Trình tạo hình ảnh xe máy bằng BiGAN
Trong công trình này, tôi sử dụng BiGAN để tạo các hình ảnh giả trông như thật. Phương thức này không chỉ giúp ổn định quá trình huấn luyện GAN mà còn mang lại những cải thiện đáng kể so với các phương thức GAN tiên tiến khác.

Trong cuộc thi nghiên cứu Motorbike Generator Challenge, tôi thực hiện một công trình sử dụng BiGAN (Bidirectional Generative Adversarial Network - Mạng Sinh Đối kháng Hai chiều) để tạo ra các hình ảnh giả trông như thật cho trình sinh hình ảnh xe gắn máy. Kết quả Motorbike Generator đã cho thấy rằng, phương thức này không chỉ giúp ổn định quá trình huấn luyện GAN, mà còn đem lại những cải thiện đáng kể so với các phương thức GAN tiên tiến khác.
Nghiên cứu này đã đạt được các kết quả chính sau:
- Ứng dụng BiGAN, thực hiện tái cấu trúc và đặc tính hữu ích từ mạng GAN, các kết quả nghiên cứu đạt hiệu quả cao, cạnh tranh với các công nghệ mới nhất trong việc thực hiện sinh ra ảnh xe máy ngẫu nhiên chưa từng có mà trông như thật.
- Cải thiện việc nghiên cứu BiGAN cũng như các phương thức huấn luyện GAN tân tiến khác, sử dụng bộ dữ liệu xe máy kết hợp với một số kỹ thuật như tiền xử lý dữ liệu (preprocessing data), tăng cường dữ liệu (data augmentation), và hiệu chỉnh các siêu tham số (hyper-parameter tuning).
Giới thiệu
Motorbike Generator là việc tạo ra các hình ảnh xe máy giả một cách đa dạng sao cho có thể ứng dụng vào nhiều bài toán như nhận diện và phát hiện xe máy. Điểm mấu chốt để giải quyết bài toán này là tìm được phương pháp tiếp cận phù hợp nhất để đạt được điểm số (score) tốt nhất cho bộ dữ liệu có sẵn. Khi có được phương pháp tiếp cận tốt nhất, chúng ta có thể áp dụng cho nhiều ứng dụng trong thị giác máy tính (computer vision) như: tạo hình ảnh mặt người một cách chân thật (generating realistic human faces), thay đổi nhân vật hoạt hình (cartoon translation), thay đổi khuôn mặt (face swap), tăng cường độ phân giải hình ảnh (image super resolution), tạo ra nhiều bộ dữ liệu mới.
Bộ dữ liệu được sử dụng cho nghiên cứu này tương đối phức tạp và bao gồm nhiều hình ảnh nhiễu như:
- Các hình ảnh có nền là người, cây, tòa nhà, nhân vật
- Các hình ảnh có kích thước khác nhau
- Hai định dạng hình ảnh: PNG, JPEG
Chính bởi độ phức tạp của bộ dữ liệu cùng với các phương pháp tuy mới song lại không thể cho ra kết quả tốt. Do đó, để giữ nhiều thông tin phức tạp cho trình so sánh (discriminator), tôi đã lựa chọn sử dụng phương pháp BiGAN.
Bối cảnh
BiGAN có liên quan tới các mạng mã hóa tự động (autoencoder-AAE), với khả năng mã hóa (encode) các mẫu dữ liệu và dựng lại dữ liệu từ các mã nhúng thu gọn (compact embedding). Donahue cùng các đồng tác giả đã tìm ra một mối liên hệ về mặt toán học giữa hai framework này. Nghiên cứu của Makhzani và các đồng nghiệp cũng đã giới thiệu một biến thể đối kháng của các AAE, với khả năng hạn chế các mã nhúng ngầm (latent embedding) ở định dạng tương tự như simple prior distribution (ví dụ: phân phối Gaussian đa biến). Mô hình của họ bao gồm encoder, decoder và discriminator (cơ chế phân loại). Trong đó, Enc và Dec sẽ được huấn luyện bằng loss function với các mẫu dữ liệu có thật, còn cơ chế phân loại sẽ xác định xem liệu vector ẩn là bắt nguồn từ prior distribution hay từ output distribution của Enc.
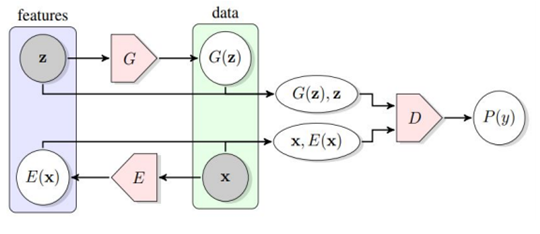
Hình 1: Cấu trúc BiGAN
BiGAN: framework GAN cho phép biểu diễn một biểu đồ (mapping) biểu hiện từ z tới x, song lại không cho phép tạo lập một biểu đồ khác từ x về z. Biểu đồ này rất hữu ích vì nó mang lại một biểu hiện x giàu thông tin, và có thể được sử dụng làm đầu vào cho các downstream task (tác vụ xuôi dòng) như phân loại, thay cho các dữ liệu ban đầu theo một cách vừa đơn giản mà lại vừa hiệu quả. Các nghiên cứu bởi Donahue và Dumoulin cũng đã phát triển ra các mô hình BiGAN (còn ALI) độc lập, được tích hợp thêm một enc vào framework tổng hợp-phân loại ban đầu.
Trong hình 1, các mô hình tổng hợp có biểu đồ tương tự như tổng hợp GAN gốc, còn enc lại là một biểu đồ E(x;θE) từ Pd tới PE sao cho PE cách Pz là nhỏ nhất. Tại đây, cơ chế phân loại sẽ được cải thiện sao cho tích hợp được thêm cả z và G(z), hoặc cả x và E(x) để đưa ra các quyết định thật hoặc giả, mà ở đây lần lượt là D(z, G(z);θD) hoặc D(E(x), x;θD).
Công trình được thực hiện bởi nhóm Donahue lại chứng minh chi tiết rằng trong điều kiện tối ưu sẽ nghịch đảo với nhau, qua đó gây nhầm lẫn ở cơ chế phân loại. Do đó mô hình cần được huấn luyện với mục tiêu minimax được biểu diễn bằng phương trình sau đây:
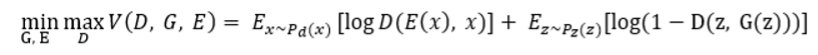
Giải pháp
Nhằm thực hiện unsupervised training các mạng BiGAN, tôi đã sử dụng thuật toán tối ưu Adam để thực hiện cập nhật các tham số theo các hyperparameter (với tốc độ học ban đầu là α=1x10^(-4), động lượng (momentum) là β1=0 và β2=0.909). Ngoài ra, kích thước mini-batch sẽ được đặt tại 32, còn kích thước latent space là 64. Đồng thời, tôi cũng sử dụng ràng buộc Lipschitz sao cho thỏa mãn biến gradient penalty để định vị mục tiêu cho mạng GAN, và sử dụng mô hình Frechet Inception Distance để đo lường đánh giá. Phép mở rộng được mặc định sử dụng là lật hình theo chiều ngang (Flip Horizontal).
Việc lấy trung bình mẫu từ nhiều phân phối khác nhau có thể gây suy giảm chất lượng kết quả. Do đó, tôi đã sử dụng đường trung bình động (Exponential Moving Average - EMA) sau mỗi phép lặp khi t = 10 với tỷ lệ cập nhật là β = 0,999.
Bộ dữ liệu xe máy được sử dụng trong huấn luyện là được thu thập trong chương trình Zalo AI Challenge, bao gồm khoảng 10.000 hình ảnh xe máy, đều được giảm kích thước xuống 128 x 128 chiều.
Một số phương thức mới được phát triển từ GAN tổng hợp hình ảnh mà tôi sẽ thực hiện so sánh là:
- BigGAN – được tạo thành thông qua việc tách latent space thành từng khối nhỏ theo đội phân giải, rồi liên kết mỗi khối với một vector kênh điều kiện (conditional channel vector), mà sau đó sẽ được sử dụng để phản chiếu các độ khuếch (gain) và độ lệch (bias) BatchNorm.
- StyleGAN điều khiển tác vụ chuẩn hóa điểm thích ứng (adaptive instance normalization), đồng thời thêm các ảnh nhiễu vào cơ chế phân loại.
- SAGANs (Self-Attention Generative Adversarial Networks) được tích hợp kỹ thuật self-attention, bộ tổng hợp có thể tạo ra các hình ảnh với chi tiết mượt mà và đồng nhất tại mọi điểm trên ảnh.
Tôi đã sử dụng Frechet Inception distance (FID) (Heusel et al., 2017) làm thang đo ban đầu cho việc đánh giá định lượng, bởi lẽ FID cho kết quả đánh giá giống con người hơn các phương pháp đo độ chính xác khác. Trong FID này cố định α=10^(-15) và ngưỡng cosine distance là 0,05.
Thực hiện so sánh các chênh lệch giữa điểm FID của các mô hình GAN trong Bảng 1 dưới đây. Có thể thấy rằng, phép lật theo chiều ngang đã giúp cải thiện điểm FDI từ 137,5412 thành 136,0553.
Một số phương thức mới như StyleGANvà Alpha GAN lại cho kết quả đánh giá thấp hơn GAN gốc, và do đó không phù hợp để tổng hợp ra các hình ảnh xe máy giả. Trong khi đó, phương thức mới CR-BigBiGAN, dựa trên phép lật theo chiều ngang hoặc phép EMA +∗, lại cho điểm cao hơn. Tương tự, CR-BigBiGAN sử dụng kết hợp hai phép phóng đại trên lại cho số điểm cao hơn CR-BigBiGAN sử dụng độc lập từng phép là khoảng 4 điểm (cụ thể là 28,4417 và 32,6050). Theo cột BiGAN ở bảng dưới đây, ta cũng có thể thấy rằng, phương thức EMA giúp cải thiện hiệu quả đáng kể, trong khi đó phép phóng đại* và việc loại bỏ hình ảnh có người không hề cải thiện điểm. Từ đó có thể kết luận rằng, để cải thiện hiệu quả BiGAN, có thể sử dụng hai phép phóng đại là lật theo chiều ngang và EMA.
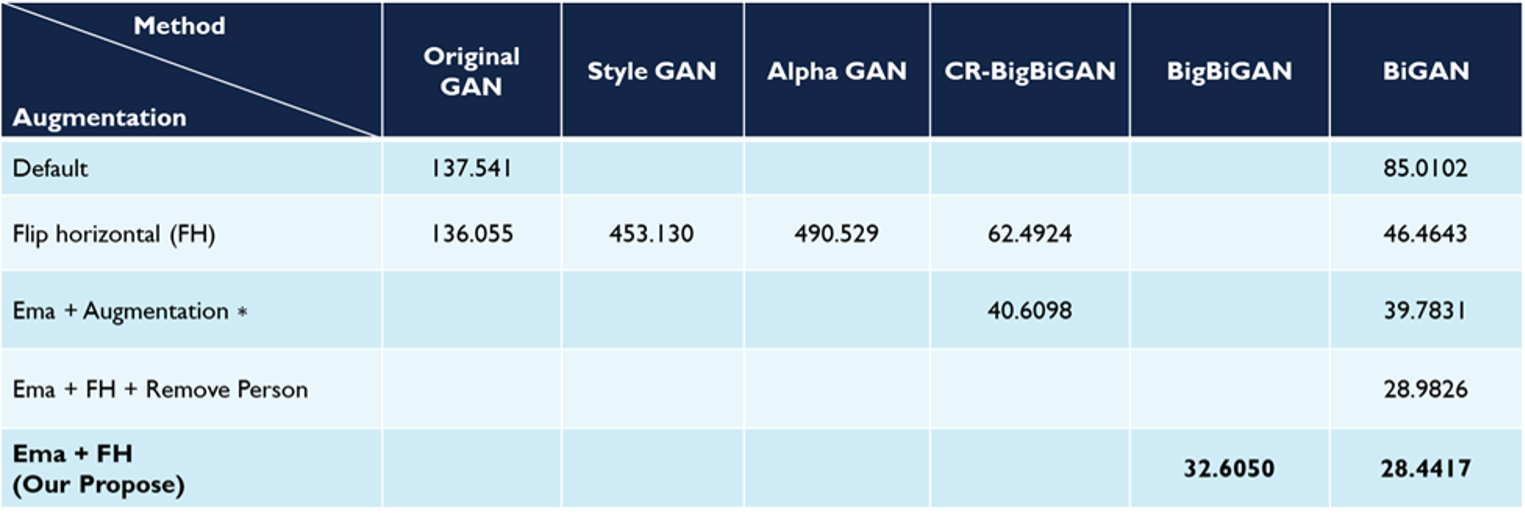
Bảng 1: Điểm FID của nhiều phương pháp khác nhau trên cùng một bộ dữ liệu xe máy
∗ Lật theo chiều ngang + Độ sắc (Sharpness) 2,0 + Độ sáng (Brightness) 0,8 + Độ tương phản (Contrast) 0,8
Với mỗi mô hình, tôi đã thực hiện huấn luyện trên hơn 200.000 phép lặp, và hình 2 sẽ biểu diễn các mẫu kết quả. Trông như thật, hai hình cuối của dòng 4 cho thấy phương pháp này có thể sinh ra một ảnh có hai xe máy. Ở dòng cuối cùng cho thấy kết quả sinh ảnh xe máy với nền như cây, rừng, núi, đất.

Hình 2: Một số xe máy được tổng hợp bởi mạng BiGAN của chúng tôi
Ứng dụng
Sau nhiều năm phát triển nhiều ứng dụng thú vị mới của BiGAN đã xuất hiện. Có thể kể đến một số use case hữu ích trong nhiều lĩnh vực như sau:
- Các bộ dữ liệu hình ảnh đóng một vai trò rất quan trọng trong việc huấn luyện mô hình. Kỹ thuật này đã được sử dụng thành công trong nhiều lần tổng hợp bộ dữ liệu hình ảnh khác. Ngày nay, dữ liệu là rất cần thiết. Các bài toán huấn luyện mô hình trong AI thường thiếu hoặc rất ít dữ liệu. Để giải quyết bài toán cần sinh ra nhiều dữ liệu. Bài toán này nhằm tạo ra nhiều dữ liệu hơn cho mục đích huấn luyện mô hình.
- Có thể tạo ra ảnh mới với độ phân giải được tăng cường tốt hơn. Giúp một hình ảnh được rõ nét hơn. GAN có thể dùng để tăng chất lượng của ảnh từ độ phân giải thấp lên độ phân giải cao với kết quả rất tốt
- Lĩnh vực an ninh: phát hiện dữ liệu giả như deepfake hay giúp bắt tội phạm, nhất là tội phạm ngụy trang hoặc tạo ra ảnh biến đổi theo nhóm tuổi giúp xác định khuôn mặt sau nhiều năm, tìm người dựa vào hình lúc trẻ.
- Lĩnh vực kinh doanh: thử sản phẩm trực tuyến. Ví dụ như thử quần áo khi shop có hình ảnh quần áo và bạn gửi thông tin về chiều cao, cân năng hoặc gửi ảnh hình dáng của bạn để thử đồ trực tuyến.
- Lĩnh vực giáo dục: dạy học trực tuyến với nhân vật đẹp và lịch sự hơn, background phù hợp hơn.
- Lĩnh vực giải trí: tạo ra những bản nhạc mới lạ hơn, những hình ảnh sinh động hơn.
Và danh sách ứng dụng vẫn còn rất dài…
Kết luận
Trên đây tôi đã sử dụng BiGAN với công dụng tổng hợp hình ảnh xe máy từ một bộ dữ liệu phức tạp. Trong đó, hai kỹ thuật chính được sử dụng để cải thiện điểm định lượng là kỹ thuật EMA và kỹ thuật Flip horizontal (lật theo chiều ngang). Các kết quả thử nghiệm Motorbike Generator đã chứng minh rằng, phương thức được đề xuất ở trên không chỉ giúp ổn định quá trình huấn luyện GAN mà còn đem lại các cải thiện rõ rệt.
Với kỹ thuật chuẩn hóa trọng số (weight normalization) lâu dài là Spectral Normalization (chuẩn hóa theo phổ), tôi dự định sẽ mở rộng thêm mạng GAN của mình thông qua:
- Thử nghiệm trên phương thức BiGAN bằng kỹ thuật Orthogonal Regularization (Chính quy hóa trực giao), Self Attention và Spectral Normalization
- Thử nghiệm trên phương thức BigBiGAN bằng kỹ Consistency Regularization (Chính quy hóa nhất quán), Self Attention và Spectral Normalization
Với công trình nghiên cứu này, tôi cũng đã xếp hạng 4 chung cuộc tại thử thách Motorbike Generator Challenge năm 2019. Một kỉ niệm rất đáng nhớ.

