy (sensitivity) là 80%.
5. Kết luận
Chỉ với số lượng dữ liệu hạn chế được cung cấp sẵn cùng với một số kỹ thuật tăng cường dữ liệu, đề xuất áp dụng mô hình ConvNet đã cho ra hiệu suất đáng kể trên các dữ liệu chưa từng thấy trước đây.
Điểm Test AUC của công trình nghiên cứu là 87,07 trong bộ blind test, vượt trội hơn 23% so với mô hình của ban tổ chức.
Cuối cùng, kiến trúc mô hình này có thể sử dụng để huấn luyện cho loại cơ sở dữ liệu được cập nhật liên tục. Ngoài ra, nó cũng có thể tích hợp với các ứng dụng web để thúc đẩy quá trình chẩn đoán Covid-19 ngay cả với những người dương tính nhưng không có triệu chứng.
Tham khảo chi tiết tại đây.

